What is Apache Hadoop Architecture?
Apache Hadoop follows a Master-Slave Architecture, Master node is responsible to assign the task to various slave nodes, it manages resources and maintains metadata while slave nodes are responsible to perform actual computation and store real data.
Apache Hadoop has the following three layers of Architecture.
1. Map-Reduce
2. YARN
3. HDFS
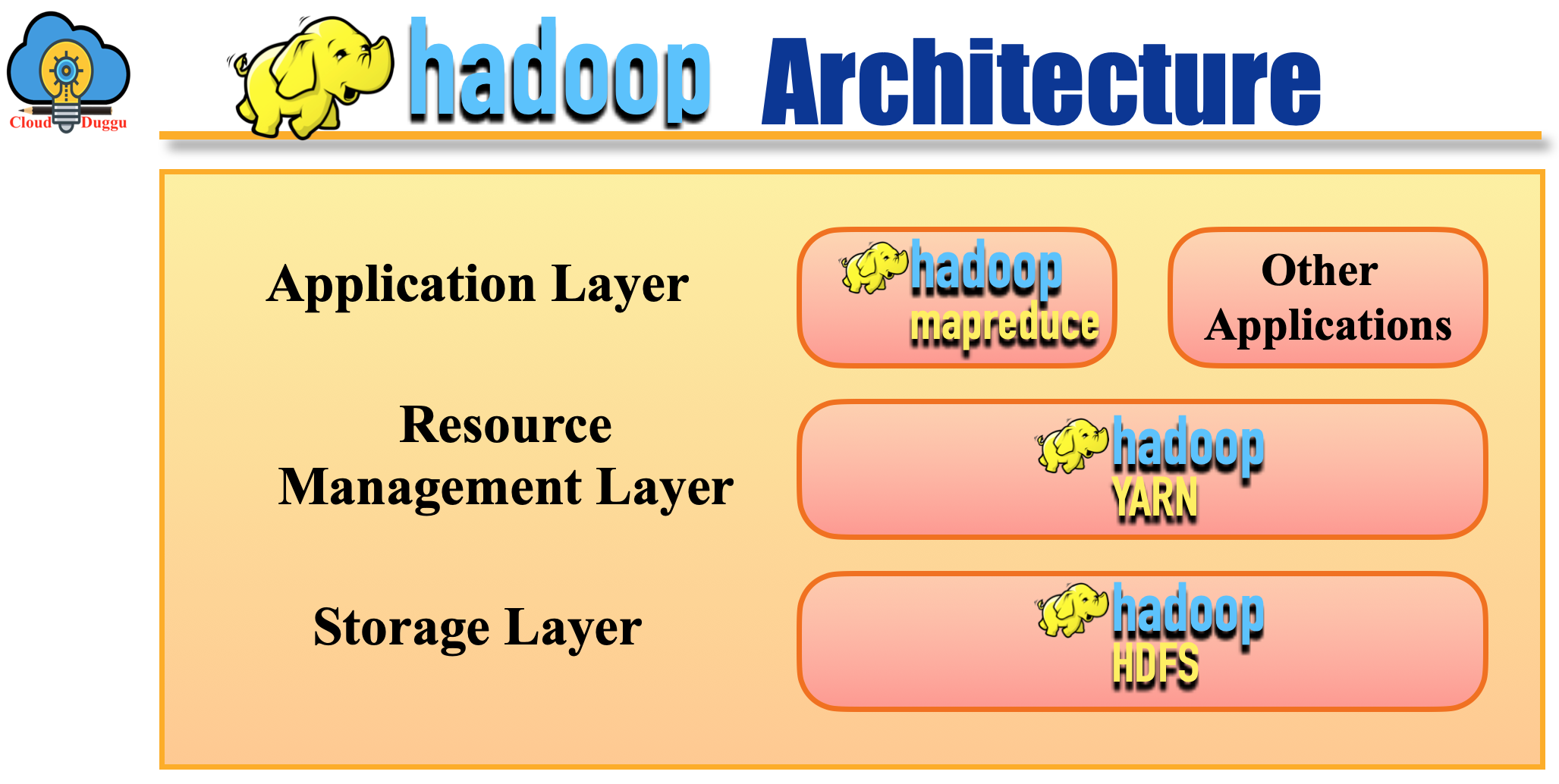
Let us understand each layer of Apache Hadoop in detail.
1. Map-Reduce
Map reduce is the data processing layer of Hadoop, It distributes the task into small pieces and assigns those pieces to many machines joined over a network and assembles all the events to form the last event dataset. The fundamental unit of information used by MapReduce is a key-value pair and it translates any type of data into key-value pair and then processes it. In the MapReduce Framework, the processing unit is moved to the data rather than moving the data to the processing unit.

MapReduce process data in two phases.
Map: In this phase user’s data is converted into a pair of Key and Value based on the business logic.
Reduce: Reduce phase takes input as the output generated by the map phase and applies aggregation based on the key-value pair.
Processing of Map-Reduce.
Mapper Phase
- The Mapper process is used to map the input key/value pairs into intermediate key/value pairs.
- Each Map is used to transform input records into an intermediate value. An input pair may map to zero or many outputs.
- The framework performs grouping of all intermediate values of an output key and sends it to Reducer for final output. The grouping can be controlled by users using a Comparator via Job.setGroupingComparatorClass(Class).
- The output of the Mapper is sorted and partitioned based on Reducer. After this activity, the number of partitions is the same as the reducer task.
Reducer Phase
In the Reducer phase, a set of intermediate values have reduced that share a key to a smaller set of values.
It has three primary phases.
- Shuffle
- Short
- Reduce
In the shuffling phase, the Hadoop framework takes applicable partition of the output of all the mappers, via HTTP.
In the short stage, the Hadoop framework performs grouping of Reducer input by keys, and sorting and shuffling also happened concurrently.
This is the final stage in which (WritableComparable, Iterable, Context) method is used for each pair of grouped inputs and the output of Reduce task is written on file using Context.write(WritableComparable, Writable).
2. YARN
YARN stands for “Yet Another Resource Negotiator” which is the Resource Management level of the Hadoop Cluster. It is used to perform job scheduling and resource management in the Hadoop framework. The basic idea of YARN is to divide the resource management and job scheduling into different processes and perform the operation.
YARN framework has two daemons namely Resource Manager and Node Manager. Both components are used to process data-computation in YARN. The Resource Manager runs on the master node of the Hadoop cluster and arbitrates resources in all applications whereas the Node Manager is hosted on all Slave nodes. The responsibility of the Node Manager is to monitor the containers, resource usage such as (CPU, memory, disk, and network) and provide detail to the Resource Manager.
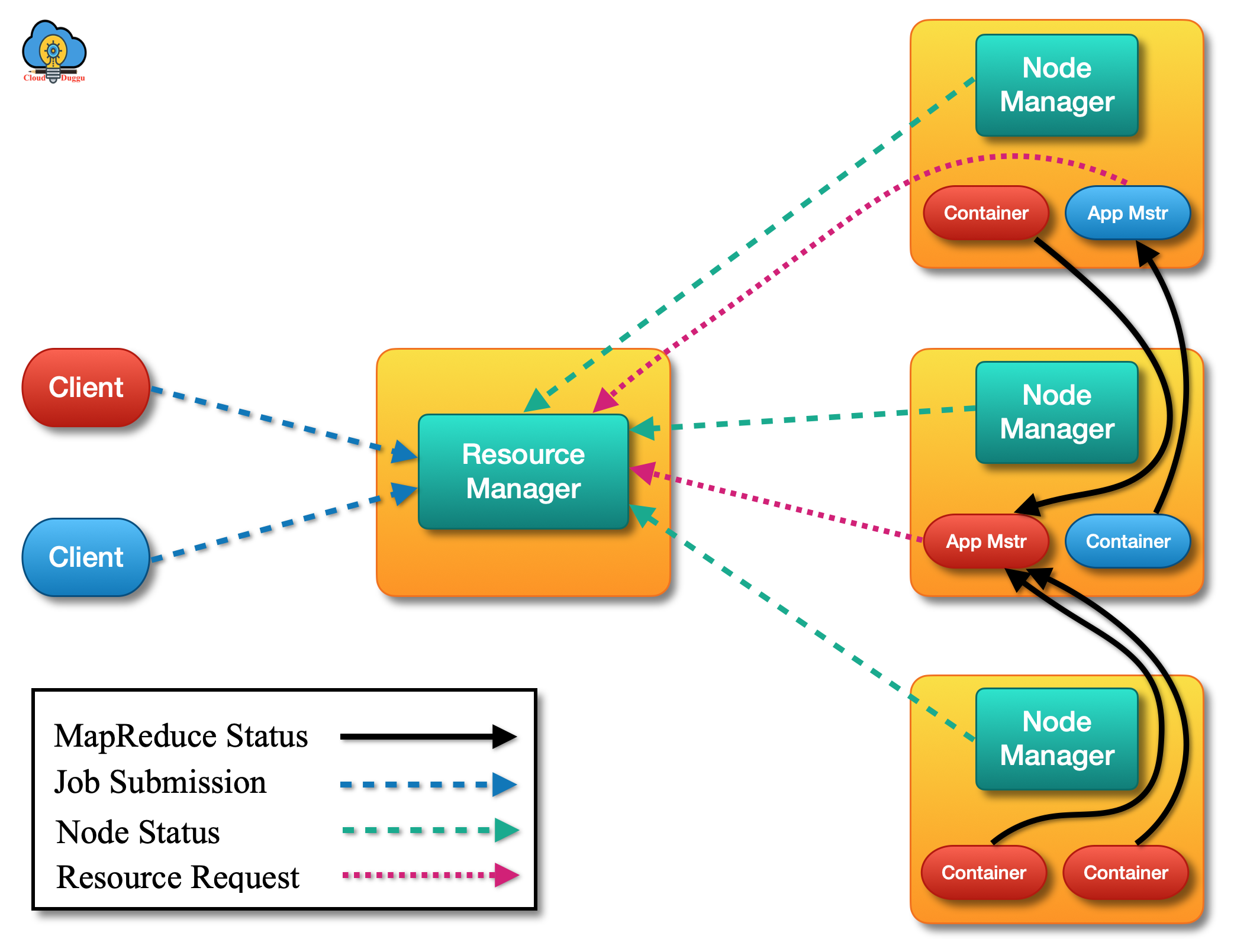
The following are the two components of YARN.
Resource Manager
- The resource manager runs on the Mater node of the Hadoop Cluster.
- The resource manager handles the resource-scheduling part.
- It also runs application manager
- It keeps track of all node managers.
Node Manager
- The node manager runs on the slave machines.
- The node manager handles the containers (Resource capacity of Node manager).
- The node manager monitors the resource consumption of each container.
- The node manager keeps sending a heartbeat to the Resource manager.
The Resource Manager has the following two main components: Scheduler and Applications Manager.
Scheduler
The responsibility of the Scheduler is to allocate the system resources to the running application jobs. It performs the scheduling part only, it does not perform any monitoring or tracking of any application jobs. It also does not restart any job which failed due to application failure or hardware failure. It performs the scheduling part based on the resources needed by application jobs.
Applications Manager
The responsibility of the Application manager is to accept the job submitted from the client and assigning the first container to execute the application Master. It also provides a service to restart the Application Master in case of failures. The Application manager is responsible to arrange the resource containers from the Scheduler and keep tracking and monitoring the process.
3. HDFS
HDFS stands for Hadoop Distributed File System. It is the Hadoop file system and one of the core components in the Hadoop cluster. It is designed in such a way that it can easily run on commodity hardware. HDFS is very similar to the existing file system. HDFS provides fault-tolerant and it can store very large datasets.
HDFS architecture has Master and Slave nodes. Master Node runs Name node daemons and Slave Node runs the Data Node daemons.
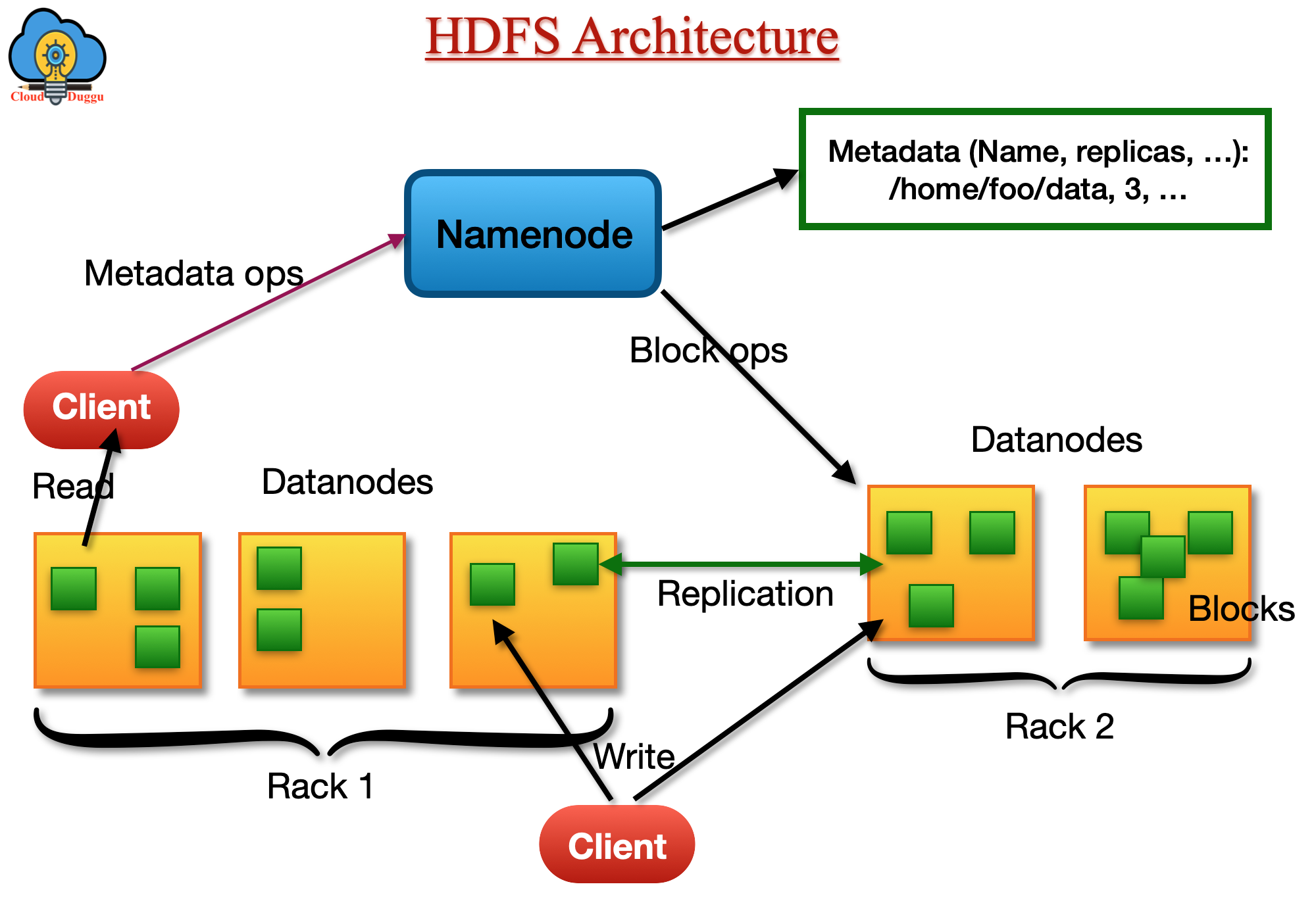
NameNode and DataNodes
Hadoop HDFS cluster has one Namenode that is also called a Master Server and multiple Datanodes. The Master server manages the file system namespace and controls the file access by clients such as open, close, or renaming the file or directories whereas the Datanodes manage the storage part. Apart from the Name node, every other node has Datanode in the Hadoop cluster. When a user saves data in HDFS then it divides into one or multiple blocks and these blocks are stored in Datanodes. The Datanodes receive instruction from Namenode and perform an action such as block creation, deletion, replication, and so on.
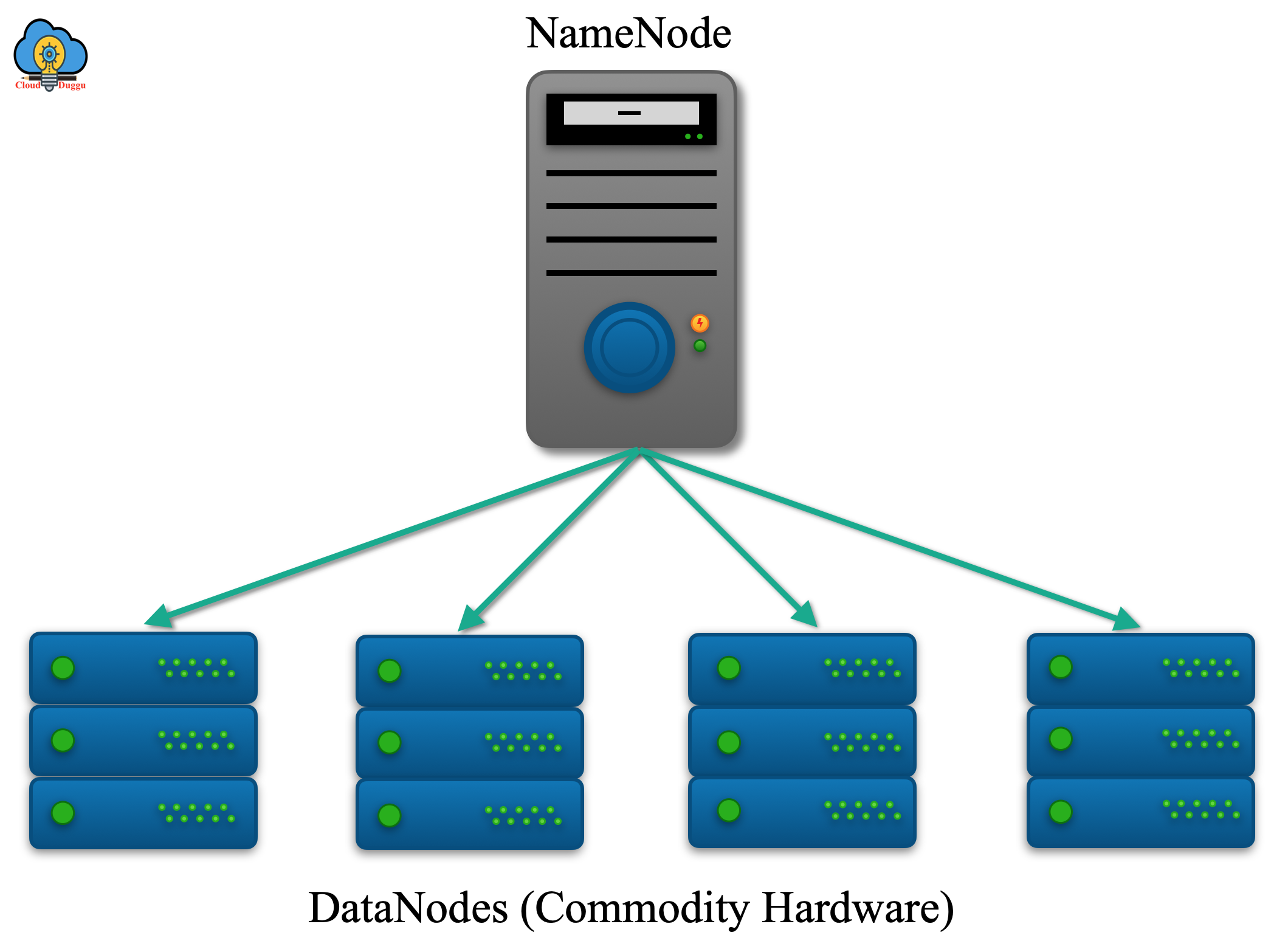
Data Replication
HDFS data replication plays an important role to replicate data across multiple nodes. It can be configured based on the replication parameter (dfs. Replication) present in the hdfs-site.xml file. The replication feature of HDFS provides reliable storage for large files. HDFS stores every file in a sequence of blocks. The block size of the file will be the same except for the last block.

HDFS Block
A block is the basic representation of storage in which a file is stored. HDFS has used to store very large files. It is suitable for those applications which have a very large data set and they perform writing of this data set once and read multiple times. HDFS supports write once and read many time semantics for the files. The idle block size used in HDFS is 128 MB. So if a user is putting a large file in HDFS then it will be divided into 128 MB chunks and stored into different DataNodes.
Let’s take an example of the “example.txt” file which has 512 MB of size. If we go with the default configuration of HDFS then there would be 5 blocks created for this file. The initial blocks would be 128 MB and the last blocked would be 2 MB.
Now the question here is why should we create such a huge block size?
The Hadoop HDFS is developed to store large files that come in Terabytes or Petabytes and if a user is storing small-size files then it will create overhead to the Hadoop framework to manage the metadata to those files. So it is recommended to store large files in HDFS.
