readers ... are you ready to create an Apache Hadoop project. (-SalesCount-)
1. Idea Of Project
| a. Fetch the raw data from the client system. |  |
| b. Process raw data in the Hadoop system. |  |
| c. Push calculated data to the client system. |  |
| d. Show calculated data in graph trends. |  |
2. Building Of Project
To run this project you can install VM (Virtual Machine) on your local system and configured Hadoop on that. After this configuration, your local system will work as a client system and Hadoop VM will work as a Hadoop system. Alternative you can take two systems which are communicating with each other and on one of the system Hadoop is configured.
Let us see this project in detail and run it using the below steps.
| a. The Client System | ||
|---|---|---|
| It is an example of the Spring Boot JAVA Framework. When we will build this project then it will create a "client.jar" executable file. |  |
|
| It has java code, data files, and static HTML pages. | ||
| Java code has 2 files, SpringBootWebApplication.java and UploadDownloadController.java | ||
| SpringBootWebApplication.java is the main project files, which is responsible for building code and running it on an embedded server. | ||
| UploadDownloadController.java is used to provide download & upload URL HTTP services. For downloading data files it uses the download client URL and for uploading result file it uses the upload client URL. | ||
| data folder has unprocessed sales CSV log files. (data_01.csv, data_02.csv, data_03.csv ...) | ||
| The Static folder has chart HTML page code (index.html) and dependent js files (chart.min.js, utils.js). This is the main client view page which shows the Hadoop process code result. | ||
| pom.xml is a project build tool file. This file has java dependencies and builds configuration details. | ||
| For creating the “client.jar” file we use the command "mvn clean package". | ||
| Click Here To Download "ClientSaleCode" project zip file. | ||
| b. Apache Hadoop System | ||
|---|---|---|
| It is a JAVA project, when we will build this project then it will create a “sales.jar “executable file. |  |
|
| Hadoop project has 3 java files (SalesDriver.java, SalesMapper.java, SalesReducer.java) and 1 build tool file (pom.xml). | ||
| SalesDriver.java, here a job object is created, and post the MapReduce object gets set in that. Also, we add key-value data type for map and output attributes. The job will also contain an input-output folder path. | ||
| SalesMapper.java, in this class, we collect data line by line and split every line using specified delimiters. After that, we filter data based on condition and then collect filtered data and write in an application context object. | ||
| SalesReducer.java, in this class, we collect mapper output data and process it. After processing it will write as a final output in the application context. | ||
| pom.xml contains external code dependencies and main class details. | ||
| For creating a sales jar file use command > mvn clean package | ||
| Click Here To Download "SalesDataAnalysis" project zip file. | ||
3. Run The Project
| a. Client System | b. Hadoop System | |
|---|---|---|
| 1. | Download client.jar in the client system. Click Here To Download the "client.jar" executable jar file. |
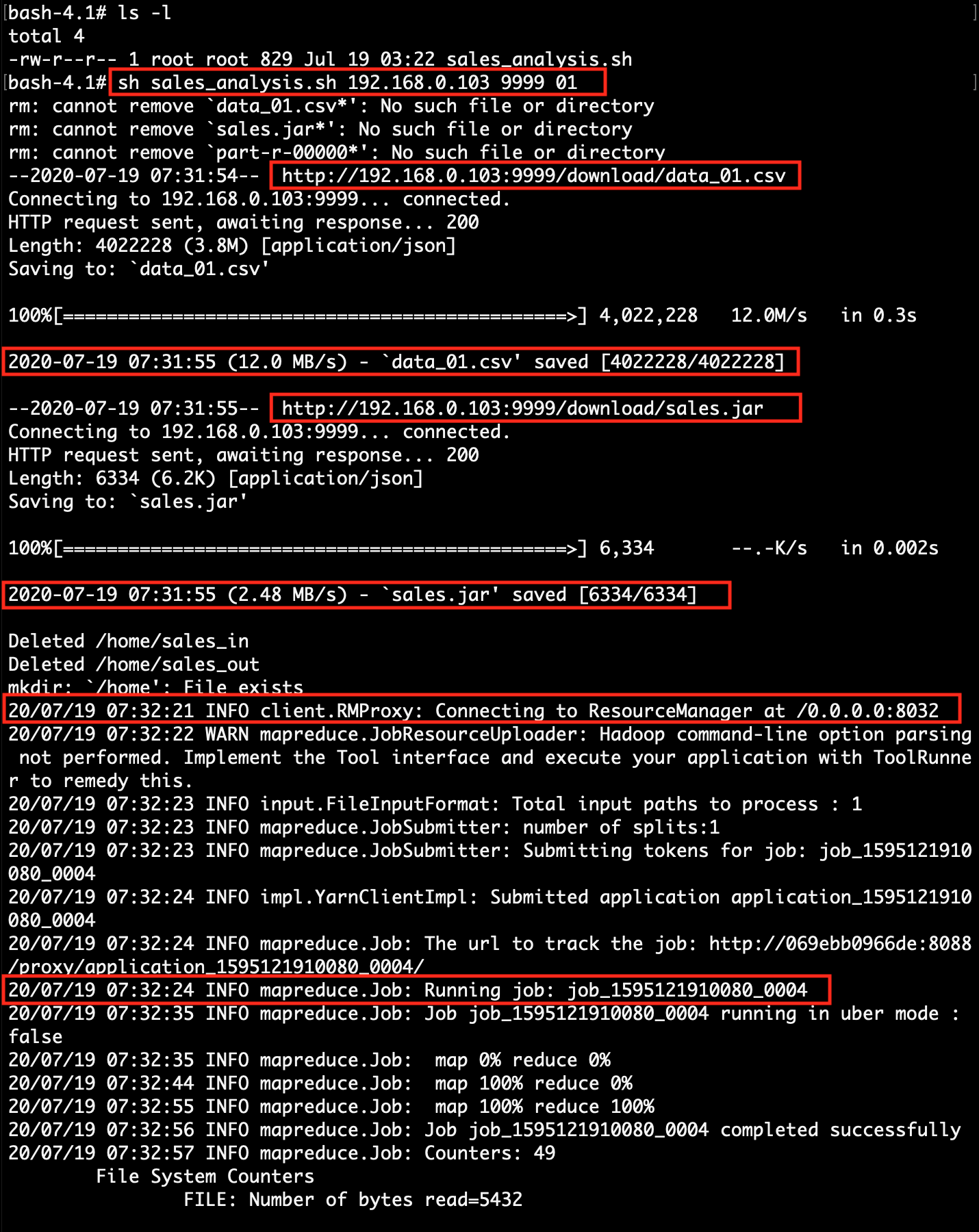
Download sales_analysis.sh shell script file in the Hadoop system. Click Here To Download the "sales_analysis.sh" shell script file. |
 |
 |
|
| 2. | Run client.jar in the client system. At execution time pass server port 9999. Here we can use a different port if the port already uses in the client system. |
|
 |
||
 |
||
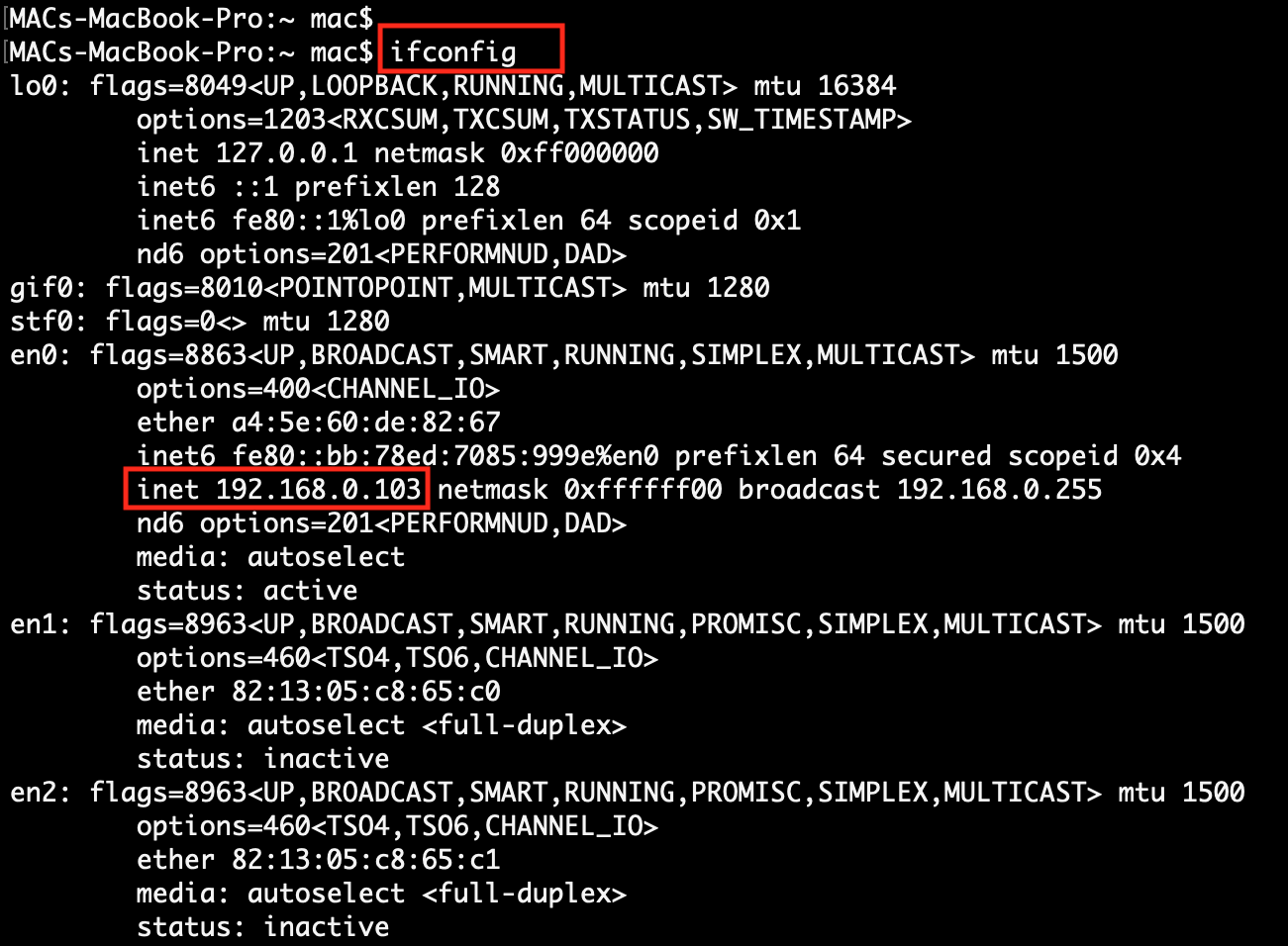
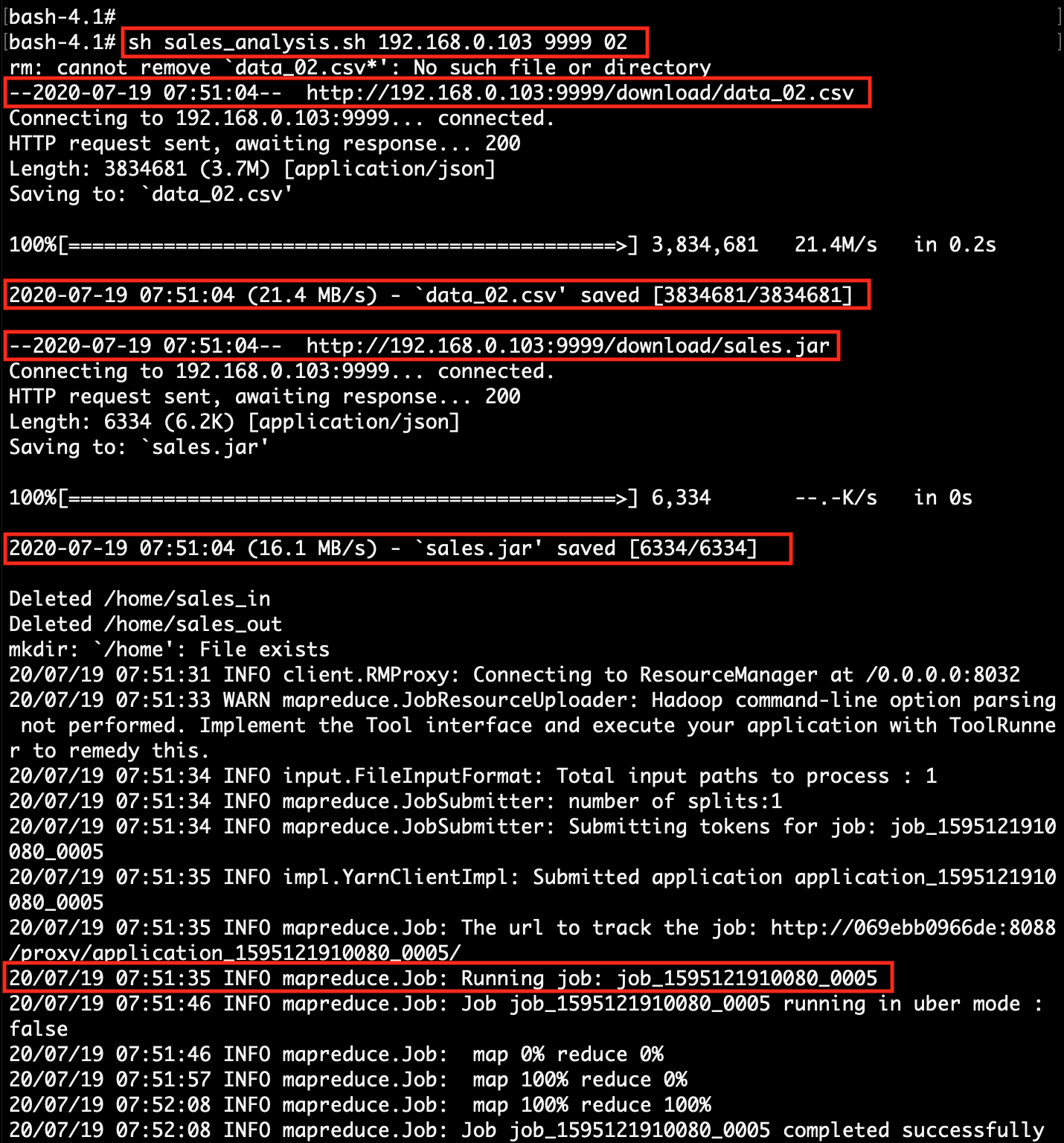
| 3. | Find client system IP, which will be accessible to the Hadoop system. | Run sales_analysis.sh shell script in the Hadoop system. At execution time pass client-ip, client-port & data_file_number. |
 |
 |
|
 |
 |
|
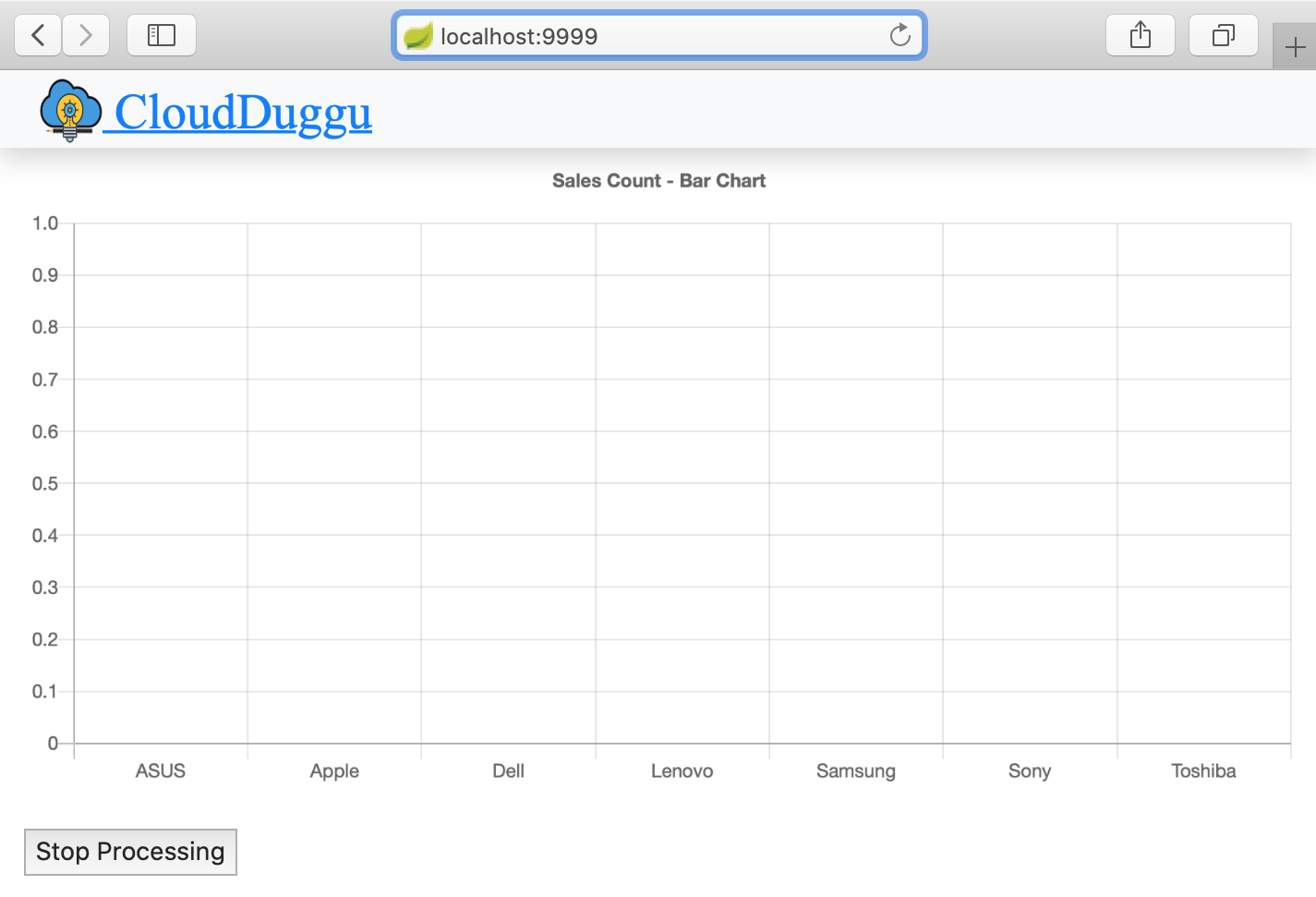
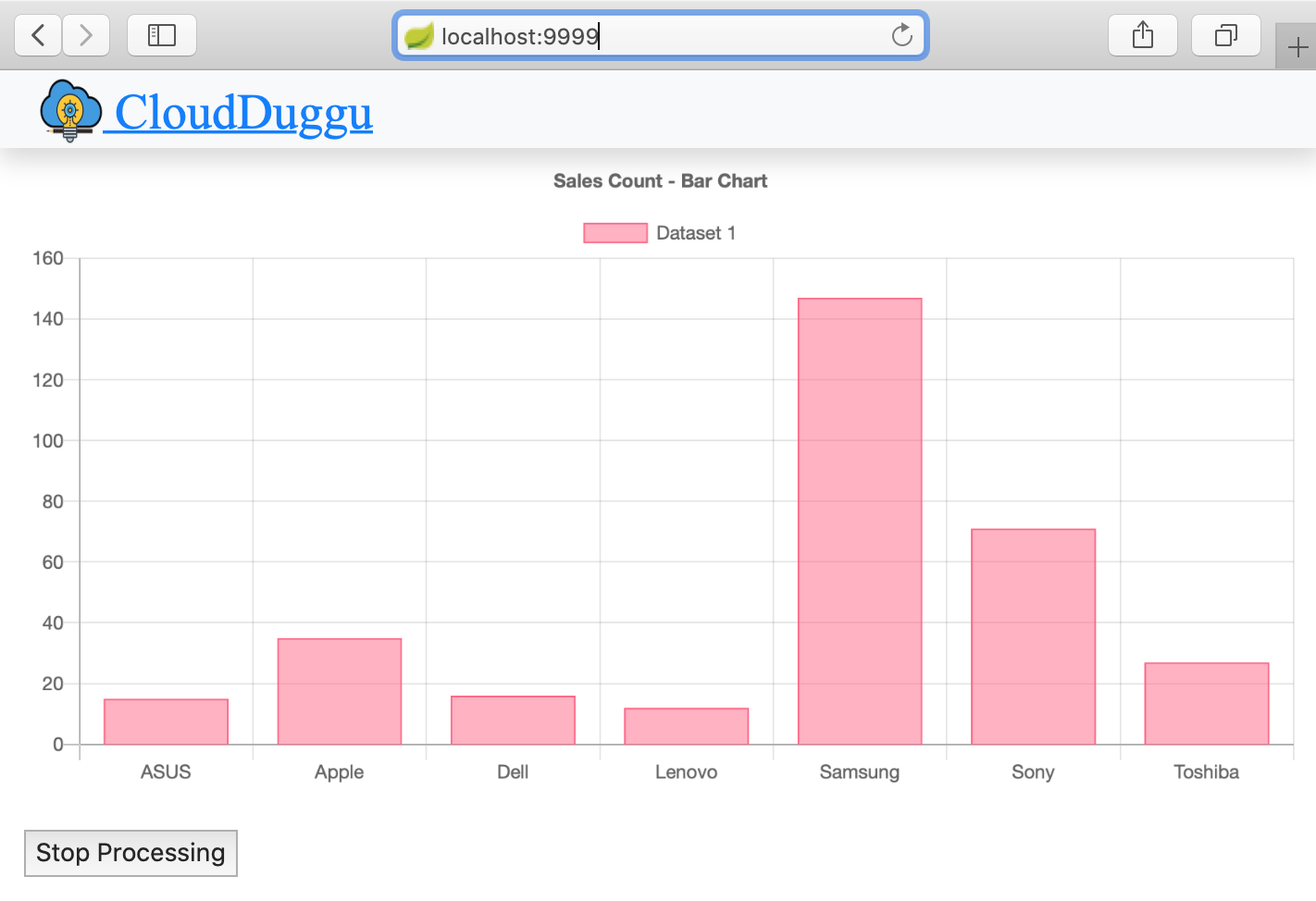
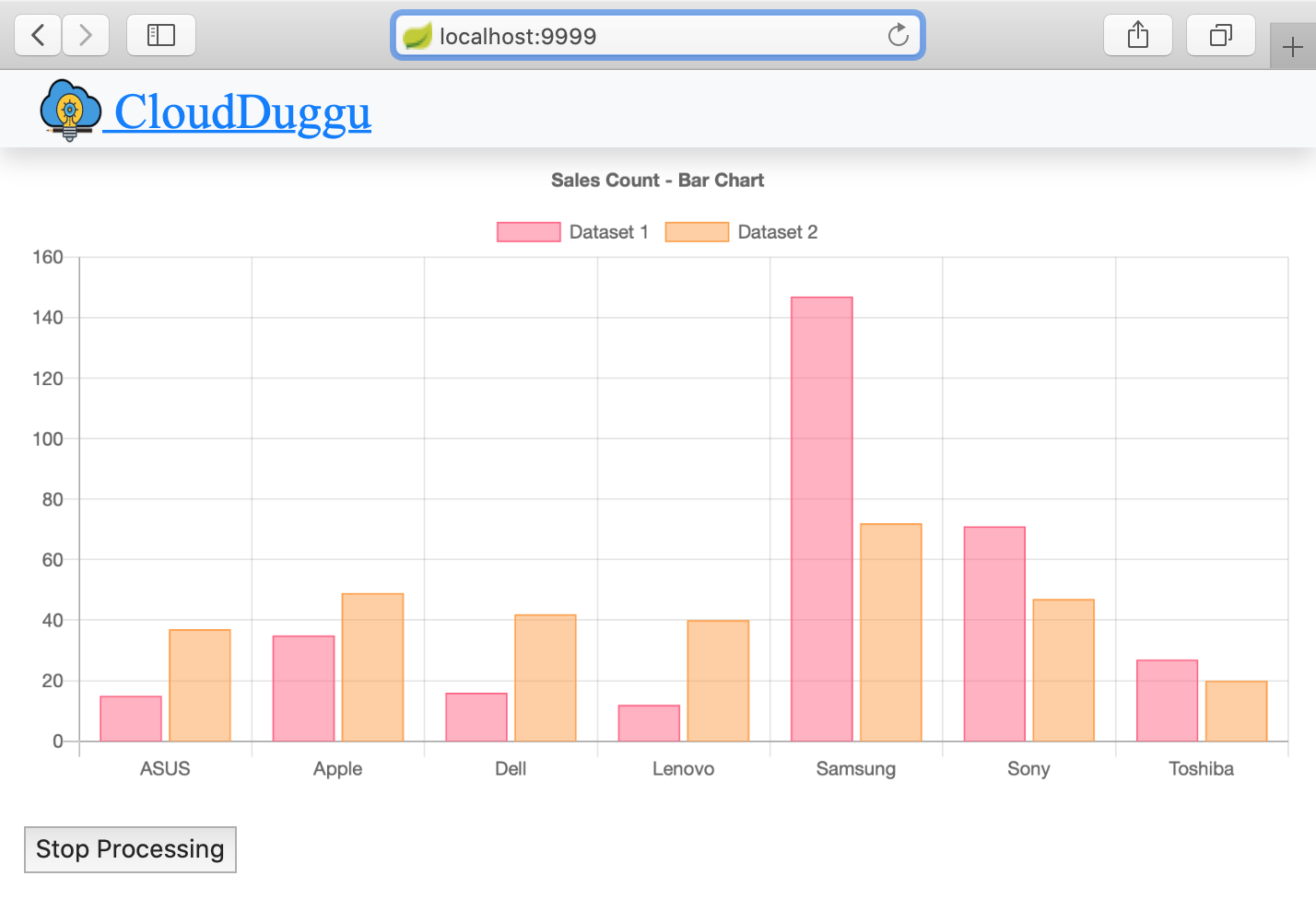
| 4. | The client page will automatically show the next result in the bar chart, after processing the next data_file in Hadoop. | Run sales_analysis.sh shell script file in the Hadoop system for next data_file_number (02). |
 |
 |
|
| 5. | The client system will automatically show the results in the Bar chart as the Hadoop system will process the next files. | Run sales_analysis.sh shell script file in the Hadoop system for next data_file_numbers. |
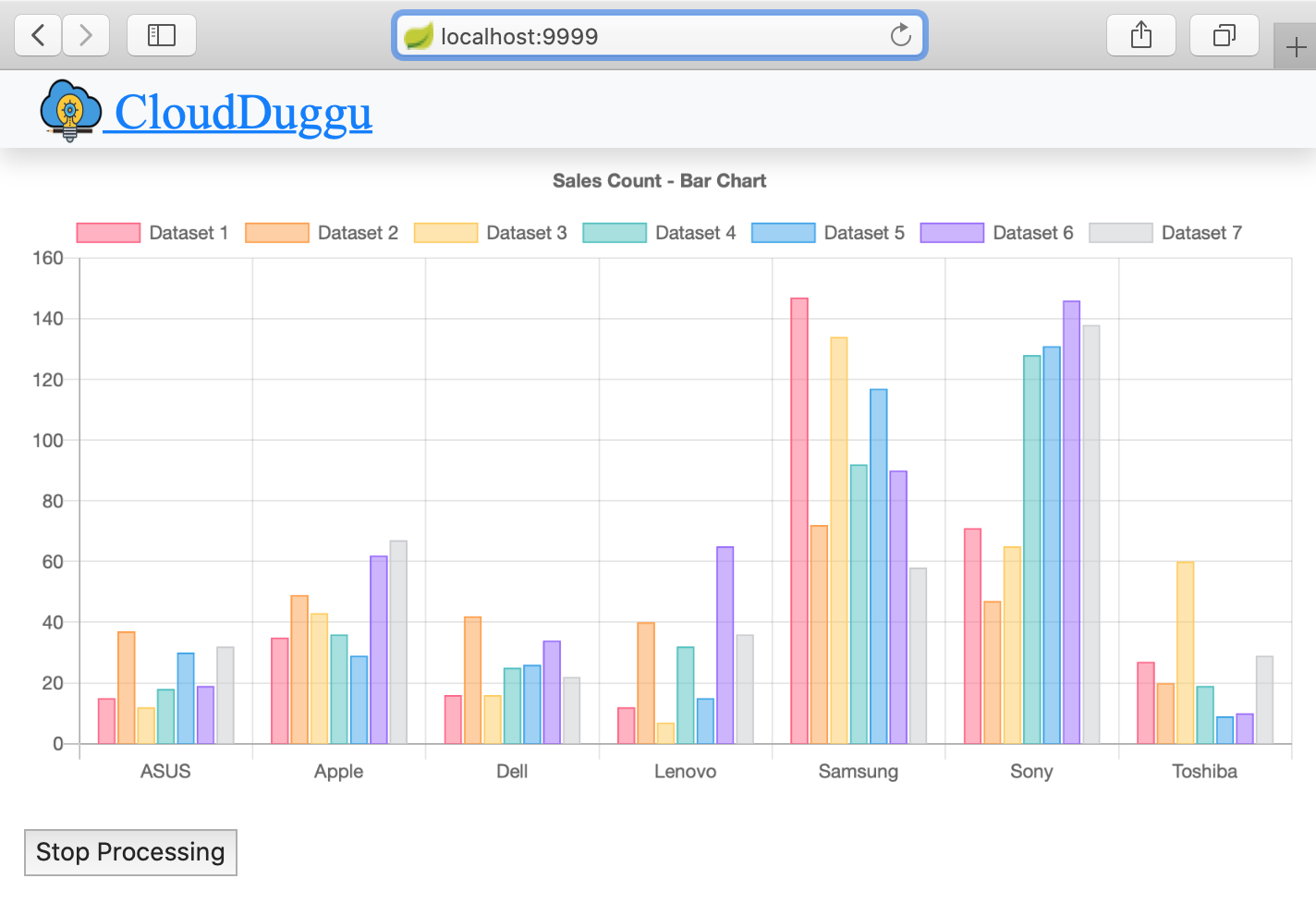 |
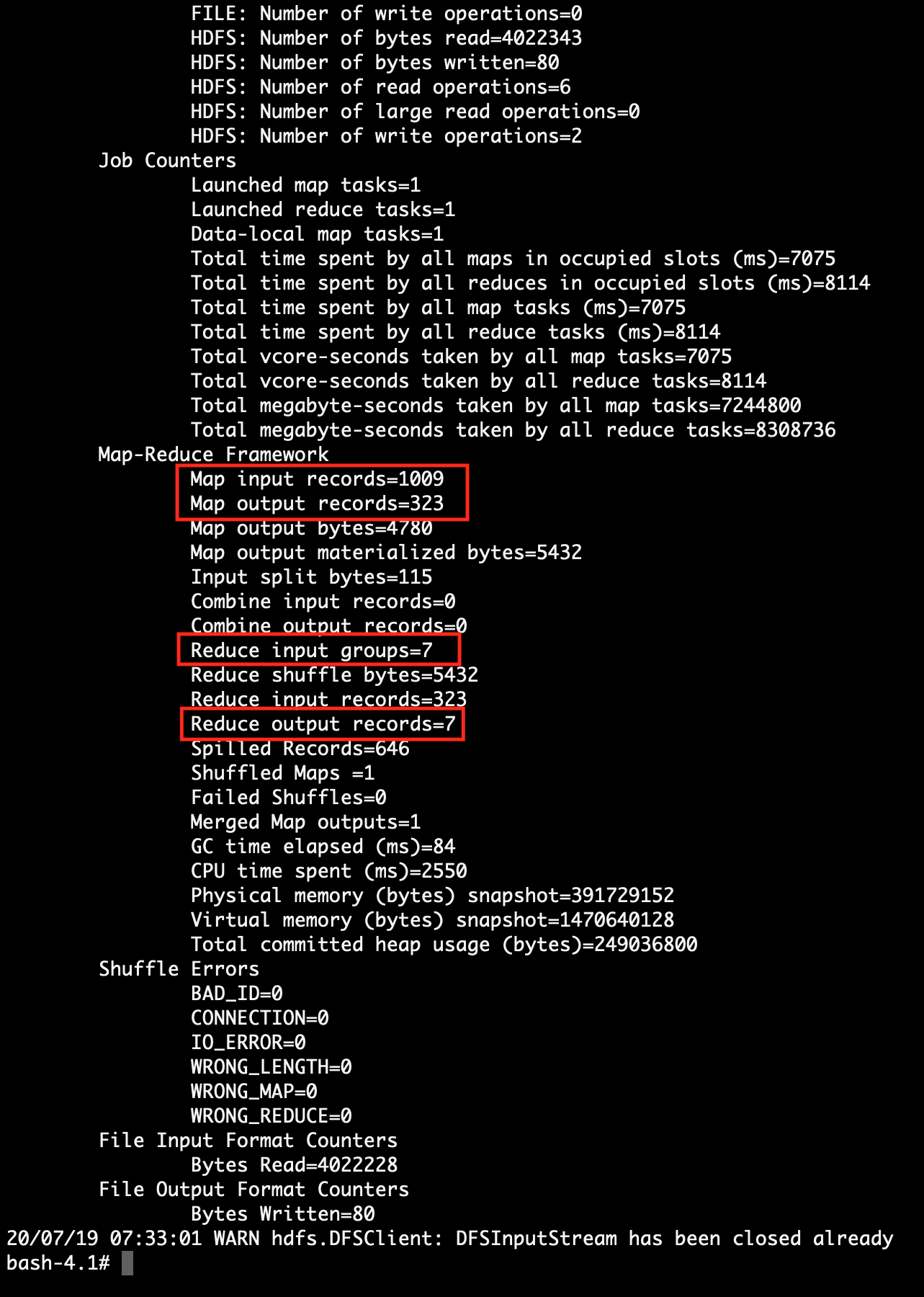
bash-4.1# sh sales_analysis.sh 192.168.0.103 9999 03 . . . bash-4.1# sh sales_analysis.sh 192.168.0.103 9999 04 . . . bash-4.1# sh sales_analysis.sh 192.168.0.103 9999 05 . . . bash-4.1# sh sales_analysis.sh 192.168.0.103 9999 06 . . . bash-4.1# sh sales_analysis.sh 192.168.0.103 9999 07 . . . |
4. Project Files Description In Details
(i). sales_analysis.sh
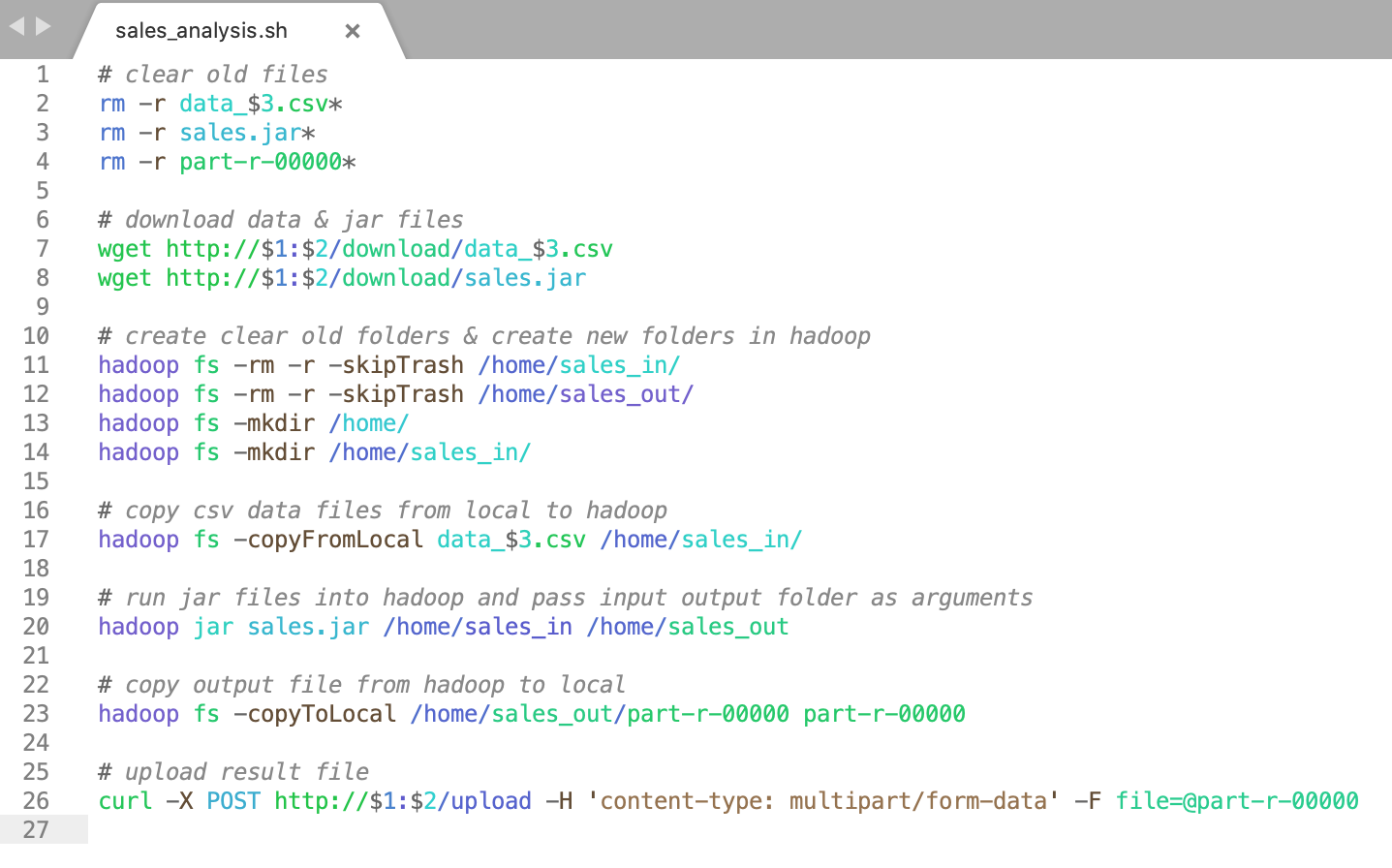
Using a shell script (sales_analysis.sh) we can easily run the Hadoop project jar in the Hadoop system.
sales_analysis.sh file has three variables that pass at runtime.
The first variable is $1, used to obtain the client IP address from the command line.
The Second variable is $2, used to obtain the client port number from the command line.
The third variable is $3, used to obtain the data file number from the command line.
(sh sales_analysis.sh 192.168.0.103 9999 01): here "sh" is Linux command,
"sales_analysis.sh" is a shell script file name, "192.168.0.103" is a first variable, "9999" is a second variable,
"01" is the third variable.
:) ...enjoy the Hadoop project.