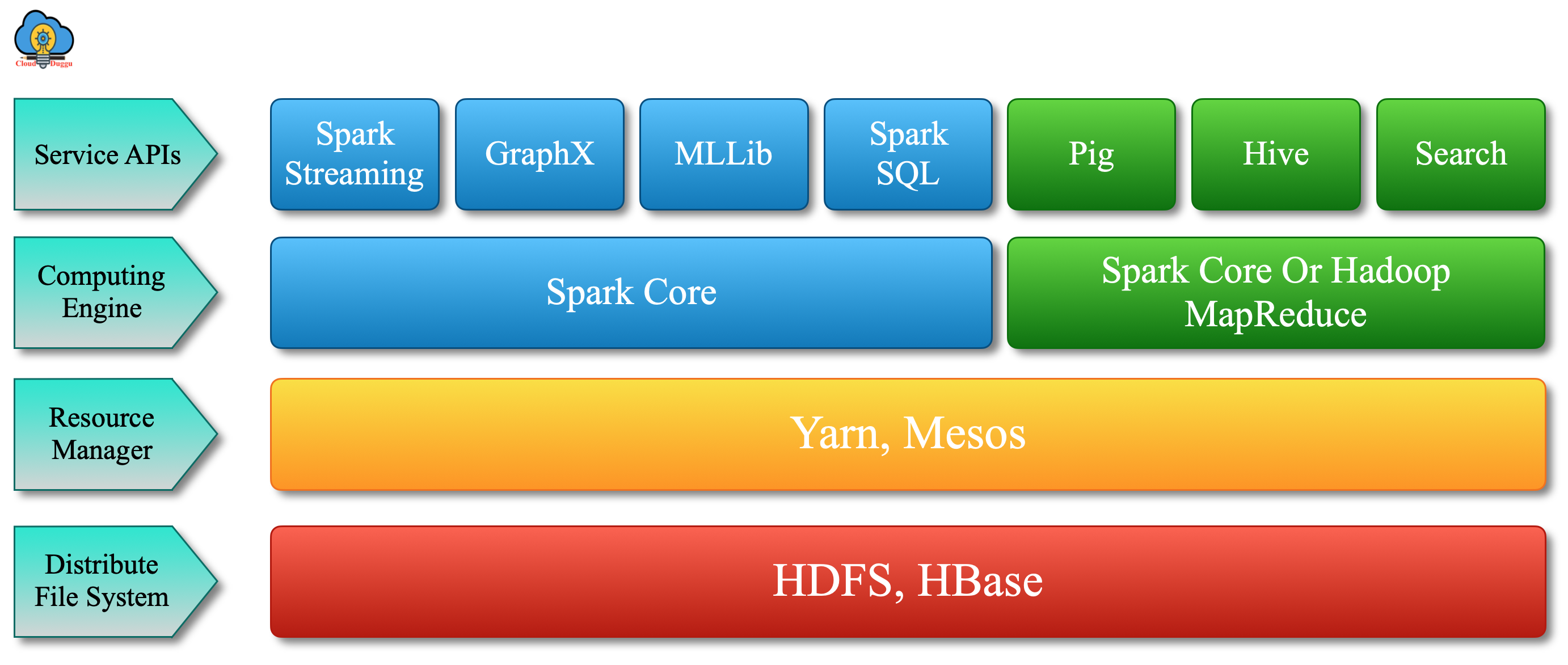
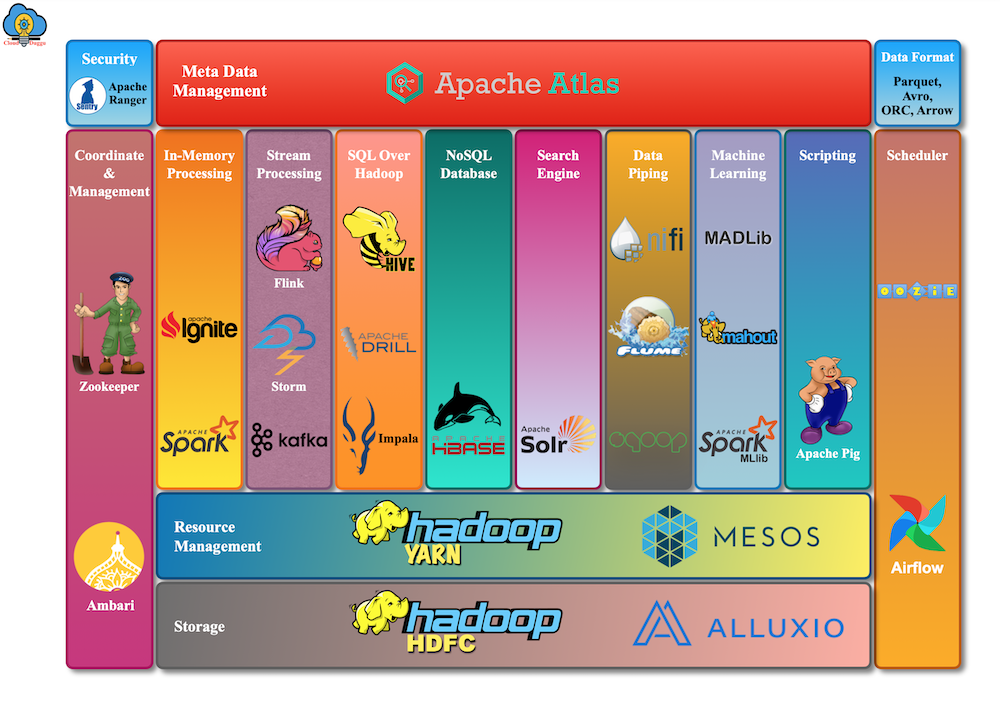
Components of Apache Hadoop
Apache Hadoop ecosystem is the set of services, which can be used at a different level of big data processing and use by many organizations to solve big data problems. HDFS and HBase are used to store data, Spark and MapReduce are used to process data, Flume and Sqoop are used to ingest data, Pig, Hive, and Impala are used to analyze data, Hue and Cloudera Search help to explore data. Oozie manages the workflow of Hadoop jobs and so on.
Let’s have a look at the Apache Hadoop Ecosystem.
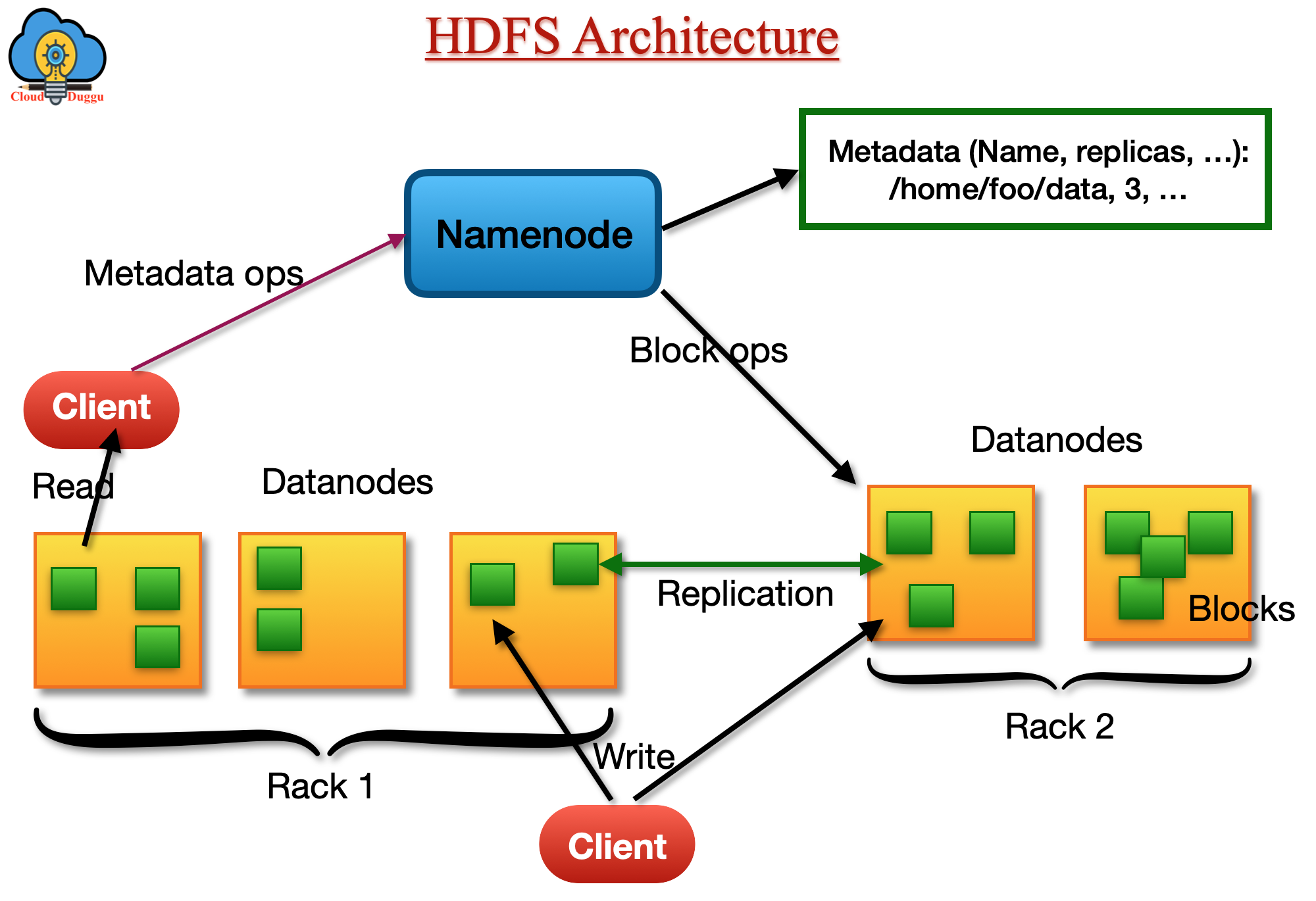
1. HDFS (Hadoop Distributed File System)
The Apache Hadoop HDFS is the distributed file system of Hadoop that is designed to store large files on cheap hardware. It is highly fault-tolerant and provides high throughput to applications. HDFS is best suited for those applications which are having very large data sets.
The Hadoop HDFS file system provides Master and Slave architecture. The Master node runs Name node daemons and Slave nodes run Datanode daemons.
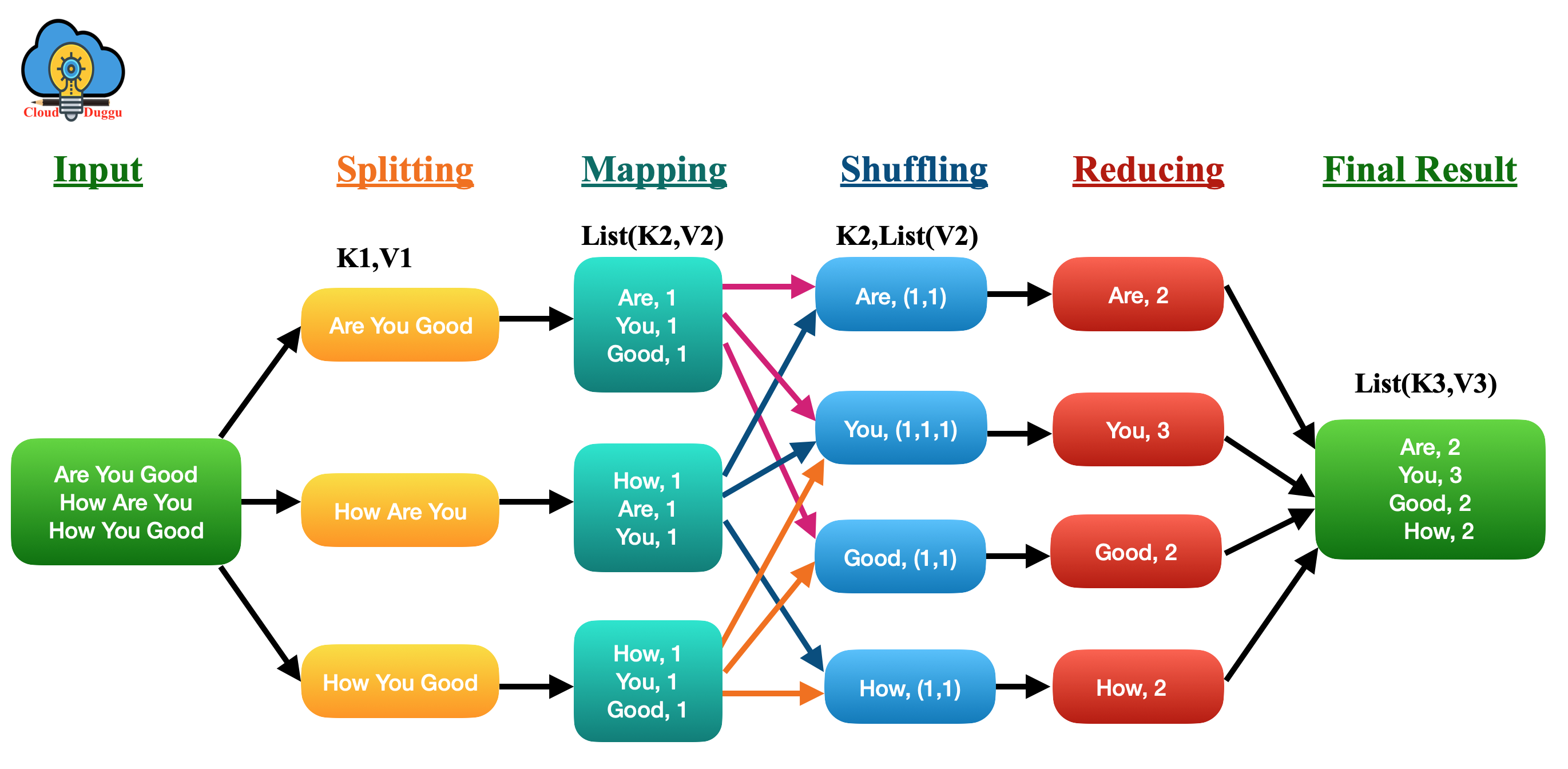
2. Map-Reduce
Map-Reduce is the data processing layer of Hadoop, It distributes the task into small pieces and assigns those pieces to many machines joined over a network, and assembles all the events to form the last event dataset. The basic detail required by Map-Reduce is a key-value pair. All the data, whether structured or not, needs to be translated to the key-value pair before it is passed through the Map-Reduce model. In the Map-Reduce Framework, the processing unit is moved to the data rather than moving the data to the processing unit.
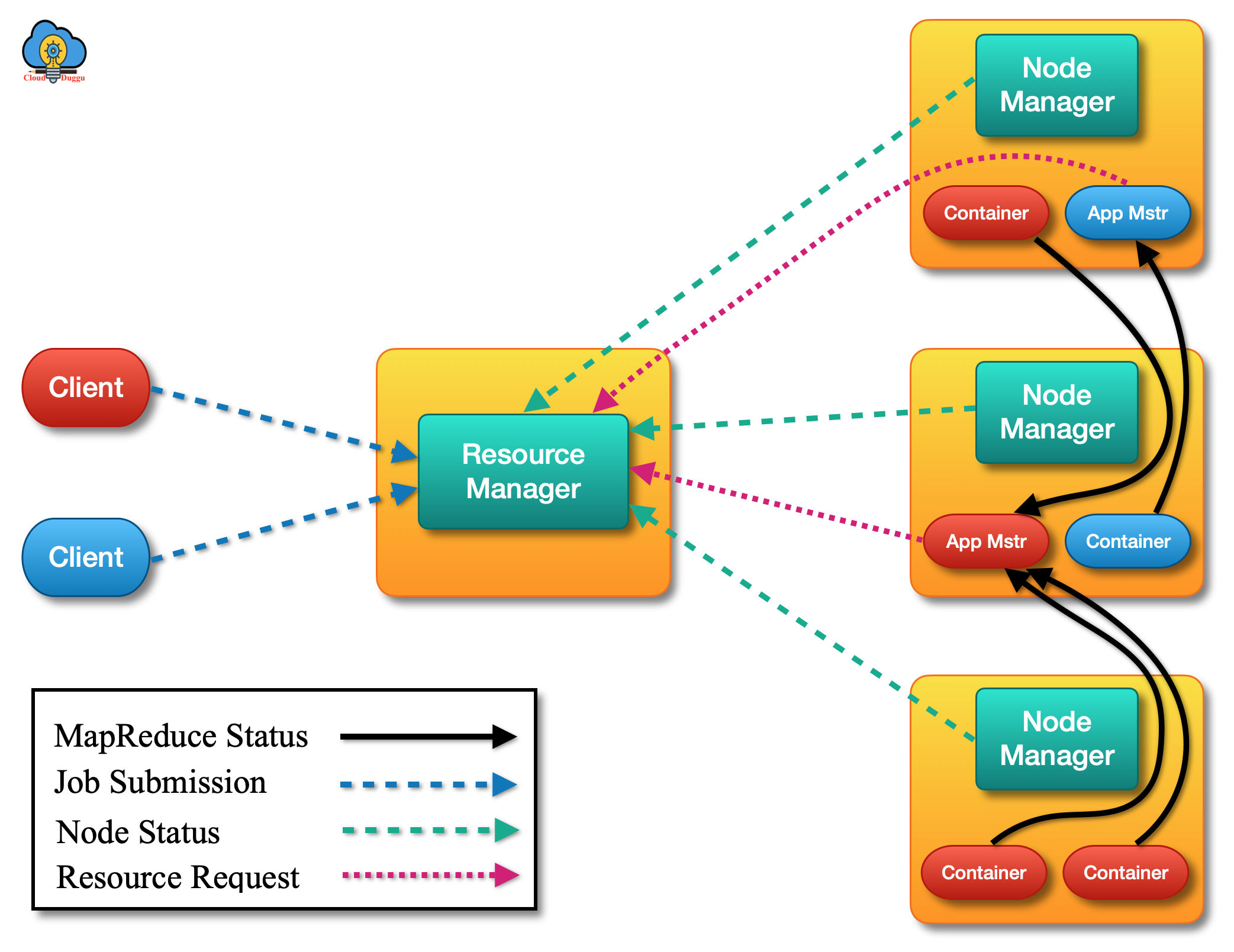
3. YARN
YARN stands for “Yet Another Resource Negotiator” which is the Resource Management level of the Hadoop Cluster. YARN is used to implement resource management and job scheduling in the Hadoop cluster. The primary idea of YARN is to split the job scheduling and resource management into various processes and make the operation.
YARN gives two daemons; the first one is called Resource Manager and the seconds one is called Node Manager. Both components are used to process data-computation in YARN. The Resource Manager runs on the master node of the Hadoop cluster and negotiates resources in all applications whereas the Node Manager is hosted on all Slave nodes. The responsibility of the Node Manager is to monitor the containers, resource usage such as (CPU, memory, disk, and network) and provide detail to the Resource Manager.
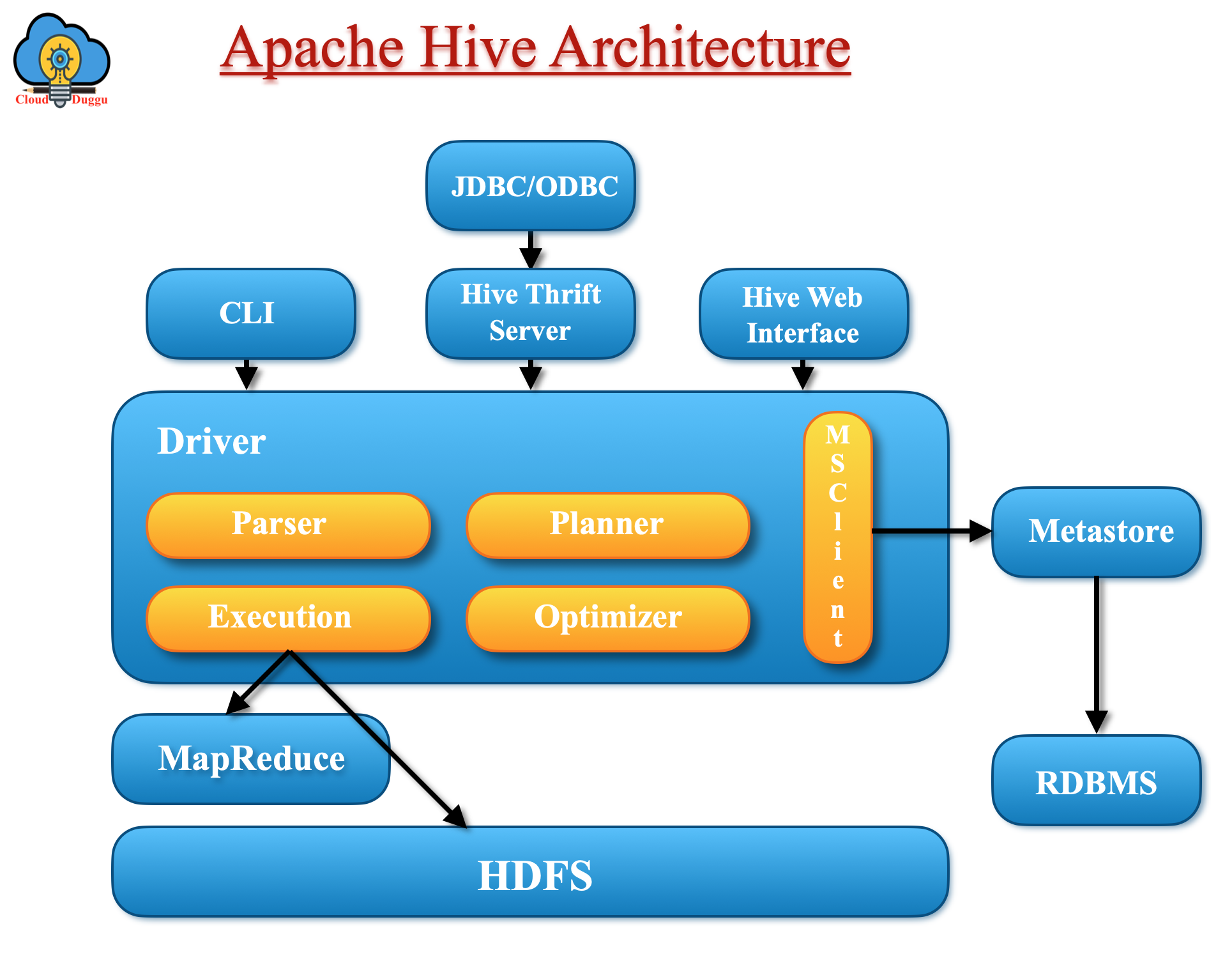
4. Apache Hive
Apache Hive is a data-warehousing project of Hadoop. Hive is intended to facilitate informal data summarization, ad-hoc querying, and interpretation of large volumes of data. With the help of HiveQL, a user can perform ad-hoc queries on the dataset store in HDFS and use that data to do further analysis. Hive also supports custom user-defined functions that can be used by users to perform custom analysis.
Let us understand how Apache Hive processes the SQL query.
- Users will submit a query using the command line or Web UI to the driver (Such as ODBC/JDBC).
- The driver program will take help from the query compiler that parses the query to check the syntax/query plan.
- The compiler will send metadata requests to the metadata database.
- In response, Metastore will provide metadata to the compiler.
- Now the task of the compiler is to verify the specification and resend the plan to the driver.
- Now the driver will send an execution plan to the execution engine.
- The program will be executed as a map-reduce job. The execution engine will send the job to the name node job tracker and it assigns this job a task tracker that is present in the data node and here query will be executed.
- Post query execution, the execution engine will receive the result from the data node.
- The execution engine will send the result value to the driver.
- The driver will send the result to the Hive interface (User).
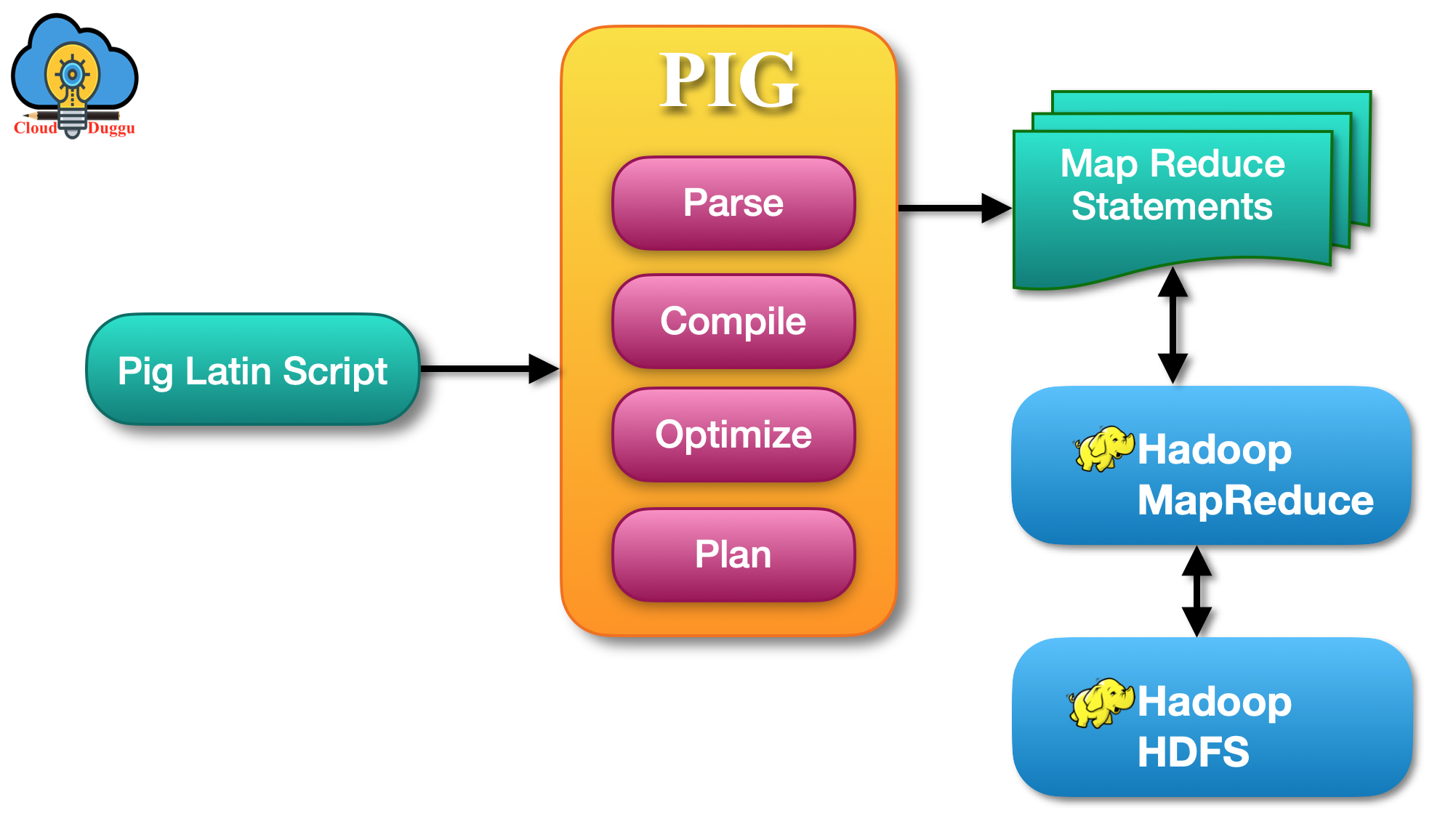
5. Apache Pig
Apache Pig was developed by Yahoo to analyze large data stored in Hadoop HDFS. Pig provides a platform to analyze massive data sets that consists of a high-level language for communicating data analysis applications, linked with infrastructure for assessing these programs.
Apache Pig has the following key properties.
Optimization Opportunities
Apache Pig provides the optimization of the query that helps users to concentrate on meaning rather than efficiency.
Extensibility
Apache Pig provides functionality to create User-defined functions to produce special-purpose processing.
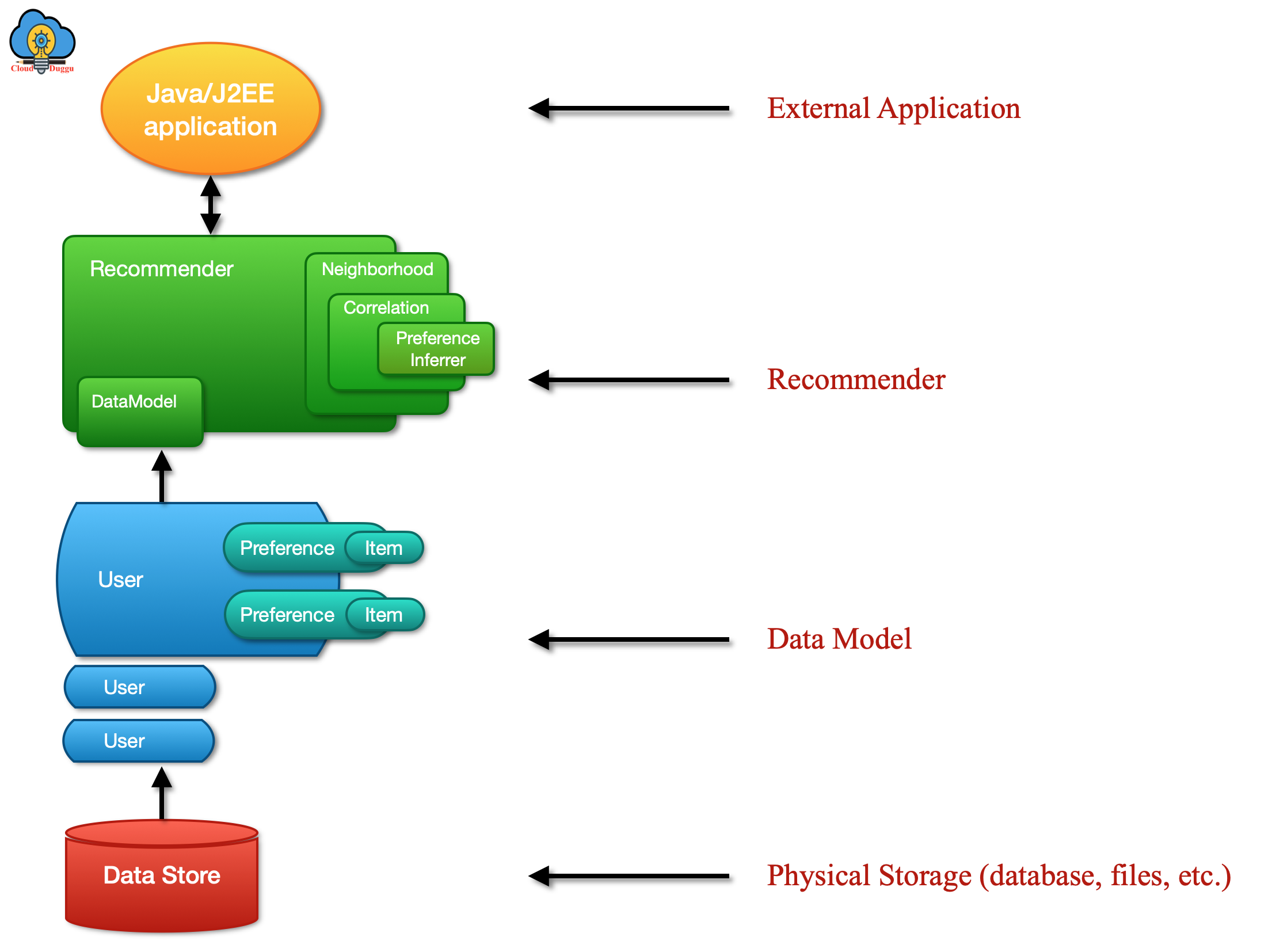
6. Apache Mahout
Apache Mahout is a framework to create machine-learning applications. It provides a rich set of components from which you can construct a customized recommender system from a selection of algorithms. Mahout is developed to provide enforcement, scalability, and compliance.
The following are the important packages that define the Mahout interfaces to these key abstractions.
- DataModel
- UserSimilarity
- ItemSimilarity
- UserNeighborhood
- Recommender
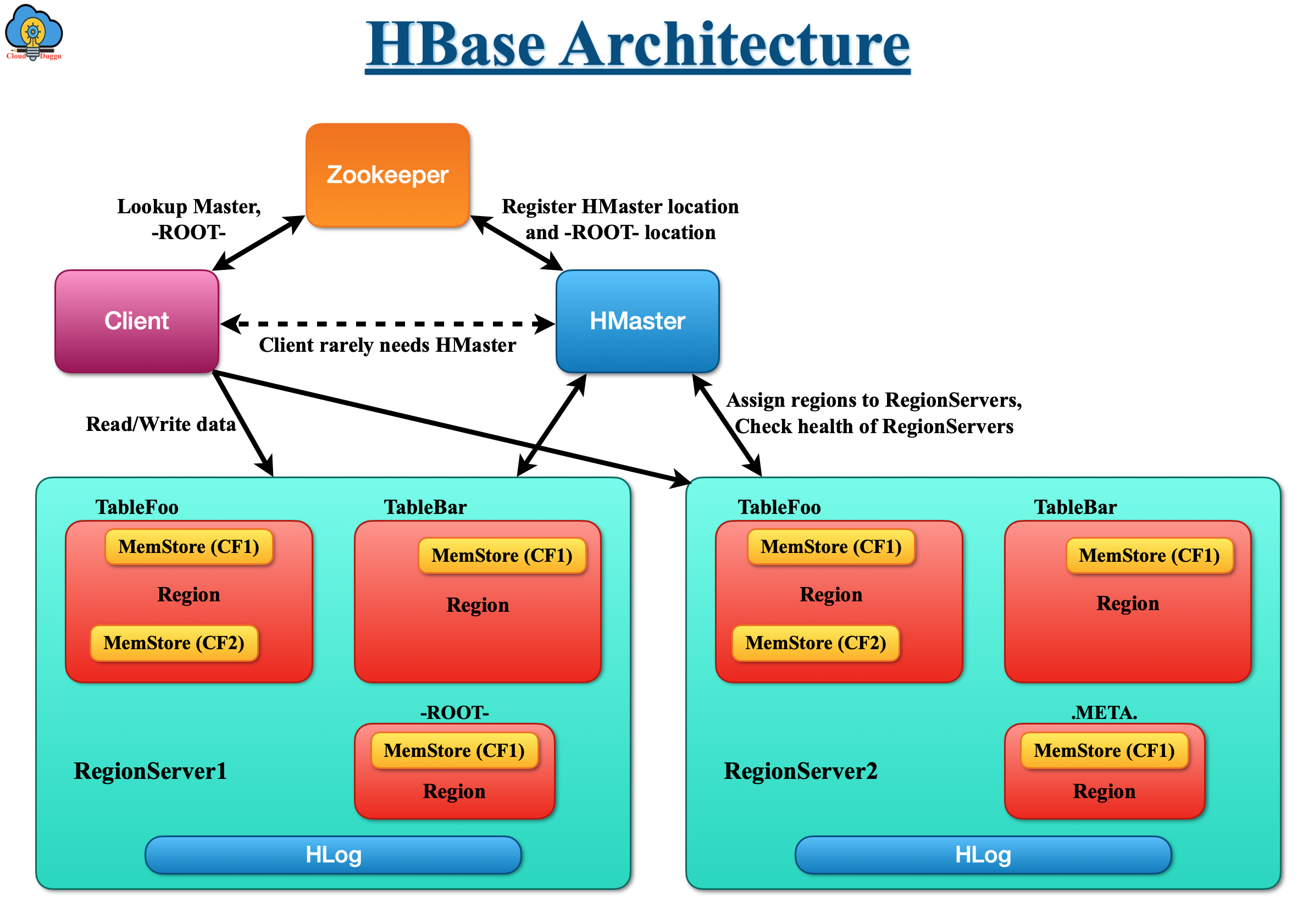
7. Apache HBase
Apache HBase is a distributed, open-source, versioned, and non-relational database that is created after Google's Bigtable. It is an import component of the Hadoop ecosystem that leverages the fault tolerance feature of HDFS and it provides real-time read and writes access to data. Hbase can be called a data storage system despite a database because it doesn’t provide RDBMS features like triggers, query language, and secondary indexes.
Apache HBase has the following features.
- It provides continuing and modular scalability.
- It surely provides regular reads and writes.
- Intuitive and configurable sharding of tables.
- Automated failover support between RegionServers.
- It provides Central base classes for supporting Hadoop MapReduce jobs with Apache HBase tables.
- It is simple to use Java API for client access.
- Query predicate pushes down via server-side Filter.
- It provides a Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding choices.
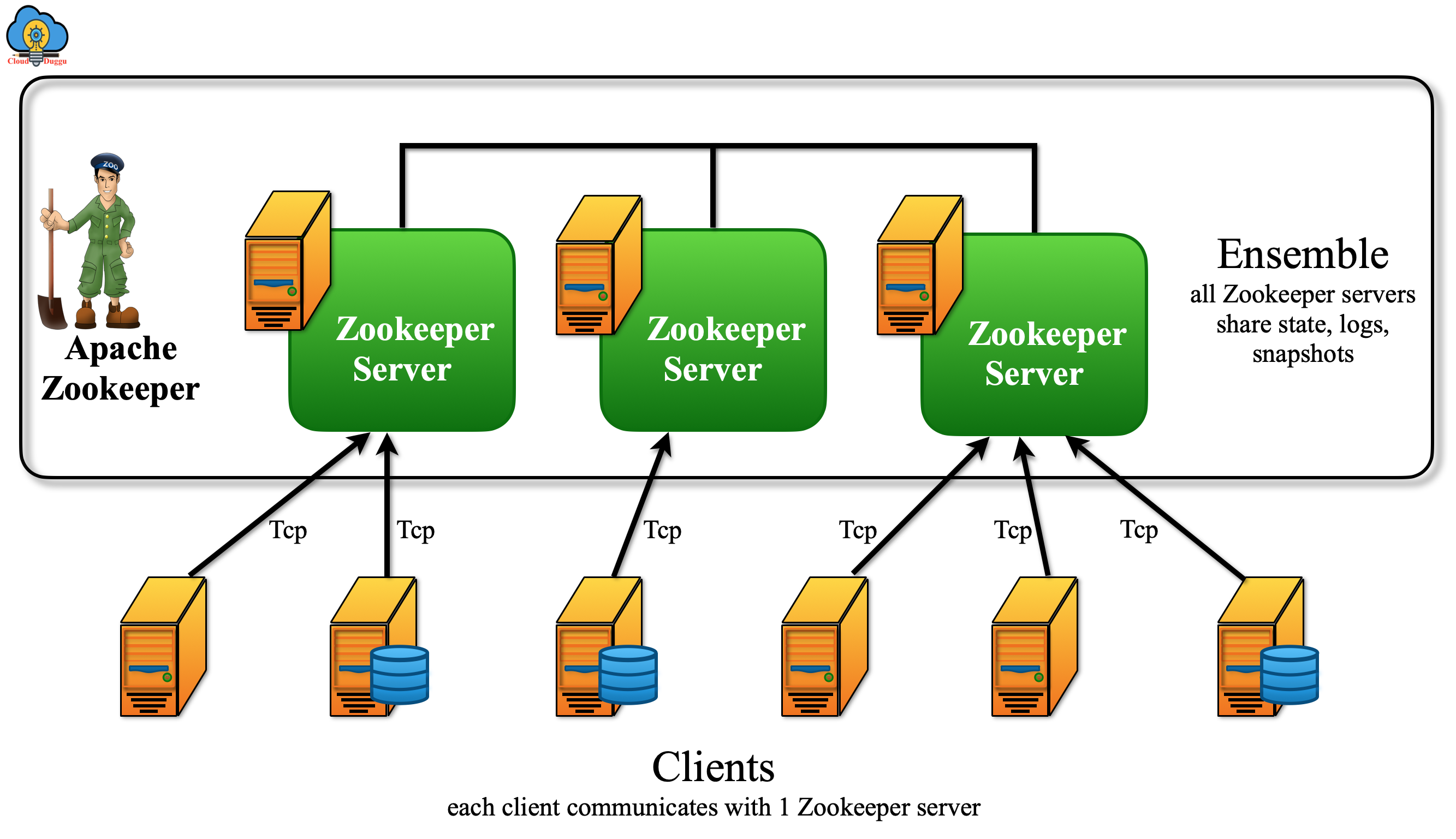
8. Apache Zookeeper
Apache Zookeeper acts as a coordinator between different services of Hadoop and is used for maintaining configuration information, naming, providing distributed synchronization, and providing group services. Zookeeper is used to fix bugs and race conditions for those applications, which are newly deployed in a distributed environment.
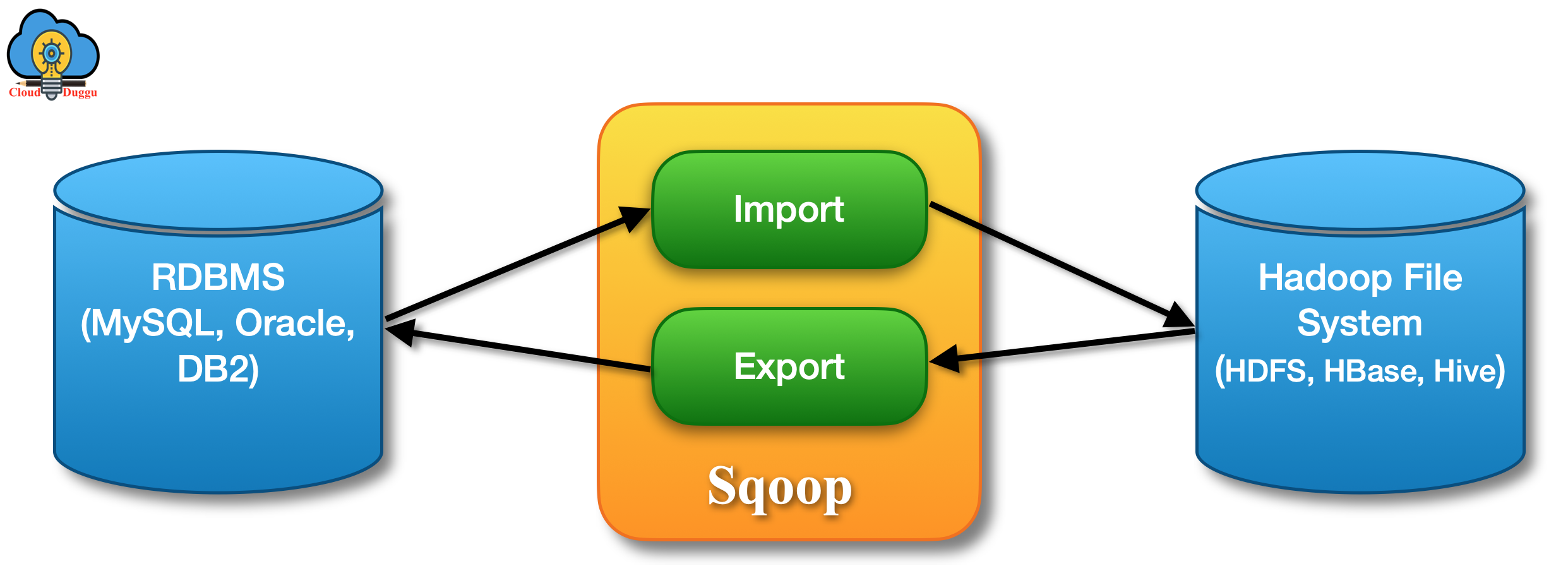
9. Apache Sqoop
Apache Sqoop is a data transfer tool, which is used to transfer data between Hadoop and relational databases. It is used to import data from a relational database management system like (MySQL or Oracle) or a mainframe into the Hadoop (HDFS), transform the data in Hadoop MapReduce. It is also used to export the data back to an RDBMS. Sqoop uses map-reduce to import and export data due to which it gets parallel processing and fault-tolerance property.
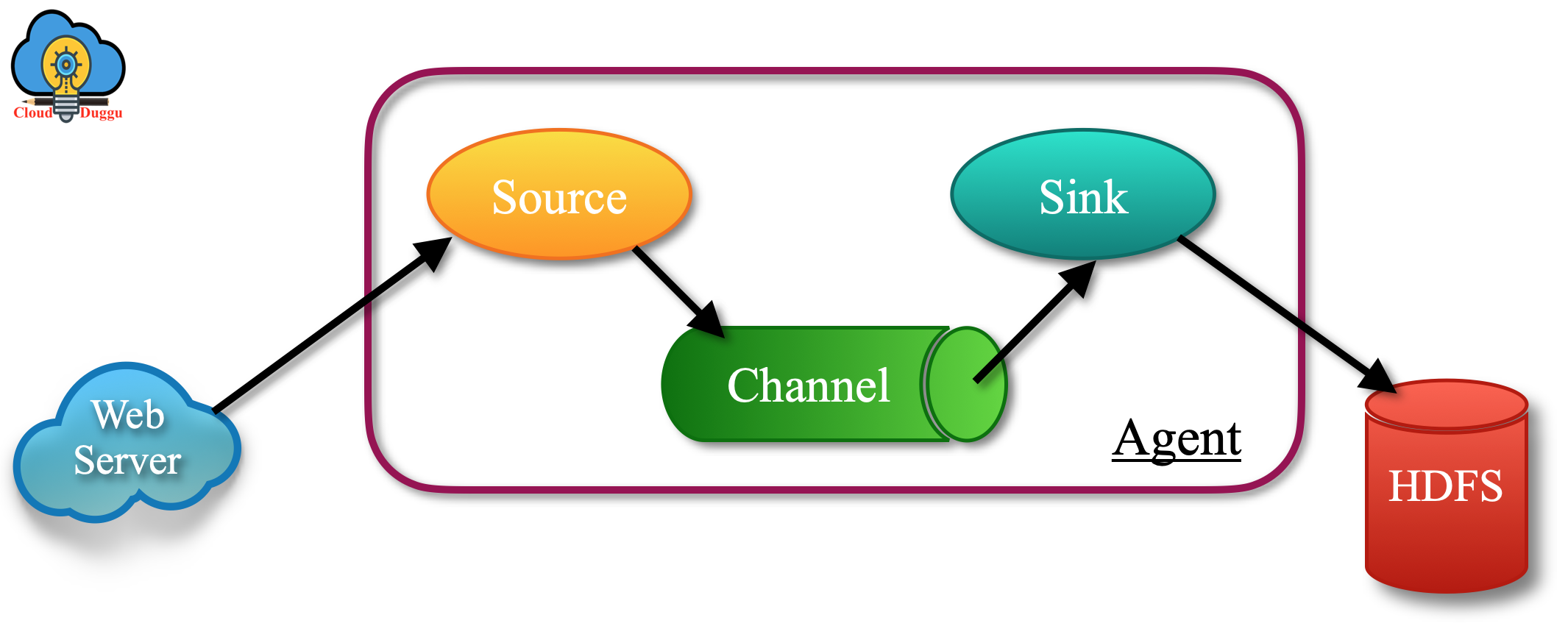
10. Apache Flume
Apache Flume is a log transfer tool similar to Sqoop but it works on unstructured data (logs) whereas Sqoop is used for structure and unstructured data. Flume is a reliable, distributed, and available system for efficiently collecting, aggregating, and moving large amounts of log data from many different sources to an HDFS. It is not restricted to log data aggregation only but it can also use to transport massive quantities of event data.
Apache Flume has the following three components.
- Source
- Channel
- Sink
11. Apache Oozie
Apache Oozie is a workflow scheduling framework that is used to schedule Hadoop Map/Reduce and Pig jobs. An Apache Oozie workflow is the collection of actions such as Hadoop Map/Reduce jobs, Pig jobs, that is arranged in a control dependency DAG (Direct Acyclic Graph). The "control dependency" from one action to another suggests that the other action will not start unless the first action has been completed.
Apache Oozie workflow has the following two nodes namely Control Flow Nodes and Action Node.
1. Control Flow Nodes
These nodes are used to provide a mechanism to control the workflow execution path.
2. Action Node
Action node provides a mechanism by which a workflow triggers the execution of a computation/processing task such as "Hadoop map-reduce, Hadoop file system, Pig, SSH, HTTP jobs".
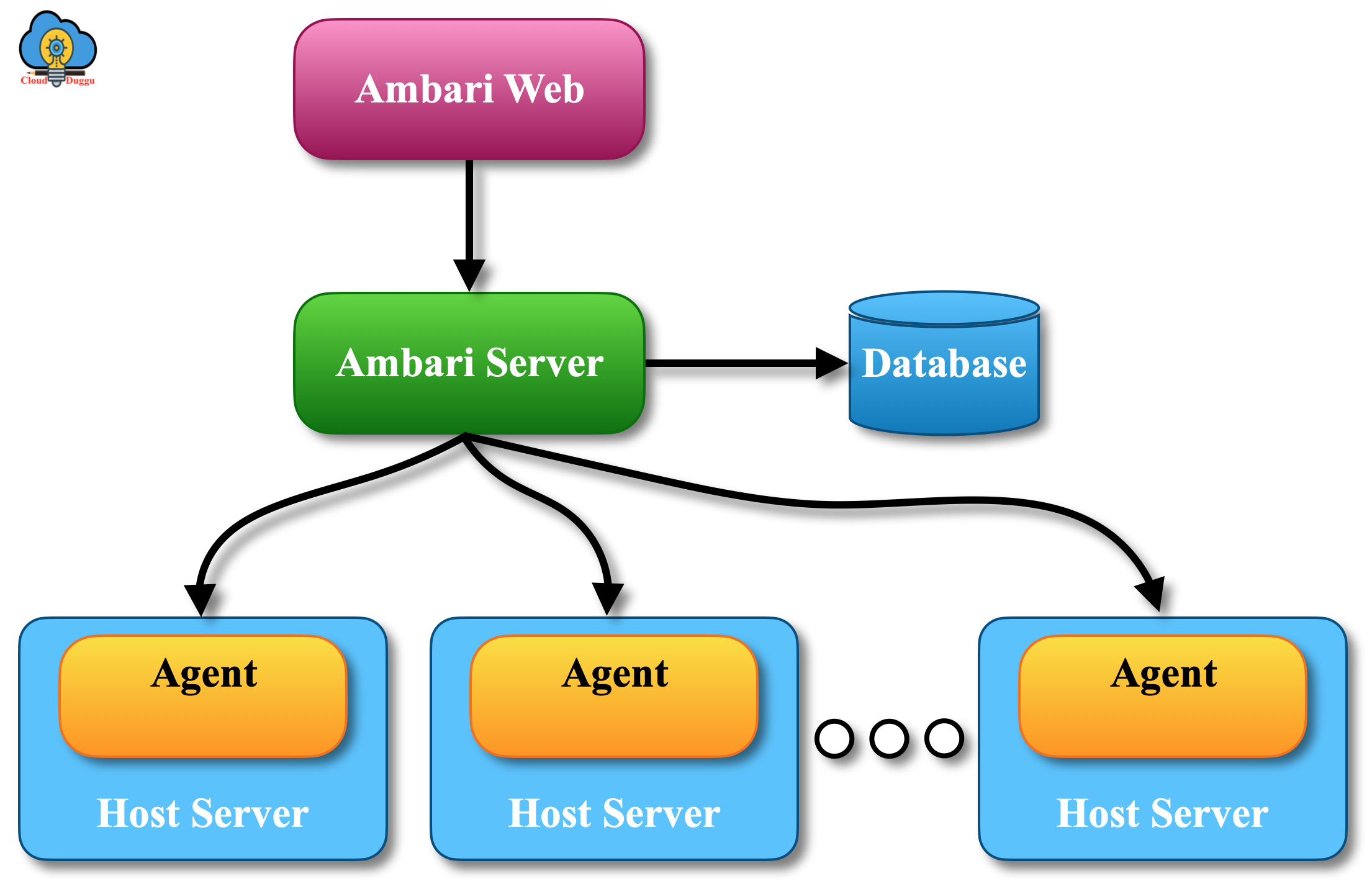
12. Apache Ambari
Apache Ambari is used for provisioning, managing, and monitoring Apache Hadoop clusters.
It offers the below task to the system admin.
1. Provisioning of a Hadoop Cluster
It provides a medium to install the Hadoop services over any number of nodes. It also handles the configuration of Hadoop services for a cluster.
2. Management of a Hadoop Cluster
It provides a central control to manage Hadoop services like starting, stopping, and reconfiguring across the entire cluster.
3. Monitoring of a Hadoop Cluster
It provides a dashboard for monitoring of the Hadoop cluster (like a node down, remaining disk space is low, etc).
13. Apache Spark
Apache Spark is a general-purpose and fast cluster computing system. It is a very powerful tool for Big data. Spark provides a rich set of APIs in multiple languages such as Python, Scala, Java, R, and so on. Spark supports high-level tools which are Spark SQL, GraphX, MLlib, Spark Streaming, R. These tools are used to perform a different kind of operation which we will see in the Apache Spark section.