Apache Flink is a true data stream processing framework that provides a rich set of APIs to perform batch and real-time stream processing. It uses the cost-based optimizer, custom-based memory manager to manage the streams. Apache Flink can be easily deployed stand along with a system which is using the commodity hardware as well as on other resource management frameworks such as Kubernetes, Hadoop YARN, and Apache Mesos. Apache Flink can easily scale up to many cores system and provides very high throughput and at the same time low latency.
The following are some of the use cases of Apache Flink.
1. Event-Driven Applications
The Event-driven Application takes the events as input and performs computations, state updates, and external actions. The Event-driven Application is developed from the traditional application design system that will have a separate computation and storage layer but in Event-driven Applications, the computation and data storage are co-located and perform in memory or disk data access.
The following figure shows the architecture of the traditional application and event-driven applications.
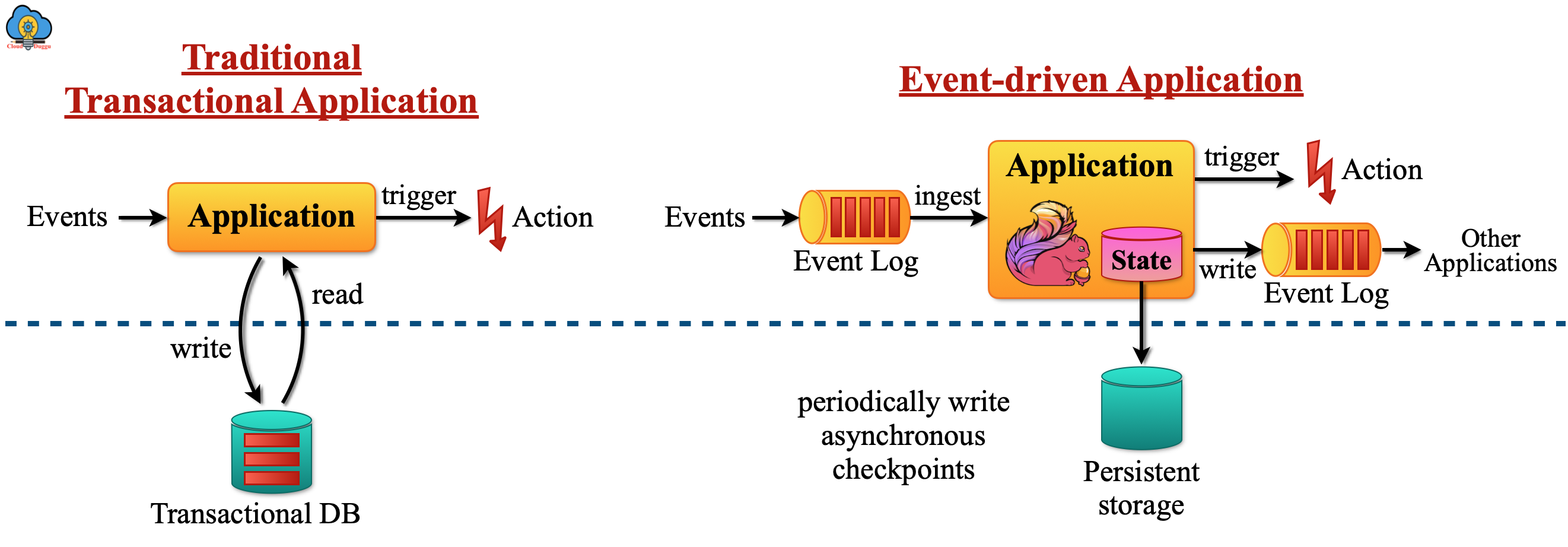
1.1 What are Apache Flink event-driven applications?
The following is the list of Apache Flink typical event-driven applications.
- Fraud detection
- Anomaly detection
- Rule-based alerting
- Business process monitoring
- Web application (social network)
2. Data Analytics Applications
The Data Analytics applications are used to fetch the value from the raw data. The batch analytics is performed on the fixed size of data also called bounded data sets and the result is stored on a storage system and in case the new data has come up then the whole process will be repeated.
If we use the online stream processing then the analytics is performed in real-time and the result is stored in the database or the external Dashboard can read that data.
Apache Flink provides the SQL interface to support the batch as well as stream processing. We can use SQL queries on bounded and unbounded data. User can create their customized code that will run using the Flink SQL interface. If there is a requirement for more custom logic then Flink provides the DataStream API or DataSet API to have control at a finer level.
The following figure shows the Apache Flink batch and streaming analytics.
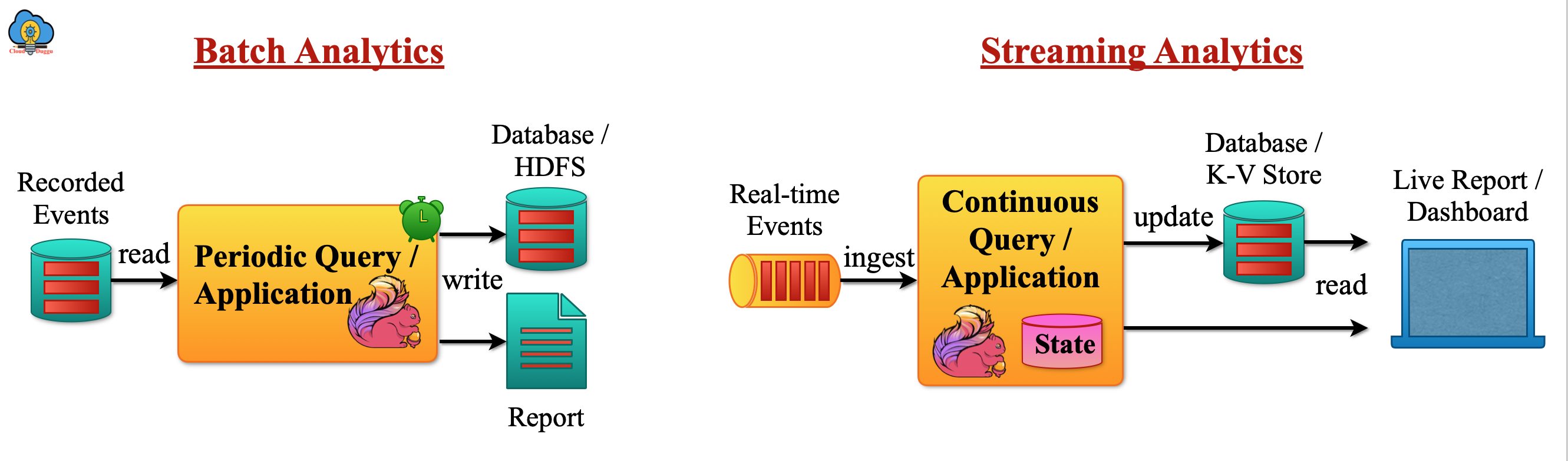
2.1 What are Apache Flink data Analytics applications?
The following is the list of Apache Flink Data Analytics applications.
- The telecom network quality check.
- The mobile application product analysis.
- The adhoc live data analysis in consumer technology.
- Graph analysis.
3. Data Pipeline Applications
The ETL jobs are the common approach to copy data from a relational database to another database or the warehouse databases system such as Teradata. The ETL(Extract-transform-load) jobs trigger periodically.
The data pipeline works in the same fashion as ETL jobs and it moves data from one system to another system but it works in continous streaming form instead of periodically run.
The following figure shows the difference between the ETL jobs and the data pipeline system.
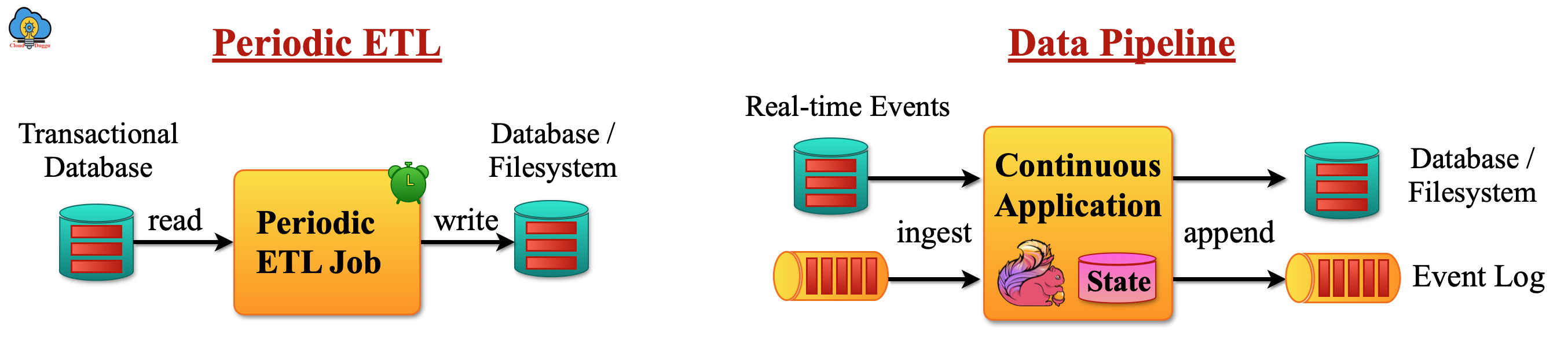
3.1 What are Apache Flink data pipeline applications?
The following is the list of Apache Flink data pipeline applications.
- The e-commerce index building in real-time.
- The continuous form of ETL operation in e-commerce.