Top 30 Apache Flink Question and Answers
1. What is Apache Flink?
Apache Flink is the 4th generation big data processing framework that is developed by the Apache Software Foundation and written in Java and Scala Language. It is also called a hybrid system that is capable to process real-time streams and batches. Apache Flink can handle millions of records and provides high throughput with low latency. It is capable to handle the backpressure in which there will be a sudden load on the system. Flink architecture has a different level of the stack which are used to perform multiple operations such as the data set API for batch processing, data stream API for stream processing, FlinkML for machine learning, Gelly for Graph processing, Table to execute relational queries, and so on.
2. What are the main features of Apache Flink?
The following are some of the important features of Apache Flink.
- Apache Flink can process all data in the form of streams at any point in time.
- Apache Flink does not give a burden on users' shoulders for tunning or managing the physical execution concepts.
- The memory management is done by the Apache Flink itself and not by the user.
- Apache Flink optimizer chooses the best plan to execute the user's program hence very little intervention is required in terms of tunning.
- Apache Flink can be deployed on various cluster frameworks.
- It is capable to support various types of the file system.
- Apache Flink can be integrated with Hadoop YARN in a very good way.
3. What is the main vision and philosophy that Apache Flink is carrying?
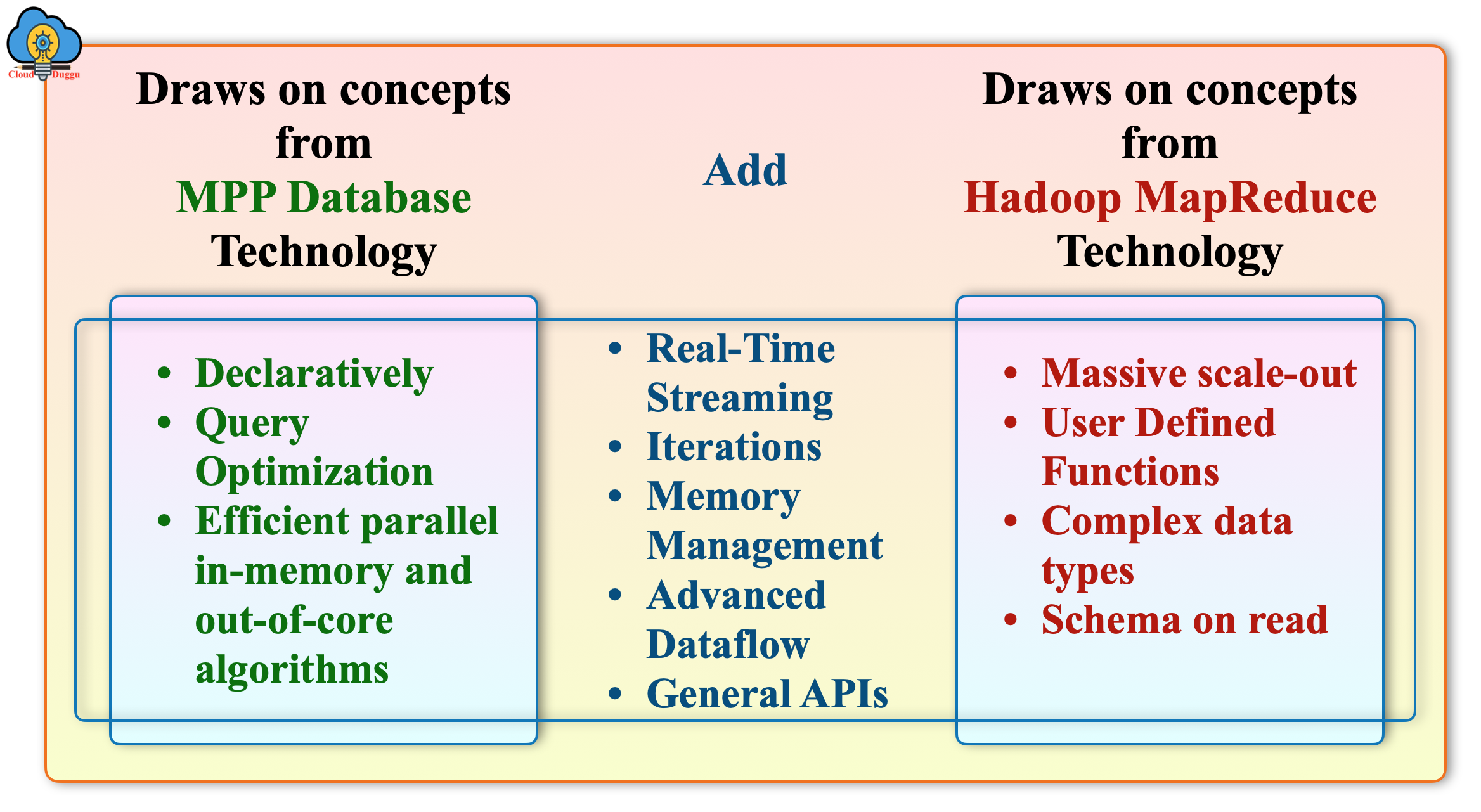
The main vision and philosophy of Apache Flink are to achieve the best technology comparing to Hadoop and MPP systems.
The following figure shows the technical concepts of Hadoop, MPP system, and the Apache Flink addition on that.
4. What is the list of top operations that we can perform by using Apache Flink?
The following is the list of top operations that we can perform using the Apache Flink tool.
- We can use Apache Flink for Batch processing.
- We can use Apache Flink to perform real-time streaming.
- Apache Flink can be used to perform Machine Learning.
- We can use Flink to perform the Graph processing.
- Apache Flink can be used to perform SQL operations.
5. Why Apache Flink is called the 4G of data analytics?
The Apache Flink is not yet another big data analytical framework it is a 4G of big data analytical framework because it has developed with many technical innovations that create a difference if we compare it with another framework like Hadoop, Spark, or Tez.
6. What is some major difference between Hadoop, Tez, Spark, and Flink?
The following figure shows some major differences between the Hadoop, Tez, Spark, and Flink.
 |
 |
 |
 |
|---|---|---|---|
|
|
|
|
| MapReduce | Direct Acyclic Graphs (DAG) Dataflows | RDD: Resilient Distributed Datasets | Cyclic Dataflows |
| 1st Generation (1G) | 2nd Generation (2G) | 3rd Generation (3G) | 4th Generation (4G) |
7. What are the Apache Flink domain-specific libraries?
The following is the list of Apache Flink domain-specific libraries.
FlinkML: It is used for machine learning.
Table: It is used to perform the relational operation.
Gelly: It is used to perform the Graph operation.
CEP: It is used for complex event processing.
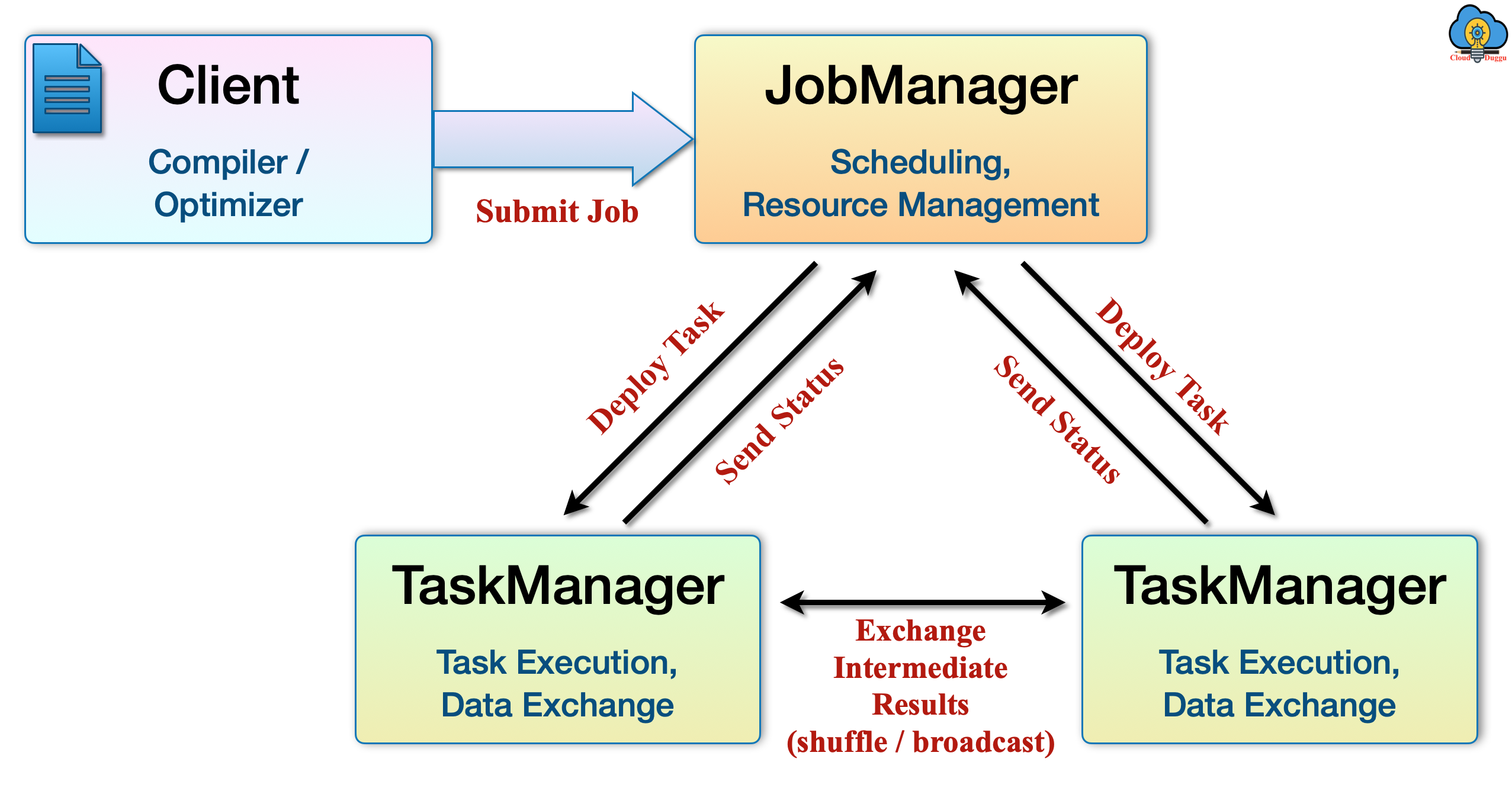
8. What is the architecture of Apache Flink?
Apache Flink architecture has the following flow.
Client: It is responsible for submitting the job on the Apache Flink cluster.
Master Node(Job Manager): The job manager is responsible to assign the task to Task managers also monitors the execution.
Worker Nodes(Task Manager): The task manager's responsibility is to execute the assigned task and send the result back to the Job manager.
9. What is the programing model of Apache Flink?
The Apache Flink Datastream and the Dataset work as a programming model of flink and its other layers of architecture. The Datastream programming model is useful in real-time stream processing whereas the Dataset programming model is useful in batch processing.
10. What are the different types of tools supported by Apache Flink?
Apache Flink supports the below list of tools.
- CLI(Command Line Interface
- Apache Flink Dashboard
- Apache Flink SQL Client
- Scala Shell
11. Can we consider Apache Flink as an alternative to Hadoop? if so then explain why?
Apache Flink provides more features and flexibility comparing to Hadoop because it uses the cycle dataflow programming model despite Mapreduce which is a two-stage disk storage model, Flink programs can work in memory and can be used with other filesystems apart from Hadoop. Flink provides the unified framework using that we can create a single data flow that will use batch, streaming, machine learning, and SQL queries.
12. What are the use cases of Apache Flink?
Many real-world industries are using Apache Flink and their use cases are as mentioned below.
12.1 Financial Services
Financial industries are using Flink to perform fraud detection in real-time and send mobile notifications.
12.2 Healthcare
The hospitals are using Apache Flink to collect data from devices such as MRI, IVs for real-time issue detection and analysis.
12.3 Ad Tech
Ads companies are using Flink to find out the real-time customer preference.
12.4 Oil Gas
The Oil and Gas industries are using Flink for real-time monitoring of pumping and issue detection.
12.5 Telecommunications
The telecom companies are using Apache Flink to provide the best services to the users such as real-time view of billing and payment, the optimization of antenna per-user location, mobile offers, and so on.
13. What are the different ways to use Apache Flink?
Apache Flink can be deployed and configured in the below ways.
- Flink can be setup Locally (Single Machine)
- It can be deployed on a VM machine.
- We can use Flink as a Docker image.
- We can configure and deploy Flink as a standalone cluster.
- Flink can be deployed and configured on Hadoop YARN and another resource managing framework.
- Flink can be deployed and configured on a Cloud system.
14. What is the different component stack of Apache Flink?
Apache Flink has a stack of components such as at storage level it supports different types of file such as HDFS, local file system, it also supports the database like HBase, MongoDB. Flink can be deployed in the standalone mode, cluster mode, and on the cloud system. It provides the dataset API for batch processing and the datastream API for stream processing also supports SQL, machine learning, and graph processing.
15. What is the command to start Apache Flink Cluster?
We can use the following command to start the Apache Flink Cluster.
cloudduggu@ubuntu:~/flink$ ./bin/start-cluster.sh
16. What is the Apache Flink SQL client and how to start it?
Apache Flink SQL client provides a command-line interface to run SQL operations such as create a table, drop table, create a view, drop the view, and other SQL commands as well.
We can start the SQL client using the below command.
cloudduggu@ubuntu:~/flink/bin$ ./start-cluster.sh
cloudduggu@ubuntu:~/flink$ ./bin/sql-client.sh embedded
17. What are the SQL statements supported in Apache Flink?
Apache Flink SQL supports the below list of statements.
- SELECT query
- CREATE TABLE, CREATE DATABASE, CREATE VIEW, CREATE FUNCTION
- DROP TABLE, DROP DATABASE, DROP VIEW, DROP FUNCTION
- ALTER TABLE, ALTER DATABASE, ALTER FUNCTION
- INSERT TABLE
- SQL HINTS
- DESCRIBE
- EXPLAIN
- USE
- SHOW
18. What is bounded and unbounded data in Apache Flink?
Apache Flink processes data in the form of bounded and unbounded streams. The bounded data will have a start point and an endpoint and the computation starts once all data has arrived. It is also called batch processing. The unbounded data will have a start point but no endpoint because it is streaming of data. The processing of unbounded data is continous and doesn't wait for complete data. As soon the data is generated the processing will start.
19. What is the building block of Apache Flink streaming applications?
The applications which are executed on the Apache Flink cluster are defined by the following three building blocks for stream processing.
- Streams
- State
- Time
20. What are the most common types of applications that use the Apache Flink?
The most common types of applications that use Apache Flinks are as below.
- Event-driven applications such as Fraud Detection, Anomaly detection, rule-based alerting, and so on.
- Data Analytics Applications such as a quality check of telecommunication companies, mobile applications product analysis, and so on.
- Data Pipeline Applications such as the index building for e-commerce.
21. What are the features of the Apache Flink execution Engine?
The core of the Apache Flink architecture is the robust, distributed, dataflow engine that performs execution as a stream using cycle dataflow execution. It provides the cost-based optimization for batch and stream programs for optimum processing and able to work in distributed memory.
22. What is Apache FlinkML?
Apache FlinkML is the machine learning library that provides APIs and scalable algorithms to perform the machine learning operations. FlinkML helps developers to reduce the Glue codes and test the code locally. The same code can be used by the developer to run on a cluster of the machine. Some of the algorithms of FlinkML are Supervised Learning, Unsupervised Learning, Data Preprocessing, and so on.
23. How can I check the progress of an Apache Flink Program?
The best way to track the progress of the Flink program is the Apache Flink Dashboard web interface. It shows the jobs which are in running such as its state the resources allocated for that job and so on. We can start the Apache Flink Dashboard using "http://localhost:8081/".
24. How Apache Flink handles the fault-tolerance?
Apache Flink manages the fault-tolerance of stream applications by capturing the snapshot of the streaming dataflow state so in case of failure those snapshots will be used for recovery. For batch processing, Flink uses the program’s sequence of transformations for recovery.
25. How to run an Apache Flink program using CLI mode?
We can use Apache Flink CLI(command-line interface) tool to run the programs which are built as JAR files.
For example, we can run a "WordCounts.jar" JAR file using the below command.
cloudduggu@ubuntu:~/flink$ ./bin/flink run ./examples/batch/WordCounts.jar
26. What are some major companies using Apache Flink?
The below list of companies is using Apache Flink.
- Alibaba
- Amazon Kinesis Data Analytics
- BetterCloud
- Bouygues Telecom
- Criteo
- Comcast
- Ericsson
- Huawei
- OPPO
- Razorpay
- Uber
- Xiaomi
- Zalando
- Yelp
27. What is the responsibility of JobManager in Apache Flink Cluster?
The Job Manager is responsible for managing and coordinating with distributed processing of a program. It assigns the task to node managers, handles the failures for recovery, and performs the checkpointing. It has three components namely ResourceManager, Dispatcher, and JobMaster.
28. What is the responsibility of TaskManager in Apache Flink Cluster?
The Task Manager is responsible for executing the dataflow task and return the result to JobManager. It executes the task in the form of a slot hence the number of slots shows the number of process execution.
29. What is the filesystem supported by Apache Flink?
Apache Flink supports the following list of the filesystem.
- local filesystem
- Hadoop HDFS
- Amazon S3
- MapR FS
- OpenStack Swift FS
- Aliyun OSS
- Azure Blob Storage
30. What is the difference between stream processing and batch processing?
In Batch processing, the data is a bounded set of the stream that has a start point and the endpoint, so once the entire data is ingested then only processing starts in batch processing mode. In-stream processing the nature of data is unbounded which means the processing will continue as the data will be received.