In this tutorial, we will go through the introduction of Apache Flink, the reason to use Apache Flink, the features of Apache Flink, and so on.
What is Apache Flink?
Apache Flink is a big data stream processing and batch processing framework that is developed by the Apache Software Foundation. Apache Flink is an open-source framework that process stream in the form of bounded and unbounded data set. The processing of Apache Flink is distributed in nature. Flink can be easily deployed with Hadoop as well as other frameworks and provides better communication, data distribution over a stream of data. Apache Flink engine is developed in JAVA and Scala language that provides high throughput, event management, and low latency.
The following figure shows the Data Streams Stateful Computations of Apache Flink.
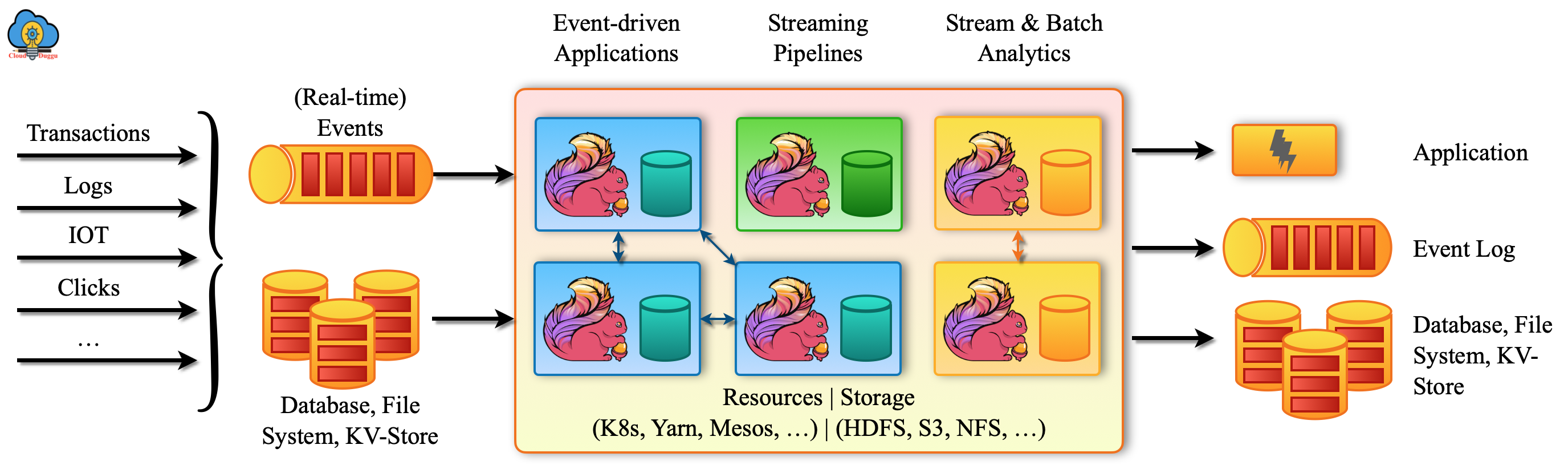
Features of Apache Flink
The following are some of the important and core features of Apache Flink.
1. High Performance and Low latency
Apache Flink processes data streaming at lightning speed with very low latency. The architecture of Apache Flink is pipelined and due to this reason, the throughput rate of processing is pretty high.
2. Better Memory Management
Apache Flink provides an optimum way to manage the memory which is needed to run the user-defined applications also allocate the required memory needed.
3. Fault Tolerance
Apache Flink uses the concept of the Chandy-Lamport algorithm to manage the distributed data stream processing and fault tolerance. The Chandy-Lamport algorithm is developed to provide a consistent state for an asynchronous system.
4. Easy Integration
Apache Flink can be easily integrated with other cluster processing frameworks such as Hadoop YARN, Kubernetes, Apache Mesos, and so on.
5. Process Bounded and Unbounded Data
The data that is getting generated today can be in any form such as sensor measurements data, the transaction of credit cards, machine logs are processed in the form of bounded and unbounded streams. The bounded streams are those data that have start and end and it processes in batch whereas the unbounded streams have no endpoint and it process continuously.
6. Rich set of operators
Apache Flink comes with a rich set of operators which are used to perform most of the operation.
7. An application can run at any Scale
Applications job can run distributed and concurrent on Apache Flink cluster and utilize the CPU, memory, IO, and disk as much as it is required for processing.
Advantages of Apache Flink
The following are the advantages of Apache Flink.
- Apache Flink memory management is similar to the C++ language inside the Java virtual machine.
- Apache Flink stores the user's data in the JVM in the form of the serialized byte array.
- Apache Flink doesn't throw the out-of-memory exception to the user.
- The garbage collection in Apache Flink is reduced.
- Apache Flink does not require the run time tunning.
- Apache Flink uses an internal buffer pool for the allocation and deallocation of memory.
- Apache Flink is a reliable framework and provides consistent performance.
Apache Flink History
The following is a year-by-year evaluation of Apache Flink.
2010: The project started as "Stratosphere" at the University of Berlin. The Stratosphere's distributed execution engine confluences the development of Flink.
2014: In March, the project was Incubator at Apache Software Foundation.
2014: Flink got popular and become one of the top-level projects in December at Apache Software Foundation.
The following are the version release of Apache Flink.
| Version | Release Date |
|---|---|
| 0.9 | 24-06-2015 |
| 0.1 | 16-11-2015 |
| 1 | 08-03-2016 |
| 1.1 | 08-08-2016 |
| 1.2 | 06-02-2017 |
| 1.3 | 01-06-2017 |
| 1.4 | 12-12-2017 |
| 1.5 | 25-05-2018 |
| 1.6 | 08-08-2018 |
| 1.7 | 30-11-2018 |
| 1.8 | 09-04-2019 |
| 1.9 | 22-08-2019 |
| 1.1 | 11-02-2020 |
Use Cases Of Apache Flink
Apache Flink is used in the following use cases.
- Batch Processing
- Real Time stream processing
- Machine Learning
- Graph Processing
- Relational queries processing