Apache Flink comes with multiples tools to perform different types of operations such as running JAR from the command line for that it offers the CLI(command-line interface) tool using that we can run the JAR, check the information about a job, list out the running jobs. It also offers the Job Manager web interface through which we can check the overall system status. The SQL client can be used to work with the SQL language.
Let us see some of the important Apache Flink tools and their usage.
1. Command Line Interface(CLI)
Apache Flink command-line interface is used to run the program which is created as a JAR file. It is also used to control the flow of program execution such as run, info, list, cancel, stop, and so on.
Let us see some of the Apache Flink CLI actions with an example.
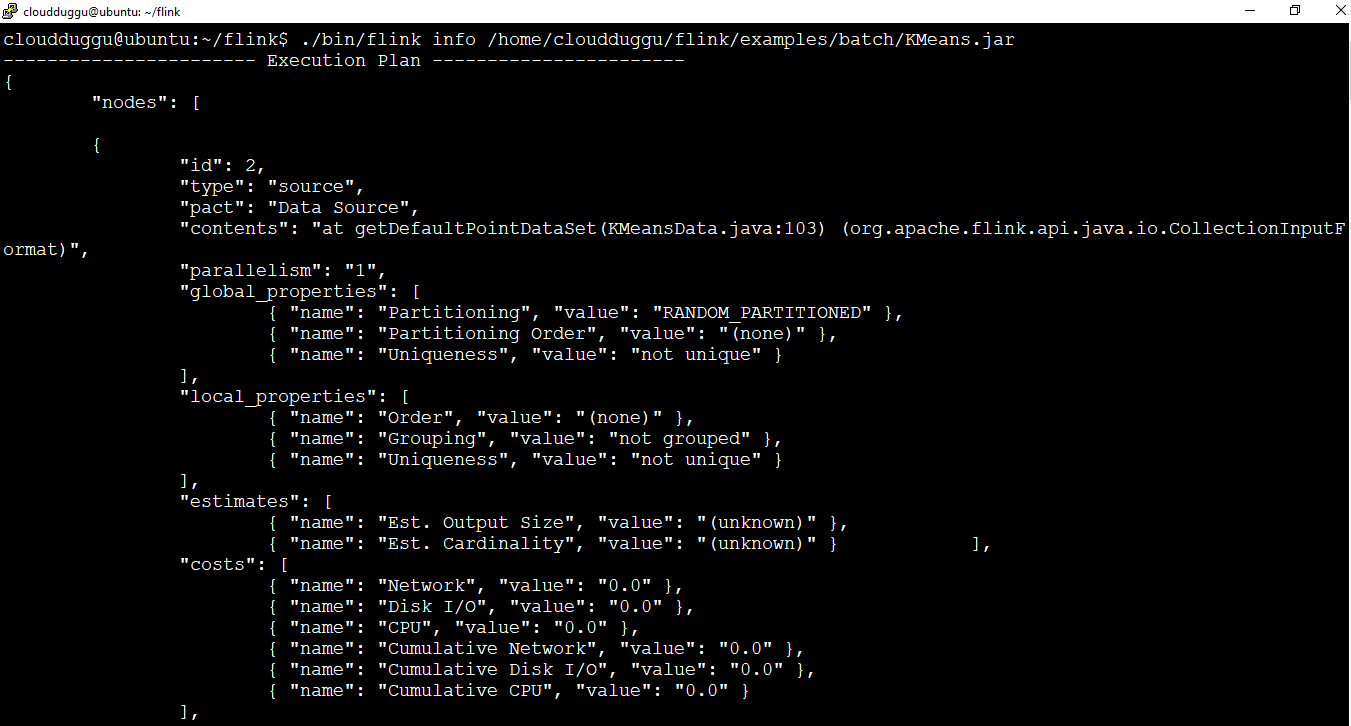
1.1 Info Action
Info action is used to show the execution flow graph of a program. To use this action use the following command.
Before performing this action the Flink cluster should be started using the following command.
cloudduggu@ubuntu:~/flink/bin$ ./start-cluster.sh
Now use the info action to see the execution graph of KMeans.jar which is by default present under the flink examples directory.
cloudduggu@ubuntu:~/flink$ ./bin/flink info /home/cloudduggu/flink/examples/batch/KMeans.jar
After running this command we can see the below output is generated.
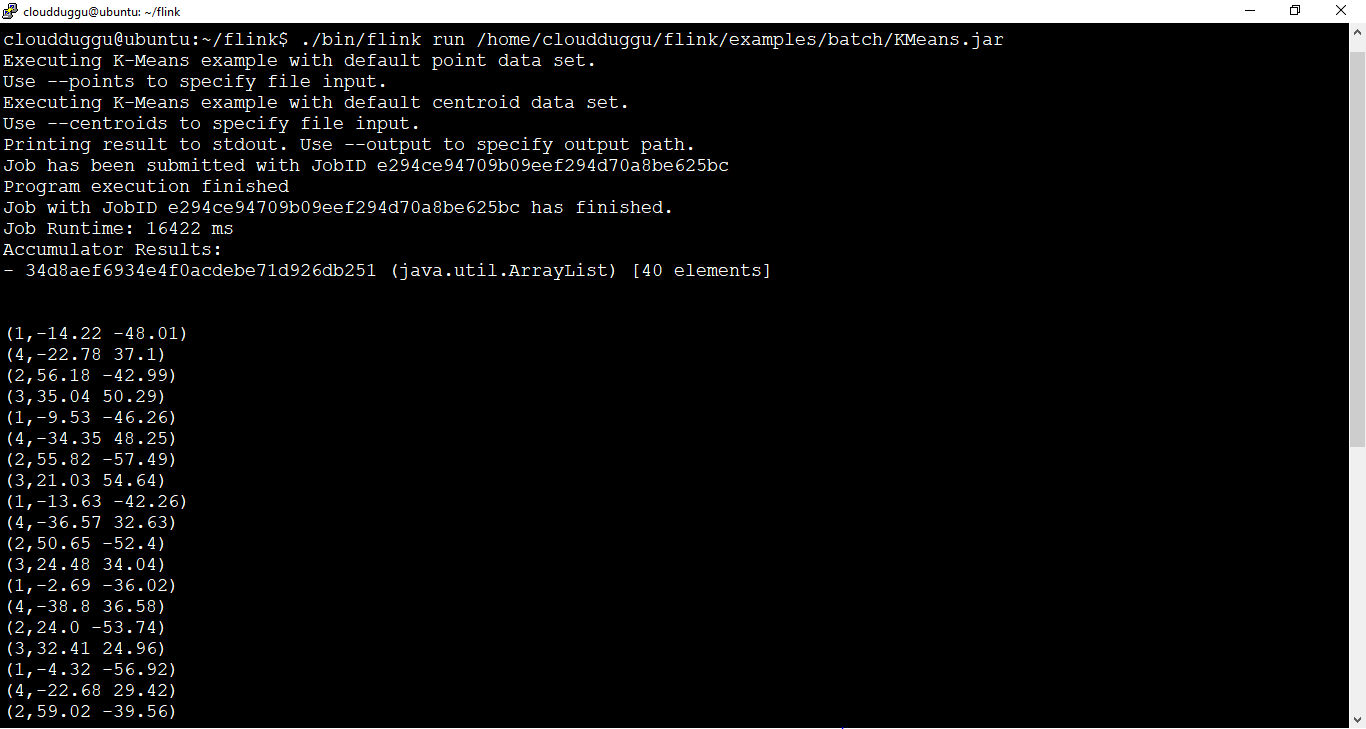
1.2 Run Action
The run action is used to run a Flink program. It takes a JAR file as an input and runs it.
Please use the below command to run the program of KMeans.
cloudduggu@ubuntu:~/flink$ ./bin/flink run /home/cloudduggu/flink/examples/batch/KMeans.jar
After running this command we can see the below output is generated.
1.3 Action
The list action shows the status of running and the scheduled jobs.
We can use the following command to check this action. We have passed KMeans.jar to see the detail.
cloudduggu@ubuntu:~/flink$ ./bin/flink list /home/cloudduggu/flink/examples/batch/KMeans.jar
The below output shows that there is no schedule or running job for this KMeans.jar.

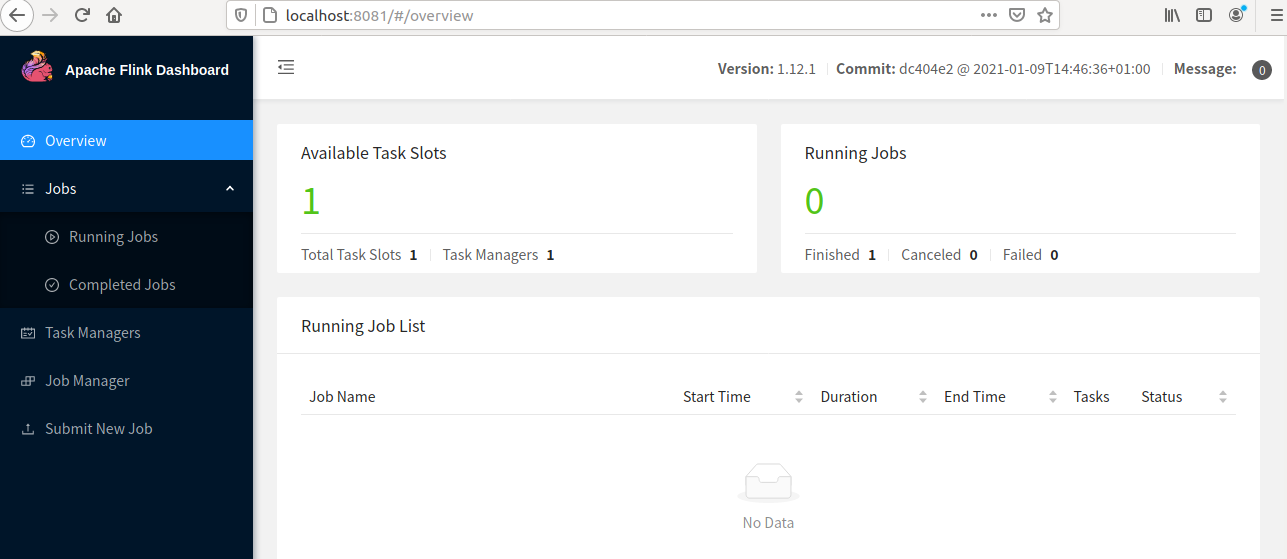
2. Apache Flink Dashboard
Apache Flink Dashboard tool is a web interface that is used to monitor the overall program execution, the resource allocation of task manager and job manager, the completed and running jobs status, and so on. We can use "localhost:8081" or the system IP as well "http://192.168.216.131:8081/" to run it.
The below figure shows the Apache Flink Dashboard.
Let us see an example to submit a program using Apache Flink Dashboard.
Step 1. To run a program click on the "Submit New Job" tab and click on "+ Add New" to add the JAR file of the program.
Step 2. Now select the JAR file of the program, in our case we have selected the KMeans.jar file that is located under the Flink home directory. (flink/examples/batch). Please check your flink home directory.
Step 3. Once the JAR file is loaded then click on that JAR file.
Step 4. Now click on the submit button to start the program.
Step 5. Now we can see the job status in the "Running Jobs" tab.
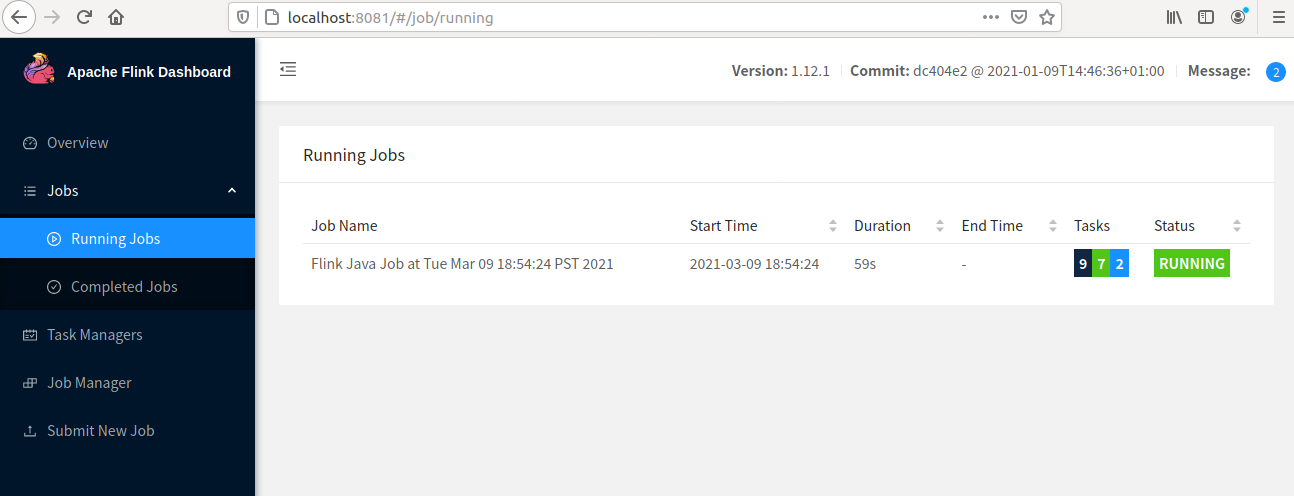
Step 6. Once Job is completed the status will be shown in the "Completed Jobs" tab.
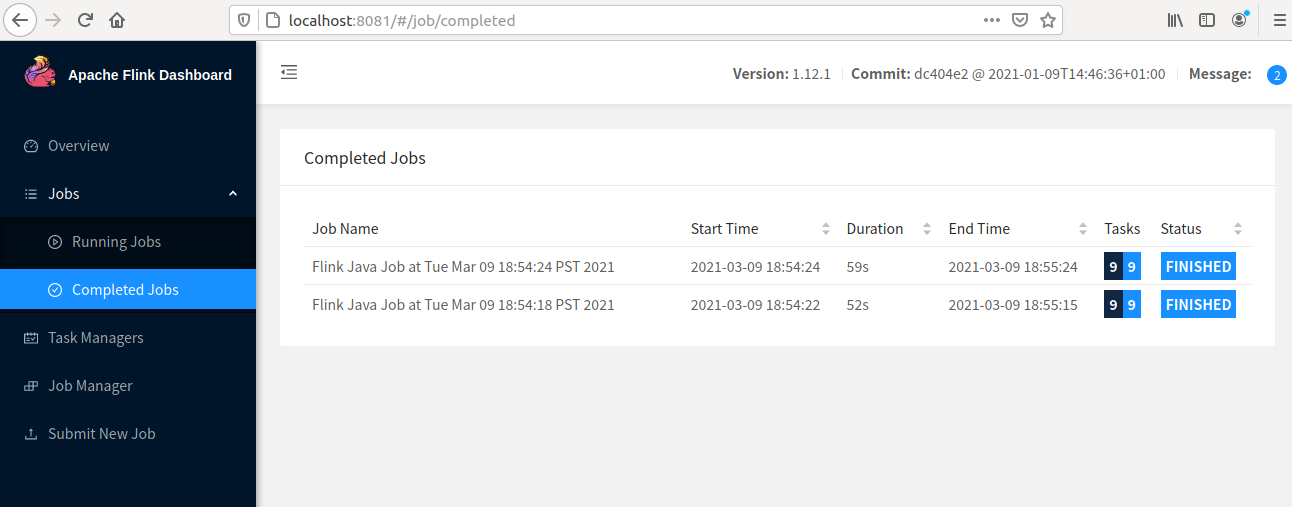
3. SQL Client
We can write the table and SQL API in the SQL language but to make it work we need to embed it in a program that is written in Scala or Java post that the program should be built in a JAR file for further execution. This complete process put a limit for developers to use Flink in an optimum way.
The SQL client provides a command-line interface to run, debug, write programs in a single line of code that runs on the Apache Flink cluster and provides the result. This tool does not require a Java or Scala code.
Let us start the SQL client interface using the following command.
Before starting SQL client we should be starting the Apache Flink cluster.
cloudduggu@ubuntu:~/flink$ ./bin/start-cluster.sh
Now start the SQL client using the below command. We will start the SQL client in the embedded mode as a standalone process.
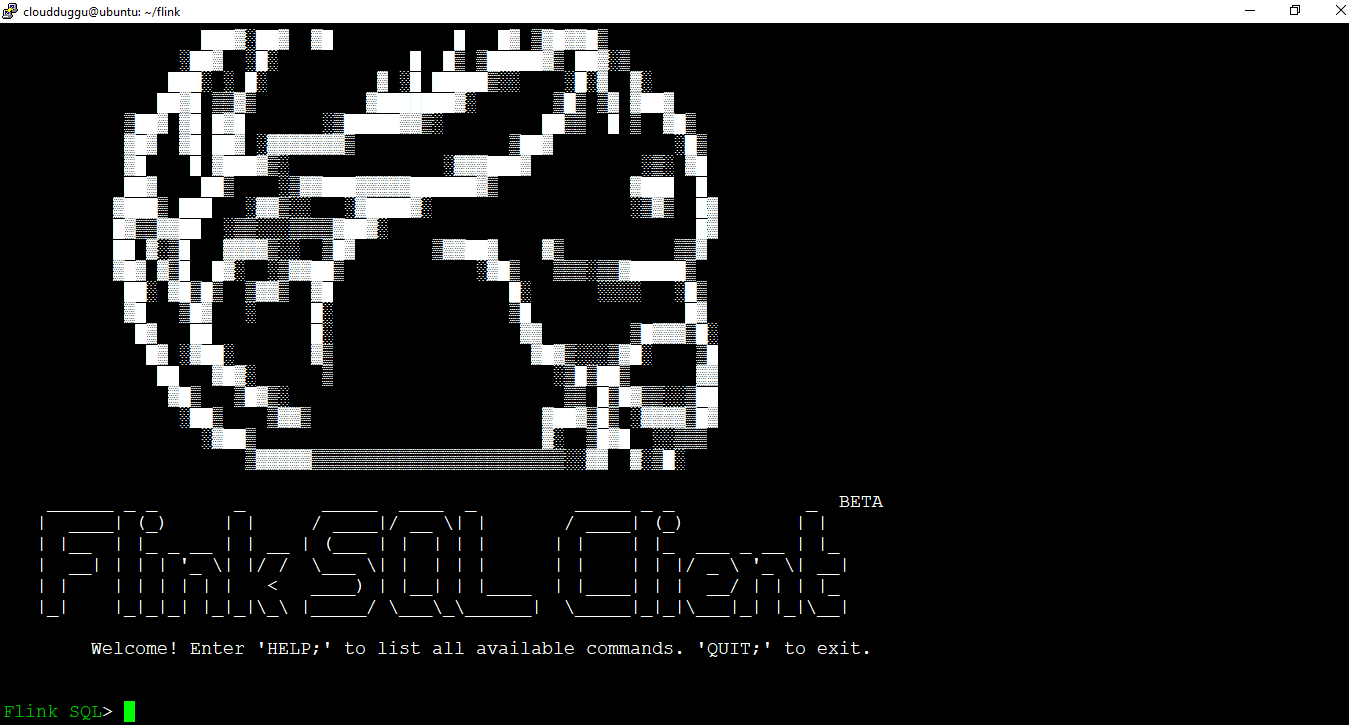
cloudduggu@ubuntu:~/flink$ ./bin/sql-client.sh embedded

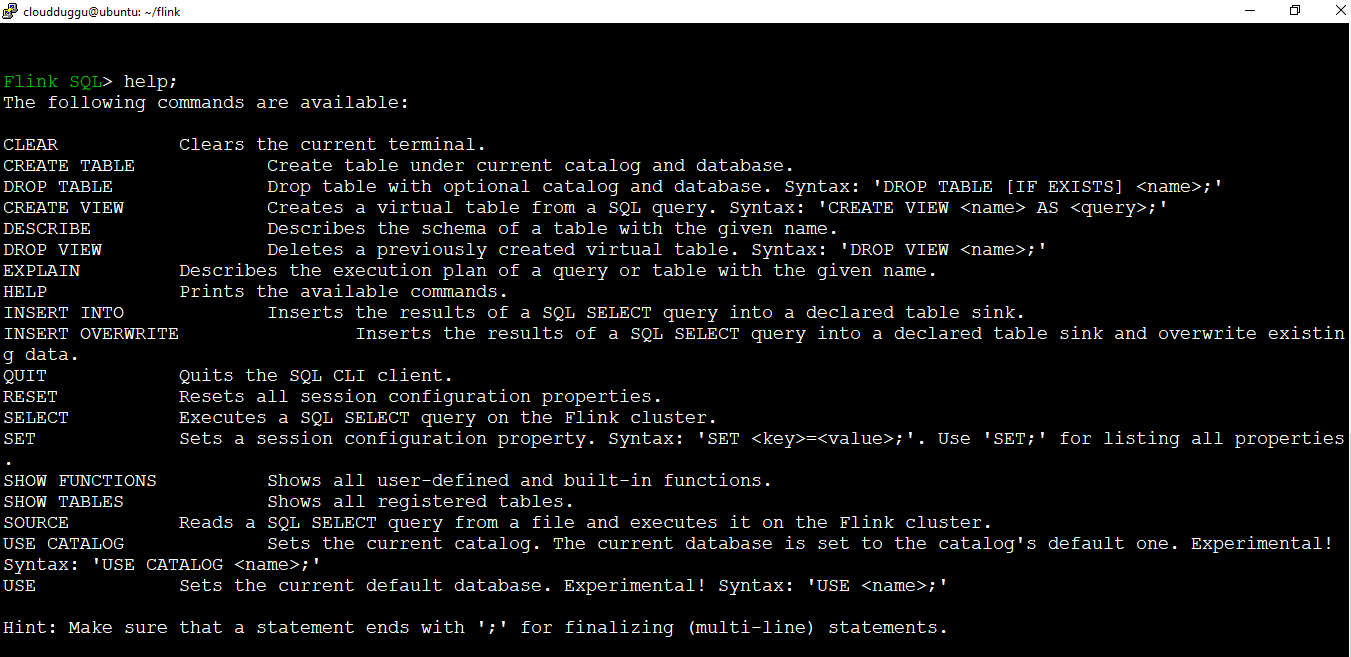
Once the SQL client is started we see the following window.
Using SQL client command-line interface we can create a table, drop table, create views, drop view, create a function, drop function, and many more operations we can perform.
We can see the list of operations supported in SQL client using the "Help" command.