Apache Flink Ecosystem Introduction
Apache Flink ecosystem is the component of the software stacks which are built on each other to provides better abstraction. Basically, the Apache Flink program will have a stream and the transformation, so the stream will be represented as a continous form of data and the transformation receive the stream as an input and perform some operations and then produce output.
The following figure represents the different components of the Apache Flink ecosystem.
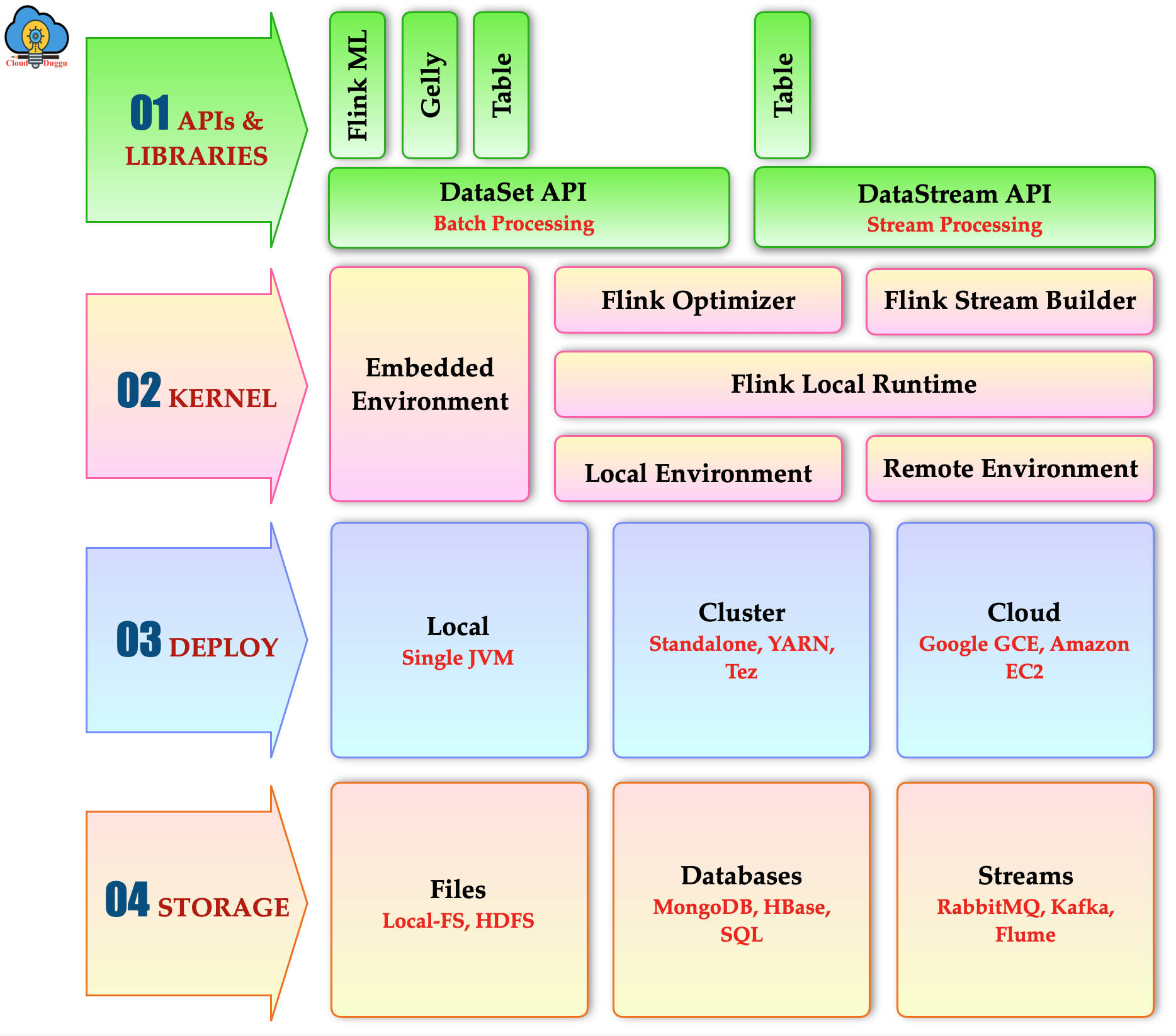
Apache Flink Ecosystem Components
Let us see each component of Apache Flink in detail.
1. APIs and Library
The APIs & Libraries are the topmost layers in Apache Flink. It has Dataset API for batch processing, the Datastream API for stream processing, Flink ML for machine learning, Gelly for graph processing, table for SQL processing. The APIs & Libraries layer of Apache Flink provides diversity.
The following are the main component of Apache Apache Flink APIs and Library layer.
- Dataset API:- It is used for batch processing.
- Datastream API:- It is used for stream processing.
- Flink ML:- It is used for machine learning.
- Gelly:- It is used for graph processing.
- Table:- It is used for SQL processing.
2. Kernel
This component of Apache Flink provides the distributed processing, reliability, and fault tolerance, and it is also called the runtime layer in the Flink ecosystem.
3. Deploy
Apache Flink can be deployed in the local mode, cloud mode, and cluster mode. In the Local mode deployment, the Flink is deployed on a single machine. In cloud mode deployment the Flink can be deployed on Amazon, Azure, and Google. In cluster mode deployment the Flink is deployed over the cluster of nodes and uses YARN, Mesos, or the standalone resource manager.
4. Storage
Apache Flink is a processing engine that performs reads/write operations on the data received from the different storage systems. Flink doesn't come with its storage.
The following are the list of storage and streaming system from which Apache Flink receive the data to perform read and write operation.
- Local File System
- Hadoop HDFS
- Amazon S3(Simple Storage Service)
- Azure Storage
- MongoDB
- HBase
- SQL
- RabbitMQ
- Flume
- Kafka