Apache Sqoop Job tool is used to create and work with saved jobs. The saved jobs remember the parameters used to specify a job, so they can be re-executed by invoking the job by its handle. We can take the benefit of Jobs for incremental import where only updated rows are required to be updated.
Apache Sqoop Job Syntax
Below is the syntax mentioned for Sqoop Job.
$ sqoop job (gener-arg) (job-arg) [-- [subtool-name] (tool-arg)]Create Apache Sqoop Job
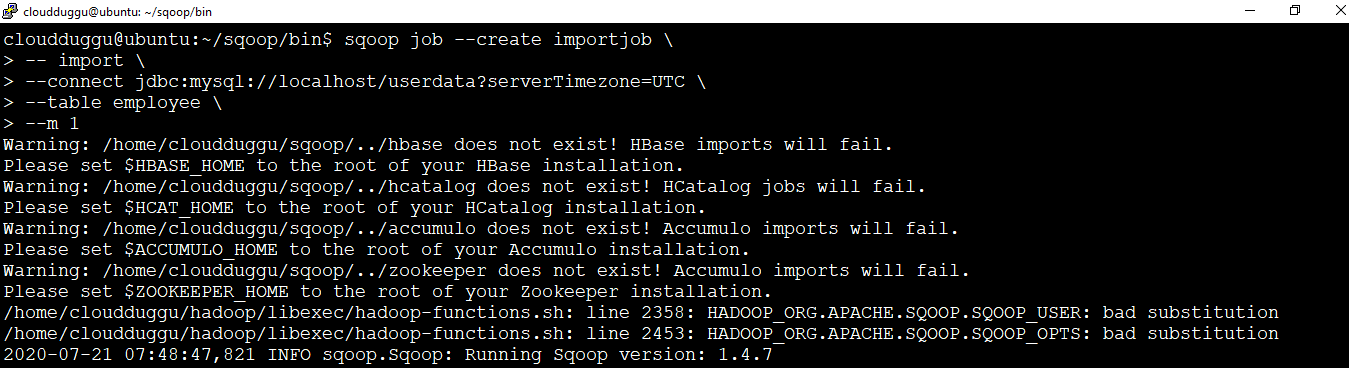
We will create a job with --create an argument that will import “employee” data from MySQL to Hadoop HDFS.
Command:
cloudduggu@ubuntu:~/sqoop/bin$ sqoop job --create importjob -- import --connect jdbc:mysql://localhost/userdata?serverTimezone=UTC --table employee --m 1Output:
List Created Jobs
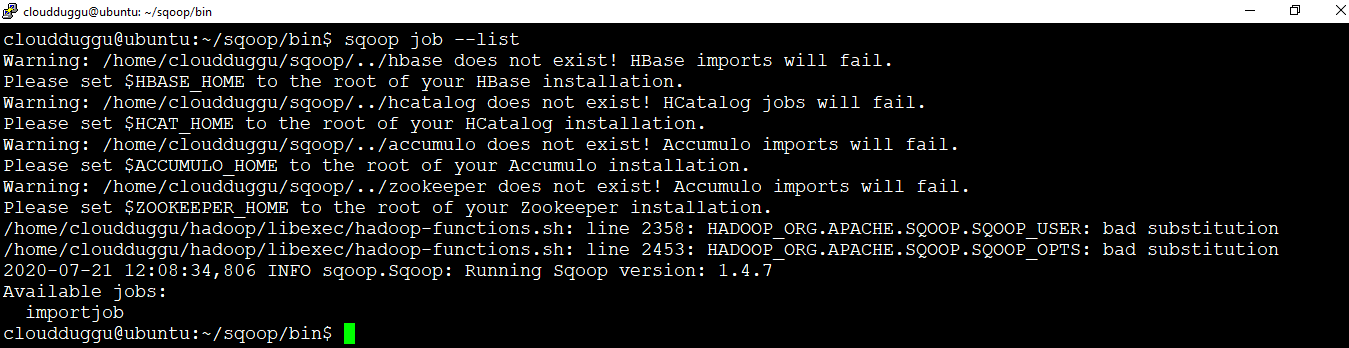
We can view all saved jobs using the (--list) argument.
Command:
cloudduggu@ubuntu:~/sqoop/bin$ sqoop job --listOutput:
Show Created Job
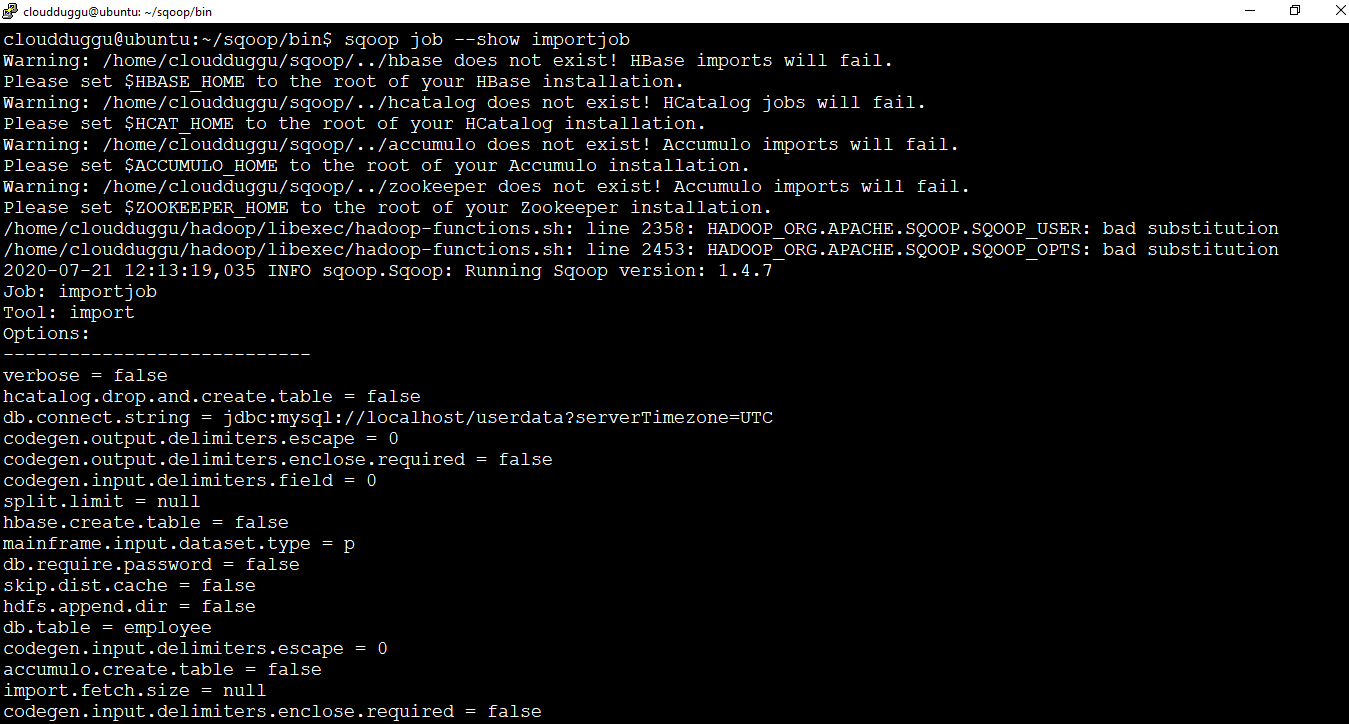
We can verify a particular job and its detail using the (--show) argument. We will verify the job “importjob” that we have created in creating the job section.
Command:
cloudduggu@ubuntu:~/sqoop/bin$ sqoop job --show importjobOutput:
Execute Job
In this example, we are executing the “importjob” job which was created in created section. We will pass the user’s password on the command prompt.
Command:
cloudduggu@ubuntu:~/sqoop/bin$ sqoop job --exec importjob -- --username root -POutput:
2020-07-21 11:07:16,238 INFO mapreduce.Job: Running job: job_1595331998069_0001
2020-07-21 11:08:38,662 INFO mapreduce.Job: Job job_1595331998069_0001 running in uber mode : false
2020-07-21 11:08:38,824 INFO mapreduce.Job: map 0% reduce 0%
2020-07-21 11:09:32,922 INFO mapreduce.Job: map 100% reduce 0%
2020-07-21 11:09:38,245 INFO mapreduce.Job: Job job_1595331998069_0001 completed successfully
2020-07-21 11:09:38,691 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225648
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=500
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=94092
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=47046
Total vcore-milliseconds taken by all map tasks=47046
Total megabyte-milliseconds taken by all map tasks=96350208
Map-Reduce Framework
Map input records=13
Map output records=13
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=426
CPU time spent (ms)=5990
Physical memory (bytes) snapshot=129261568
Virtual memory (bytes) snapshot=3410472960
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=129261568
Peak Map Virtual memory (bytes)=3410472960
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=500
2020-07-21 11:09:38,725 INFO mapreduce.ImportJobBase: Transferred 500 bytes in 171.7535 seconds (2.9111
bytes/sec)
2020-07-21 11:09:38,739 INFO mapreduce.ImportJobBase: Retrieved 13 records.
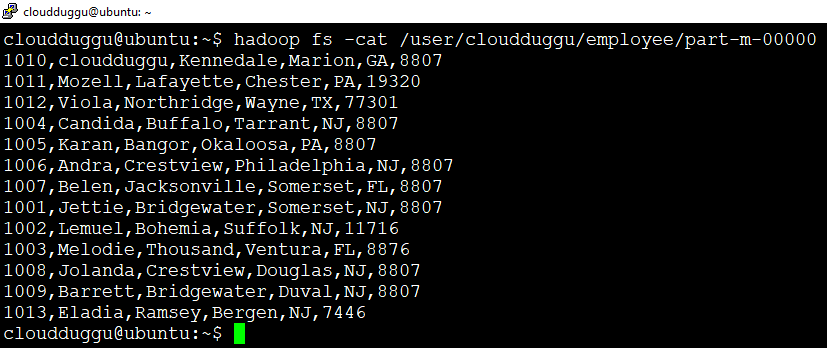
We can see a directory “/user/cloudduggu/” is created in HDFS with the name “employee” and under this “employee” directory data is stored in the “part-m-00000” file.