Apache Sqoop Import tool is used to import data from a relational database system or a mainframe into HDFS. Sqoop import tool takes the tables as input and reads records row-by-row into Hadoop HDFS. For other types of datasets such as a mainframe, Sqoop Import reads each dataset in Hadoop HDFS. Once the Sqoop Import process is completed the output is generated as a set of files that contain a copy of the imported datasets or tables. The Apache Import task is performed in parallel and hence there are multiple output files are generated. The content of files would be either text delimited or Avro or SequenceFiles defined by the user.
Apache Sqoop Import Syntax
The following syntax is used to import data in Hadoop HDFS.
$sqoop import (gen-args) (imp-args)Apache Sqoop Import Example
Let us see an example to import data from MySQL database to Hadoop HDFS.
To perform this operation we will create a database name “userdata” in MySQL. Under this database, we will create a table named “employee”. We will import this table's data in Hadoop HDFS.
Before performing any action please make sure that the MySQL database is installed on your system otherwise you can install it using the below steps.
cloudduggu@ubuntu:~$ sudo apt-get install mysql-servercloudduggu@ubuntu:~$ sudo apt-get update
Now login into MySql and set a password for the root user using the below commands.
cloudduggu@ubuntu:~$ sudo mysql -u root -pmysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'cloudduggu';
mysql> FLUSH PRIVILEGES;
Let us create a database named "userdata” and a table named “employee” in MySql and insert data.
Please use below SQL to perform this action.
mysql> CREATE database userdata;mysql> USE userdata;
mysql> CREATE TABLE employee (empid int, empname VARCHAR(20),city VARCHAR(20), county VARCHAR(20), state VARCHAR(20), zip int);
mysql> INSERT INTO employee VALUES(1001,'Jettie','Bridgewater','Somerset','NJ',8807);
mysql> INSERT INTO employee VALUES(1002,'Lemuel','Bohemia','Suffolk','NJ',11716);
mysql> INSERT INTO employee VALUES(1003,'Melodie','Thousand','Ventura','FL',8876);
mysql> INSERT INTO employee VALUES(1004,'Candida','Buffalo','Tarrant','NJ',8807);
mysql> INSERT INTO employee VALUES(1005,'Karan','Bangor','Okaloosa','PA',8807);
mysql> INSERT INTO employee VALUES(1006,'Andra','Crestview','Philadelphia','NJ',8807);
mysql> INSERT INTO employee VALUES(1007,'Belen','Jacksonville','Somerset','FL',8807);
mysql> INSERT INTO employee VALUES(1008,'Jolanda','Crestview','Douglas','NJ',8807);
mysql> INSERT INTO employee VALUES(1009,'Barrett','Bridgewater','Duval','NJ',8807);
mysql> INSERT INTO employee VALUES(1010,'Ashlyn','Kennedale','Marion','GA',8807);
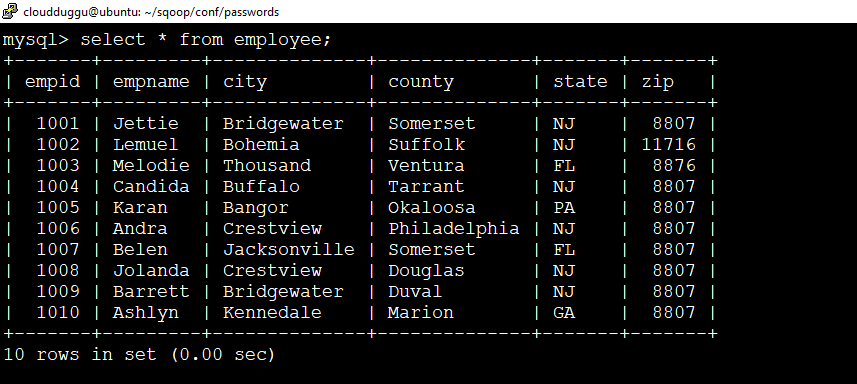
Apache Sqoop Import Table
We will import this table “employee” from MySQL to Hadoop HDFS using the below Import command.
Command:
cloudduggu@ubuntu:~$ sqoop import --connect jdbc:mysql://localhost/userdata?serverTimezone=UTC --username root --password cloudduggu --table employee --m 1
Let us understand this command.
sqoop import: It is the starting point of the Import command
--connect jdbc:mysql://localhost/userdata: It is JDBC connection detail for MySQL database.
serverTimezone=UTC: It is used to set MySQL JDBC time zone. If you are getting any time zone issue then you can set it otherwise you can ignore it.
--username root: It is the user name that Import will use to connect with MySQL databases.
-password cloudduggu: It is the password of user “root”.
--table employee: It is the table name that we are importing in Hadoop HDFS.
--m 1: It represents the number of mappers. In this case, we are using one mapper. This parameter is used to control parallelism.
Output:
After completion of the Sqoop Import job, we will receive the below output.
2020-07-19 15:13:01,468 INFO mapreduce.Job: Running job: job_1595105142263_0002
2020-07-19 15:13:40,348 INFO mapreduce.Job: Job job_1595105142263_0002 running in uber mode : false
2020-07-19 15:13:40,351 INFO mapreduce.Job: map 0% reduce 0%
2020-07-19 15:14:01,176 INFO mapreduce.Job: map 100% reduce 0%
2020-07-19 15:14:02,209 INFO mapreduce.Job: Job job_1595105142263_0002 completed successfully
2020-07-19 15:14:02,660 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225074
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=386
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=33666
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=16833
Total vcore-milliseconds taken by all map tasks=16833
Total megabyte-milliseconds taken by all map tasks=34473984
Map-Reduce Framework
Map input records=10
Map output records=10
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=284
CPU time spent (ms)=3660
Physical memory (bytes) snapshot=135614464
Virtual memory (bytes) snapshot=3408318464
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=135614464
Peak Map Virtual memory (bytes)=3408318464
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=386
2020-07-19 15:14:02,688 INFO mapreduce.ImportJobBase: Transferred 386 bytes in 75.9656 seconds (5.0812
bytes/sec)
2020-07-19 15:14:02,720 INFO mapreduce.ImportJobBase: Retrieved 10 records.
We can use the following command to verify the imported data.
cloudduggu@ubuntu:~$ hadoop fs -cat /user/cloudduggu/employee/part-m-00000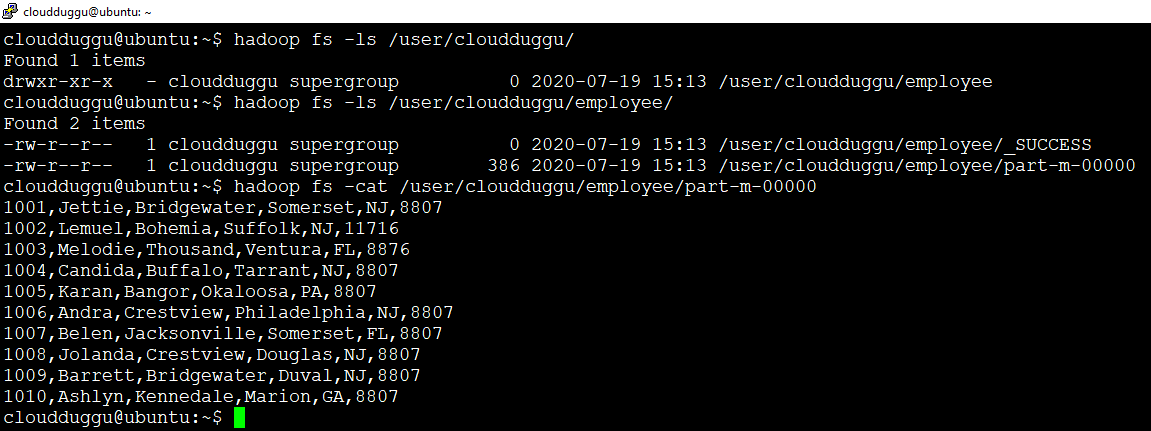
Import in HDFS Target Directory
We will import table “employee” from MySQL to Hadoop HDFS “/importdata” target directory.
Command:
cloudduggu@ubuntu:~$ sqoop import --connect jdbc:mysql://localhost/userdata?serverTimezone=UTC --username root --password cloudduggu --table employee --m 1 --target-dir /importdata
Output:
We will see the following output after the completion of the Apache Sqoop job.
2020-07-19 16:03:39,950 INFO mapreduce.Job: Running job: job_1595105142263_0003
2020-07-19 16:04:13,588 INFO mapreduce.Job: Job job_1595105142263_0003 running in uber mode : false
2020-07-19 16:04:13,590 INFO mapreduce.Job: map 0% reduce 0%
2020-07-19 16:04:38,575 INFO mapreduce.Job: map 100% reduce 0%
2020-07-19 16:04:39,614 INFO mapreduce.Job: Job job_1595105142263_0003 completed successfully
2020-07-19 16:04:40,064 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225060
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=386
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=40718
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=20359
Total vcore-milliseconds taken by all map tasks=20359
Total megabyte-milliseconds taken by all map tasks=41695232
Map-Reduce Framework
Map input records=10
Map output records=10
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=345
CPU time spent (ms)=3230
Physical memory (bytes) snapshot=126976000
Virtual memory (bytes) snapshot=3408318464
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=126976000
Peak Map Virtual memory (bytes)=3408318464
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=386
2020-07-19 16:04:40,088 INFO mapreduce.ImportJobBase: Transferred 386 bytes in 70.0787 seconds (5.5081
bytes/sec)
2020-07-19 16:04:40,102 INFO mapreduce.ImportJobBase: Retrieved 10 records.
Now we will verify the output using the below command.
cloudduggu@ubuntu:~$ hadoop fs -cat /importdata/part-m-00000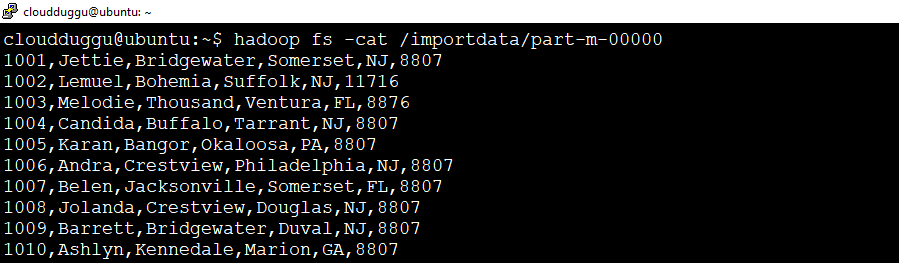
Import Subset Data of Table
Using the “where” clause we can import subset data of a table in HDFS. Here we are importing only those records where "state='NJ'.
Command:
cloudduggu@ubuntu:~$ sqoop import --connect jdbc:mysql://localhost/userdata?serverTimezone=UTC --username root --password cloudduggu --table employee --m 1 --where "state='NJ'" --target-dir /importdata
Output:
Following output, we will see post completion of Apache Sqoop job.
2020-07-19 16:41:07,456 INFO mapreduce.Job: Running job: job_1595105142263_0004
2020-07-19 16:41:36,525 INFO mapreduce.Job: Job job_1595105142263_0004 running in uber mode : false
2020-07-19 16:41:36,530 INFO mapreduce.Job: map 0% reduce 0%
2020-07-19 16:42:04,874 INFO mapreduce.Job: map 100% reduce 0%
2020-07-19 16:42:05,909 INFO mapreduce.Job: Job job_1595105142263_0004 completed successfully
2020-07-19 16:42:06,273 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225228
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=235
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=49298
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=24649
Total vcore-milliseconds taken by all map tasks=24649
Total megabyte-milliseconds taken by all map tasks=50481152
Map-Reduce Framework
Map input records=6
Map output records=6
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=644
CPU time spent (ms)=4050
Physical memory (bytes) snapshot=135913472
Virtual memory (bytes) snapshot=3413708800
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=135913472
Peak Map Virtual memory (bytes)=3413708800
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=235
2020-07-19 16:42:06,297 INFO mapreduce.ImportJobBase: Transferred 235 bytes in 69.2891 seconds (3.3916
bytes/sec)
2020-07-19 16:42:06,311 INFO mapreduce.ImportJobBase: Retrieved 6 records.
We can use the following command and verify the data.
cloudduggu@ubuntu:~$ hadoop fs -cat /importdata/part-m-00000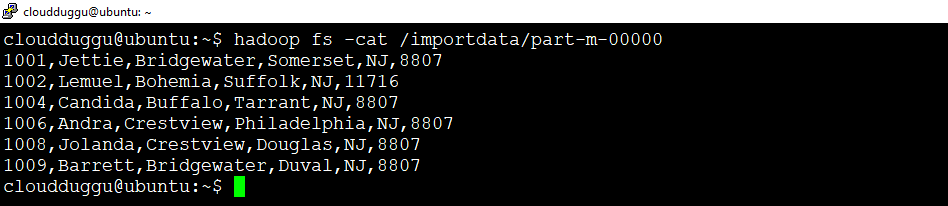
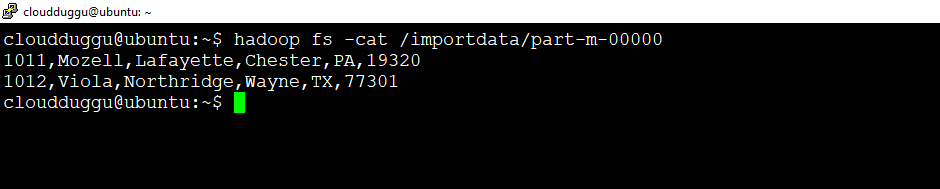
Incremental Import
Using Incremental Import we can import only newly added rows of the table. It can be done by adding ‘incremental’, ‘check-column’, and ‘last-value’ options.
We will add below two records in the “employee” table. After that, we will perform the incremental import to load only new records in HDFS.
mysql> insert into employee values(1011,'Mozell','Lafayette','Chester','PA',19320);mysql> insert into employee values(1012,'Viola','Northridge','Wayne','TX',77301);
Command:
cloudduggu@ubuntu:~$ sqoop import --connect jdbc:mysql://localhost/userdata?serverTimezone=UTC --username root --password cloudduggu --table employee --m 1 --incremental append --check-column empid --last-value 1010 --target-dir /importdata
Output:
Once the Apache Sqoop job is completed, we will see the following output.
2020-07-19 17:14:14,063 INFO mapreduce.Job: Running job: job_1595105142263_0005
2020-07-19 17:14:41,216 INFO mapreduce.Job: Job job_1595105142263_0005 running in uber mode : false
2020-07-19 17:14:41,218 INFO mapreduce.Job: map 0% reduce 0%
2020-07-19 17:15:04,060 INFO mapreduce.Job: map 100% reduce 0%
2020-07-19 17:15:05,116 INFO mapreduce.Job: Job job_1595105142263_0005 completed successfully
2020-07-19 17:15:05,449 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225312
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=76
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=38710
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=19355
Total vcore-milliseconds taken by all map tasks=19355
Total megabyte-milliseconds taken by all map tasks=39639040
Map-Reduce Framework
Map input records=2
Map output records=2
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=586
CPU time spent (ms)=4260
Physical memory (bytes) snapshot=137043968
Virtual memory (bytes) snapshot=3408318464
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=137043968
Peak Map Virtual memory (bytes)=3408318464
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=76
2020-07-19 17:15:05,487 INFO mapreduce.ImportJobBase: Transferred 76 bytes in 61.1241 seconds (1.2434
bytes/sec)
2020-07-19 17:15:05,499 INFO mapreduce.ImportJobBase: Retrieved 2 records.
2020-07-19 17:15:05,562 INFO util.AppendUtils: Appending to directory importdata
2020-07-19 17:15:05,643 INFO tool.ImportTool: Incremental import complete! To run another incremental
import of all data following this import, supply the following arguments:
2020-07-19 17:15:05,644 INFO tool.ImportTool: --incremental append
2020-07-19 17:15:05,645 INFO tool.ImportTool: --check-column empid
2020-07-19 17:15:05,645 INFO tool.ImportTool: --last-value 1012
2020-07-19 17:15:05,646 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
We can verify imported data using the below command in Hadoop HDFS.
cloudduggu@ubuntu:~$ hadoop fs -cat /importdata/part-m-00000