Apache Sqoop Import-All-Tables tool is used to import all tables from RDBMS to Hadoop HDFS. For each table, a separate directory is created with a table name, and then in that directory table’s data will be stored.
Import-All-Tables Syntax
Below syntax is used to import all tables in Hadoop HDFS.
$ sqoop import-all-tables (gen-args) (imp-args)Import-All-Tables Example
Let us see an example to import all the below tables from the MySQL database to Hadoop HDFS.
Command:
cloudduggu@ubuntu:~$ sqoop import-all-tables --connect jdbc:mysql://localhost/userdata?serverTimezone=UTC --username root--password cloudduggu --m 1

Output:
We will see the following output after job completion.
2020-07-20 05:51:23,374 INFO mapreduce.Job: Running job: job_1595247619306_0001
2020-07-20 05:52:10,699 INFO mapreduce.Job: Job job_1595247619306_0001 running in uber mode : false
2020-07-20 05:52:10,702 INFO mapreduce.Job: map 0% reduce 0%
2020-07-20 05:52:36,626 INFO mapreduce.Job: map 100% reduce 0%
2020-07-20 05:52:38,869 INFO mapreduce.Job: Job job_1595247619306_0001 completed successfully
2020-07-20 05:52:39,570 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225037
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=63
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=43290
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=21645
Total vcore-milliseconds taken by all map tasks=21645
Total megabyte-milliseconds taken by all map tasks=44328960
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=342
CPU time spent (ms)=5700
Physical memory (bytes) snapshot=146235392
Virtual memory (bytes) snapshot=3410919424
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=146235392
Peak Map Virtual memory (bytes)=3410919424
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=63
2020-07-20 05:52:39,601 INFO mapreduce.ImportJobBase: Transferred 63 bytes in 94.2109 seconds (0.6687
bytes/sec)
2020-07-20 05:52:39,628 INFO mapreduce.ImportJobBase: Retrieved 3 records.
2020-07-20 05:52:39,629 INFO tool.CodeGenTool: Beginning code generation
2020-07-20 05:52:39,836 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `employee` AS
t LIMIT 1
2020-07-20 05:52:39,896 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/cloudduggu/hadoop
Note: /tmp/sqoop-cloudduggu/compile/fc94ffa41264c7eeb7b2c6e4ad14db35/employee.java uses or overrides a
deprecated API.
Note: Recompile with -Xlint:deprecation for details.
2020-07-20 05:52:46,273 INFO orm.CompilationManager: Writing jar file:
/tmp/sqoop-cloudduggu/compile/fc94ffa41264c7eeb7b2c6e4ad14db35/employee.jar
2020-07-20 05:52:46,309 INFO mapreduce.ImportJobBase: Beginning import of employee
2020-07-20 05:52:46,456 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2020-07-20 05:52:46,551 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path:
/tmp/hadoop-yarn/staging/cloudduggu/.staging/job_1595247619306_0002
2020-07-20 05:52:48,276 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.closeInternal(DataStreamer.java:847)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:843)
2020-07-20 05:52:49,028 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.closeInternal(DataStreamer.java:847)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:843)
2020-07-20 05:52:50,329 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.closeInternal(DataStreamer.java:847)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:843)
2020-07-20 05:52:51,871 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
2020-07-20 05:52:51,964 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
2020-07-20 05:52:53,928 INFO db.DBInputFormat: Using read commited transaction isolation
2020-07-20 05:52:54,509 INFO mapreduce.JobSubmitter: number of splits:1
2020-07-20 05:52:54,642 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1595247619306_0002
2020-07-20 05:52:54,644 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-07-20 05:52:54,906 INFO impl.YarnClientImpl: Submitted application application_1595247619306_0002
2020-07-20 05:52:54,950 INFO mapreduce.Job: The url to track the job:
http://ubuntu:8088/proxy/application_1595247619306_0002/
2020-07-20 05:52:54,954 INFO mapreduce.Job: Running job: job_1595247619306_0002
2020-07-20 05:53:28,086 INFO mapreduce.Job: Job job_1595247619306_0002 running in uber mode : false
2020-07-20 05:53:28,087 INFO mapreduce.Job: map 0% reduce 0%
2020-07-20 05:53:51,098 INFO mapreduce.Job: map 100% reduce 0%
2020-07-20 05:53:53,169 INFO mapreduce.Job: Job job_1595247619306_0002 completed successfully
2020-07-20 05:53:53,298 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225074
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=462
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=39762
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=19881
Total vcore-milliseconds taken by all map tasks=19881
Total megabyte-milliseconds taken by all map tasks=40716288
Map-Reduce Framework
Map input records=12
Map output records=12
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=281
CPU time spent (ms)=5210
Physical memory (bytes) snapshot=153419776
Virtual memory (bytes) snapshot=3410935808
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=153419776
Peak Map Virtual memory (bytes)=3410935808
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=462
2020-07-20 05:53:53,342 INFO mapreduce.ImportJobBase: Transferred 462 bytes in 66.9515 seconds (6.9005
bytes/sec)
2020-07-20 05:53:53,367 INFO mapreduce.ImportJobBase: Retrieved 12 records.
2020-07-20 05:53:53,374 INFO tool.CodeGenTool: Beginning code generation
2020-07-20 05:53:53,502 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `invoice` AS t
LIMIT 1
2020-07-20 05:53:53,533 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/cloudduggu/hadoop
Note: /tmp/sqoop-cloudduggu/compile/fc94ffa41264c7eeb7b2c6e4ad14db35/invoice.java uses or overrides a
deprecated API.
Note: Recompile with -Xlint:deprecation for details.
2020-07-20 05:53:55,687 INFO orm.CompilationManager: Writing jar file:
/tmp/sqoop-cloudduggu/compile/fc94ffa41264c7eeb7b2c6e4ad14db35/invoice.jar
2020-07-20 05:53:55,727 INFO mapreduce.ImportJobBase: Beginning import of invoice
2020-07-20 05:53:55,842 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2020-07-20 05:53:55,918 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path:
/tmp/hadoop-yarn/staging/cloudduggu/.staging/job_1595247619306_0003
2020-07-20 05:53:56,031 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
2020-07-20 05:53:56,112 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
2020-07-20 05:53:57,446 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.closeInternal(DataStreamer.java:847)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:843)
2020-07-20 05:53:59,704 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
2020-07-20 05:53:59,811 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.closeInternal(DataStreamer.java:847)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:843)
2020-07-20 05:54:00,598 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
2020-07-20 05:54:01,695 INFO db.DBInputFormat: Using read commited transaction isolation
2020-07-20 05:54:01,867 INFO mapreduce.JobSubmitter: number of splits:1
2020-07-20 05:54:01,971 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1595247619306_0003
2020-07-20 05:54:01,973 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-07-20 05:54:02,419 INFO impl.YarnClientImpl: Submitted application application_1595247619306_0003
2020-07-20 05:54:02,441 INFO mapreduce.Job: The url to track the job:
http://ubuntu:8088/proxy/application_1595247619306_0003/
2020-07-20 05:54:02,444 INFO mapreduce.Job: Running job: job_1595247619306_0003
2020-07-20 05:54:31,992 INFO mapreduce.Job: Job job_1595247619306_0003 running in uber mode : false
2020-07-20 05:54:31,994 INFO mapreduce.Job: map 0% reduce 0%
2020-07-20 05:54:57,133 INFO mapreduce.Job: map 100% reduce 0%
2020-07-20 05:54:59,241 INFO mapreduce.Job: Job job_1595247619306_0003 completed successfully
2020-07-20 05:54:59,385 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225049
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=63
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=42812
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=21406
Total vcore-milliseconds taken by all map tasks=21406
Total megabyte-milliseconds taken by all map tasks=43839488
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=364
CPU time spent (ms)=5790
Physical memory (bytes) snapshot=145625088
Virtual memory (bytes) snapshot=3408330752
Total committed heap usage (bytes)=32571392
Peak Map Physical memory (bytes)=145625088
Peak Map Virtual memory (bytes)=3408330752
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=63
2020-07-20 05:54:59,418 INFO mapreduce.ImportJobBase: Transferred 63 bytes in 63.6403 seconds (0.9899
bytes/sec)
2020-07-20 05:54:59,433 INFO mapreduce.ImportJobBase: Retrieved 3 records.
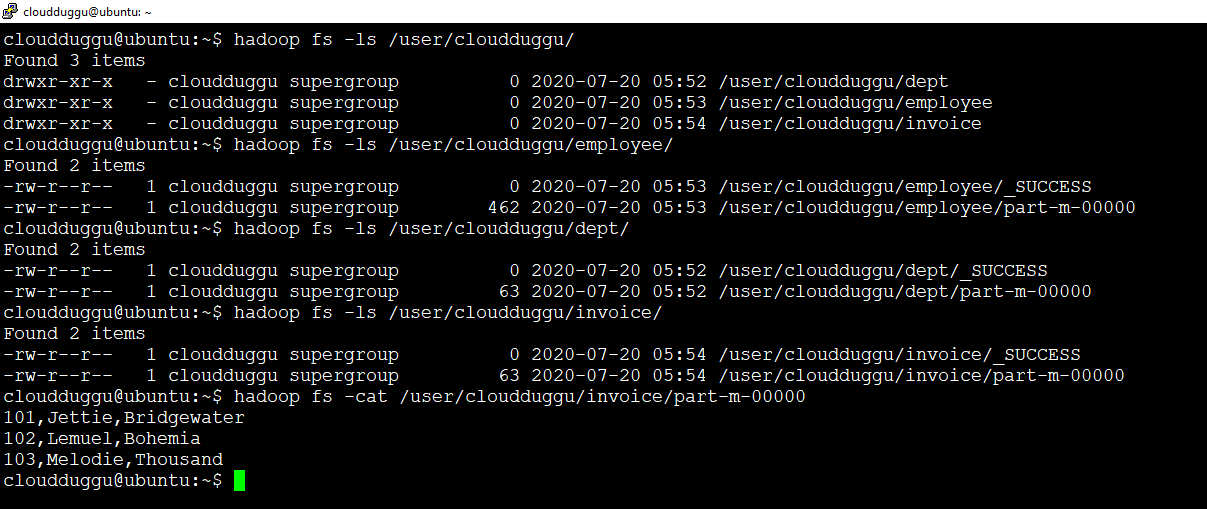
We can verify imported data using the below command in Hadoop HDFS. We can see three directories are created in HDFS with table name and data will present under these directories with the name “part-m-00000”.
cloudduggu@ubuntu:~$ hadoop fs -ls /user/cloudduggu/cloudduggu@ubuntu:~$ hadoop fs -ls /user/cloudduggu/employee/
cloudduggu@ubuntu:~$ hadoop fs -ls /user/cloudduggu/dept/
cloudduggu@ubuntu:~$ hadoop fs -ls /user/cloudduggu/invoice/
cloudduggu@ubuntu:~$ hadoop fs -cat /user/cloudduggu/invoice/part-m-00000