What is Apache Sqoop?
Apache Sqoop stands for "SQL-to-Hadoop" which is a tool designed for efficiently transferring the bulk of data between Apache Hadoop systems and structured datastores systems such as relational databases. Sqoop can be used to import data from external structured databases into Hadoop Distributed File System or related systems like Hive and HBase. Conversely, Sqoop can be used to extract data from Hadoop and export it to external structured datastores such as relational databases and enterprise data warehouses systems. Sqoop uses MapReduce to perform import and export operations.
Challenges Before Apache Sqoop
The following are some of the challenges that industries were facing before Apache Sqoop.
- To load a high volume of data from the production system to Hadoop was very challenging or to access that data from the MapReduce program was even more challenging over a cluster of nodes.
- To process such huge data user was concerned about the production system resources, data consistency, and prepare filtered data for the downstream pipeline.
- If a user was using a script to process and then transfer data that was also a time-consuming task.
- Accessing external data from the MapReduce program creates complications for the production system.
Why we need Apache Sqoop?
Apache Sqoop is used for:
- Apache Sqoop is designed to transfer a huge amount of data between Apache Hadoop and relational databases and from relational databases to Hadoop.
- Apache Sqoop uses the parallel to transfer data.
- Apache Sqoop can copy data from external systems such as Teradata to Hadoop very fast.
- We can use Apache Sqoop to perform incremental loads based on only changed data since the last import.
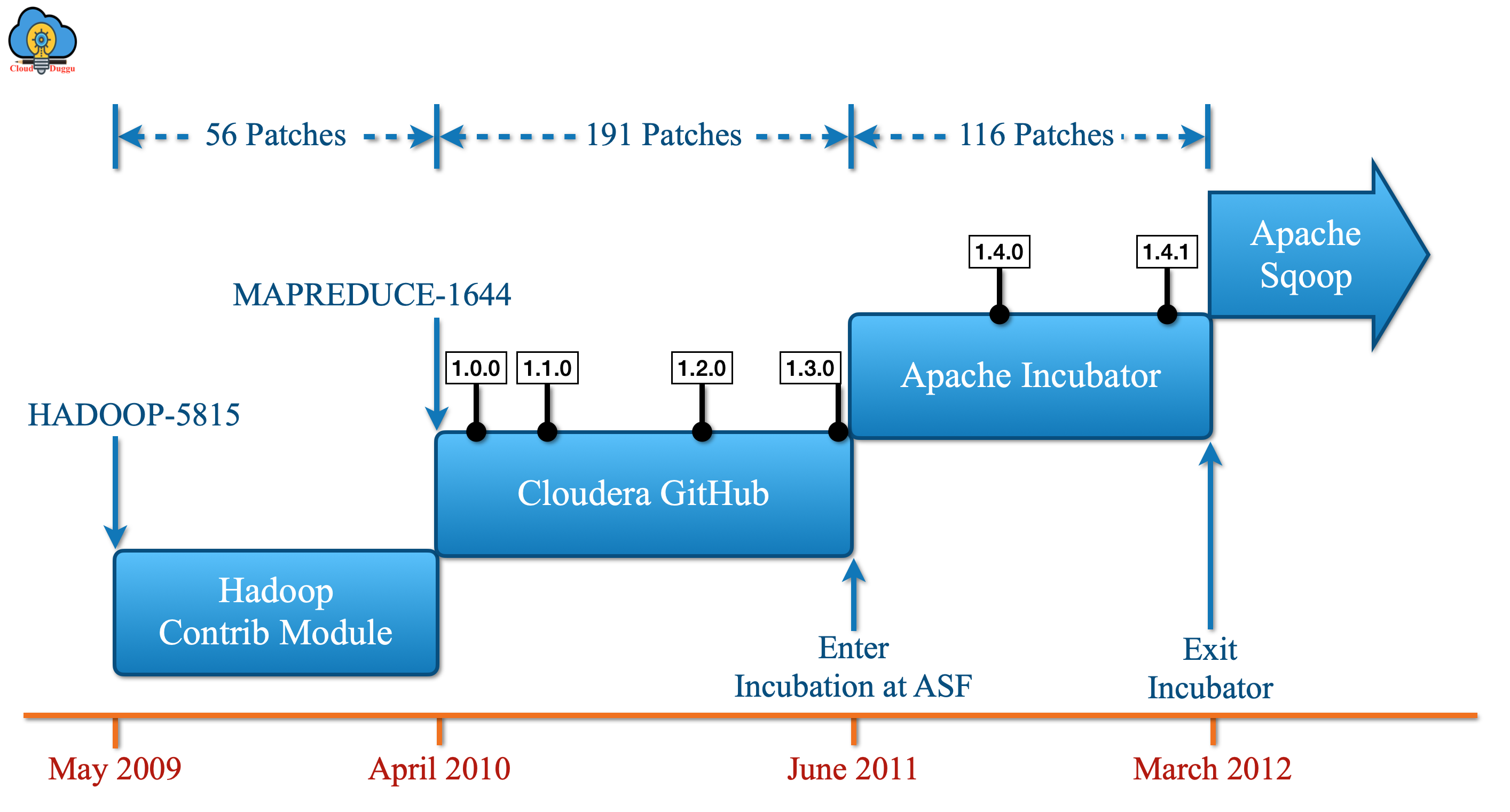
Apache Sqoop History
Let us see a year by year evaluation of Apache Sqoop.
2009: Sqoop started as a contrib module for Apache Hadoop.
2010: Sqoop was hosted on GitHub by Cloudera as an Apache Licensed project.
2011: Sqoop was accepted for incubation by the Apache Incubator.
2012: Sqoop becomes a top-level Apache project.
How Apache Sqoop Works?
Let us see Apache Sqoop operations with the below workflow.
- Sqoop Import
- Sqoop Export
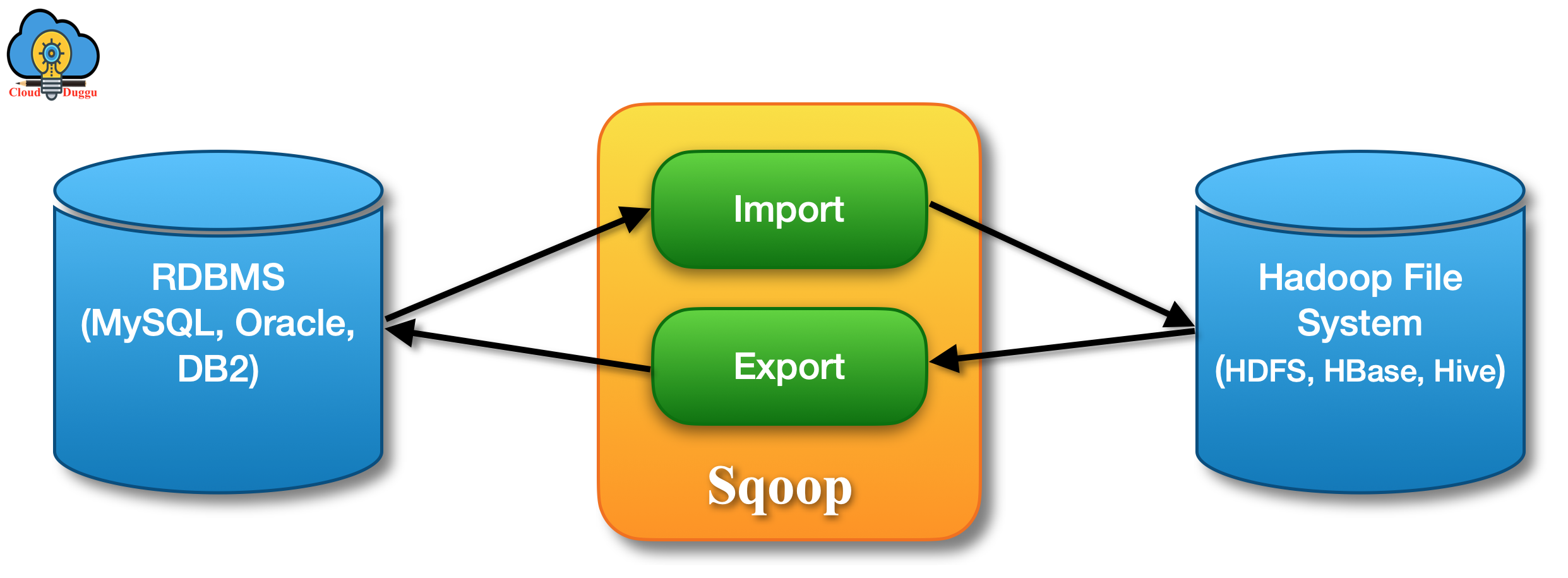
1. Sqoop Import
Import operation is used to import data in Hadoop from external data sources systems such as My SQL, Oracle, Teradata, DB2, and so on. It treats each row of the table as a record and stores it as a text file or sequence file in HDFS.
2. Sqoop Export
The export operation is used to export data from Hadoop to external data storage systems such as My SQL, Oracle, Teradata, DB2, and so on. In this operation, files are transferred using the Sqoop export tool and stored in RDBMS tables based on a user-defined delimiter.