Apache Sqoop Export takes the data files from Hadoop HDFS and transfers them to the relational database management systems. A user needs to make sure that the target table exists in the database. During Sqoop export operation, all input files are processed by reading each file based on the user request, and one thing we need to note that the default operation of Sqoop Export is INSERT. Apart from the INSERT operation, we can UPDATE the existing records and run the stored procedure using "call mode".
Export Syntax
Below syntax is used to Export data from Hadoop HDFS to RDBMS.
$ sqoop export (gene-args) (expo-args)Export Example
Let us see an example to export data from Hadoop HDFS to the MySQL database.
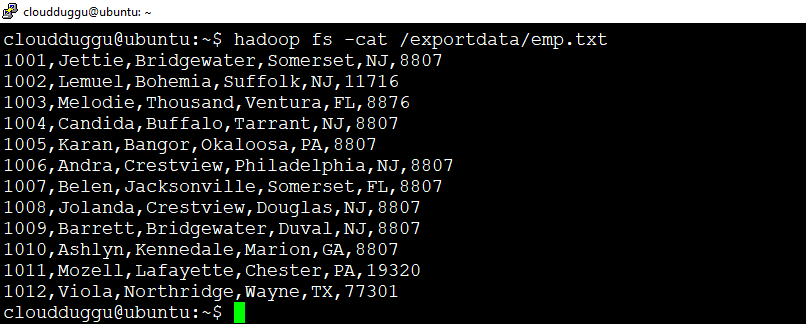
We have an “emp.txt” file present under the “/exportdata” directory of HDFS. This file has the following records.
Content of emp.txt
1001,Jettie,Bridgewater,Somerset,NJ,8807
1002,Lemuel,Bohemia,Suffolk,NJ,11716
1003,Melodie,Thousand,Ventura,FL,8876
1004,Candida,Buffalo,Tarrant,NJ,8807
1005,Karan,Bangor,Okaloosa,PA,8807
1006,Andra,Crestview,Philadelphia,NJ,8807
1007,Belen,Jacksonville,Somerset,FL,8807
1008,Jolanda,Crestview,Douglas,NJ,8807
1009,Barrett,Bridgewater,Duval,NJ,8807
1010,Ashlyn,Kennedale,Marion,GA,8807
1011,Mozell,Lafayette,Chester,PA,19320
1012,Viola,Northridge,Wayne,TX,77301
Now we will create a table named "employee" under the “userdata” database in MySQL to store these file records.
Command:
mysql> CREATE TABLE employee (empid int, empname VARCHAR(20),city VARCHAR(20), county VARCHAR(20), state VARCHAR(20), zip int);
Let us import data from HDFS directory “/exportdata/emp.txt” into MySQL “employee” table.
Command:
cloudduggu@ubuntu:~$ sqoop export --connect jdbc:mysql://localhost/userdata?serverTimezone=UTC --username root--password cloudduggu --table employee --export-dir /exportdata/emp.txt

Output:
2020-07-20 08:31:20,918 INFO mapreduce.Job: Running job: job_1595247619306_0004
2020-07-20 08:32:01,351 INFO mapreduce.Job: Job job_1595247619306_0004 running in uber mode : false
2020-07-20 08:32:01,357 INFO mapreduce.Job: map 0% reduce 0%
2020-07-20 08:33:23,263 INFO mapreduce.Job: map 75% reduce 0%
2020-07-20 08:33:52,682 INFO mapreduce.Job: map 100% reduce 0%
2020-07-20 08:33:53,707 INFO mapreduce.Job: Job job_1595247619306_0004 completed successfully
2020-07-20 08:33:54,252 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=899788
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1773
HDFS: Number of bytes written=0
HDFS: Number of read operations=19
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
Job Counters
Launched map tasks=4
Data-local map tasks=4
Total time spent by all maps in occupied slots (ms)=514730
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=257365
Total vcore-milliseconds taken by all map tasks=257365
Total megabyte-milliseconds taken by all map tasks=527083520
Map-Reduce Framework
Map input records=12
Map output records=12
Input split bytes=541
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=4498
CPU time spent (ms)=22430
Physical memory (bytes) snapshot=485326848
Virtual memory (bytes) snapshot=13624311808
Total committed heap usage (bytes)=130285568
Peak Map Physical memory (bytes)=132571136
Peak Map Virtual memory (bytes)=3406077952
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2020-07-20 08:33:54,310 INFO mapreduce.ExportJobBase: Transferred 1.7314 KB in 166.8563 seconds (10.6259
bytes/sec)
2020-07-20 08:33:54,333 INFO mapreduce.ExportJobBase: Exported 12 records.
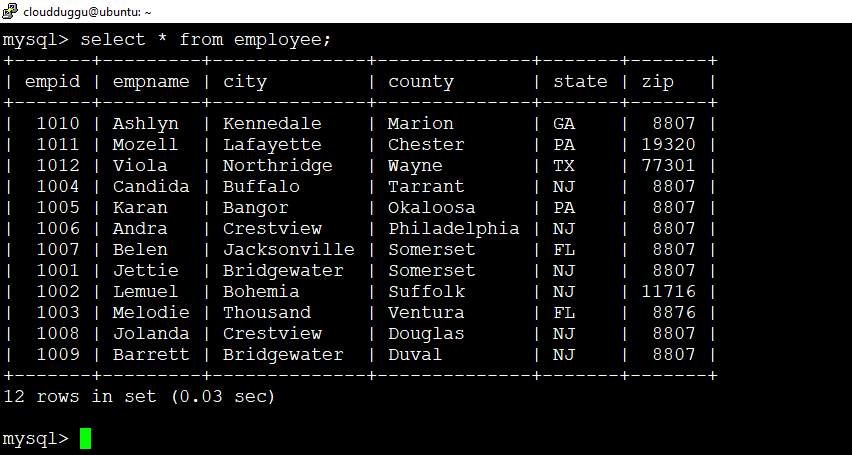
We can verify output in the MySQL database.
mysql> select * from employee;