Apache Pig provides Order By and Limit operators to perform shorting and restricting the relations.
We have used the “finance_data.txt” dataset to perform these operations. We will put “finance_data.txt” in the HDFS location “/pigexample/” from the local file system.
Content of “finance.txt”:
1,Chanel,Shawnee,KS,9133882079
2,Ezekiel,Easton,MD,4106691642
3,Willow,New York,NY,2125824976
4,Bernardo,Conroe,TX,9363363951
5,Ammie,Columbus,OH,6148019788
6,Francine,Las Cruces,NM,5059773911
7,Ernie,Ridgefield Park,NJ,2017096245
8,Albina,Dunellen,NJ,7329247882
9,Alishia,New York,NY,2128601579
10,Solange,Metairie,LA,5049799175
We will load “finance.txt” from the local filesystem into HDFS “/pigexample/” using the below commands.
Command:
$hadoop fs -copyFromLocal /home/cloudduggu/pig/tutorial/finance.txt /pigexample/
Now we will create a relation and load data from HDFS to Pig.
Command:
grunt> findata = LOAD '/pigexample/finance_data.txt' USING PigStorage(',') as (empid:int,empname:chararray,city:chararray,state:chararray,phone:int );
1. ORDER BY
ORDER BY operator is used to short the content of the relation based on one or more fields.
Syntax:
grunt> alias = ORDER alias BY { * [ASC|DESC] | field_alias [ASC|DESC] [, field_alias [ASC|DESC] …] } [PARALLEL n];
We will perform ORDER BY operation on relation “findata” using the state column.
Command:
grunt> orderdata = ORDER findata BY state DESC;
Output:
Now we will use the DUMP operator to print the output of relation “orderdata” on screen.
Command:
grunt> DUMP orderdata;
Output:
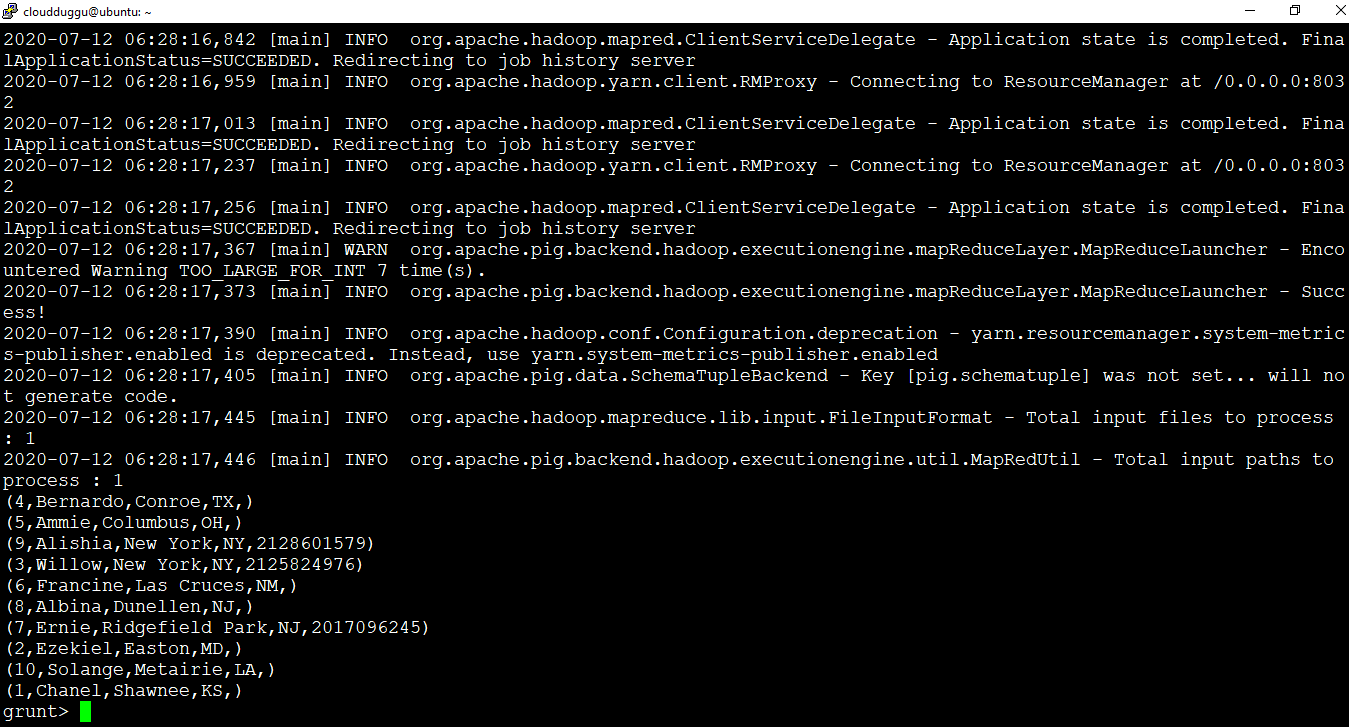
2. LIMIT
2. LIMIT
The LIMIT operator provides a limited number of tuples for a relation.
Syntax:
grunt> alias = LIMIT alias n;
We will use the LIMIT operation to restrict the output of the relation “findata” to ten rows and using the DUMP operator we will print records on the terminal.
Command:
grunt> limitdata = LIMIT findata 10;
grunt> DUMP limitdata;
Output: