Apache Pig Latin is a dataflow language that allows users to describe how data should be read, processed, and then stored in Hadoop. It provides multiple operators such as comparison operators, arithmetic operators, data types, type construction operators, relational operations to perform various operations.
Apache Pig Latin Statements
Apache Pig Latin statements are the basic concepts you use to process data using Pig. It is an operator that takes a relation as input and produces another relation as output. Pig Latin statements can include expressions and schemas. Pig Latin statements can be multiple in lines and should end with a semi-colon (;). Pig Latin statements are processed using multi-query execution by default.
Apache Pig statements are structured as follows.
Let us see each step in detail.
1. Load
A LOAD statement is used to read data from the file system such as HDFS as local file system into Pig. PigStorage is the default load function.
Suppose we have to create a file name “num.txt” which is tab-delimited and stored at the local file system (In our case /home/cloudduggu/pig).
1 2 3
5 4 7
8 6 4
4 2 1
8 3 4
We will use the default function PigStorage to load data from “num.txt” into the numexp variable.
Command:
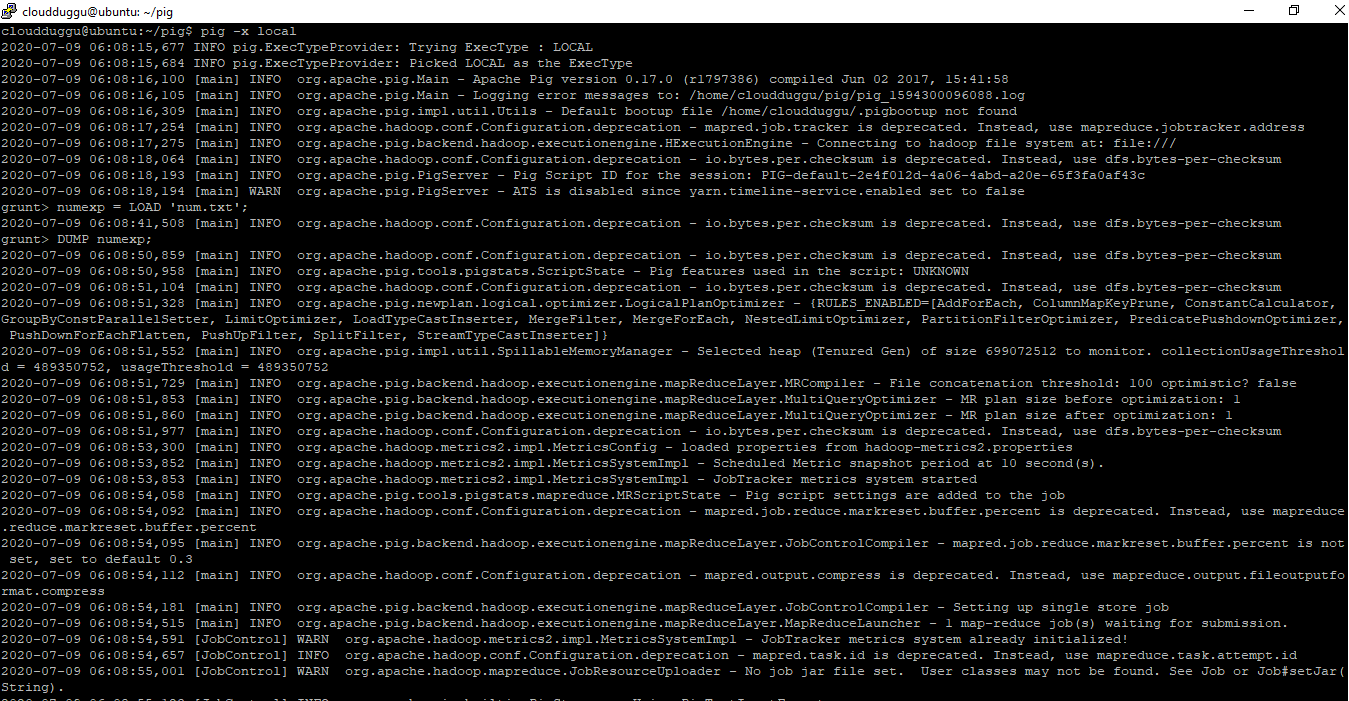
$pig -x local
grunt> numexp = LOAD ‘num.txt’;
We will use dump to see records as mentioned below, we don’t see the filed name because schema was not defined.
Command:
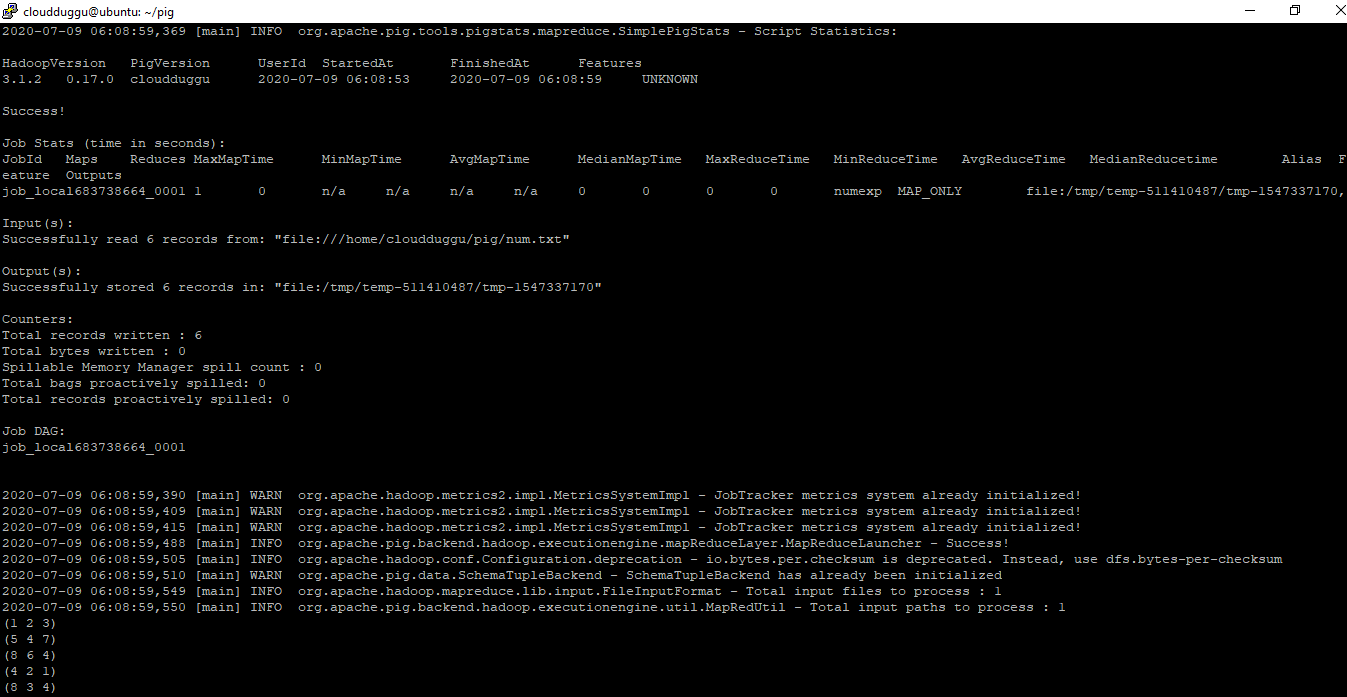
grunt> DUMP numexp
(1 2 3)
(5 4 7)
(8 6 4)
(4 2 1)
(8 3 4)
Output:
(1 2 3)
(5 4 7)
(8 6 4)
(4 2 1)
(8 3 4)
Now we will define schema using the AS keyword and use the DESCRIBE and ILLUSTRATE operators to view the schema also we will use DUMP to see the result.
Command:
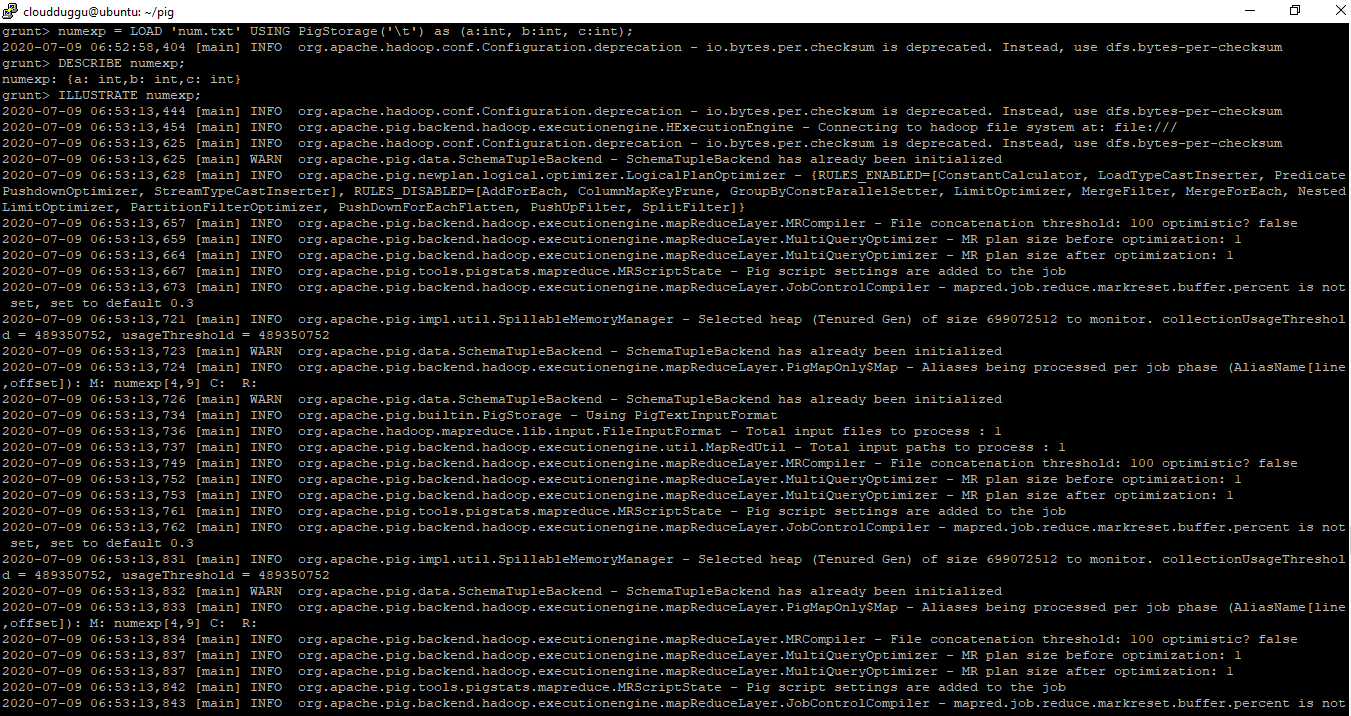
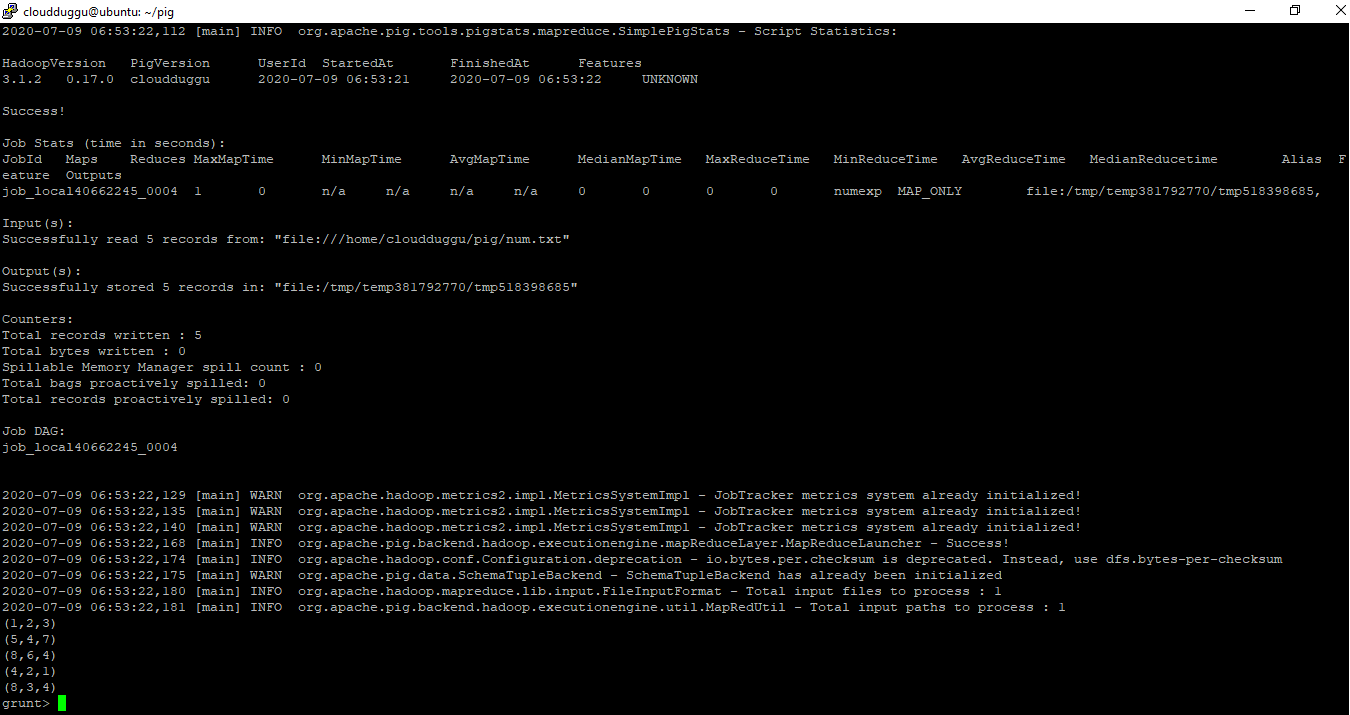
grunt> numexp = LOAD ‘num.txt’ USING PigStorage('\t') as (a:int,b:int,c:int);
grunt> DESCRIBE numexp;
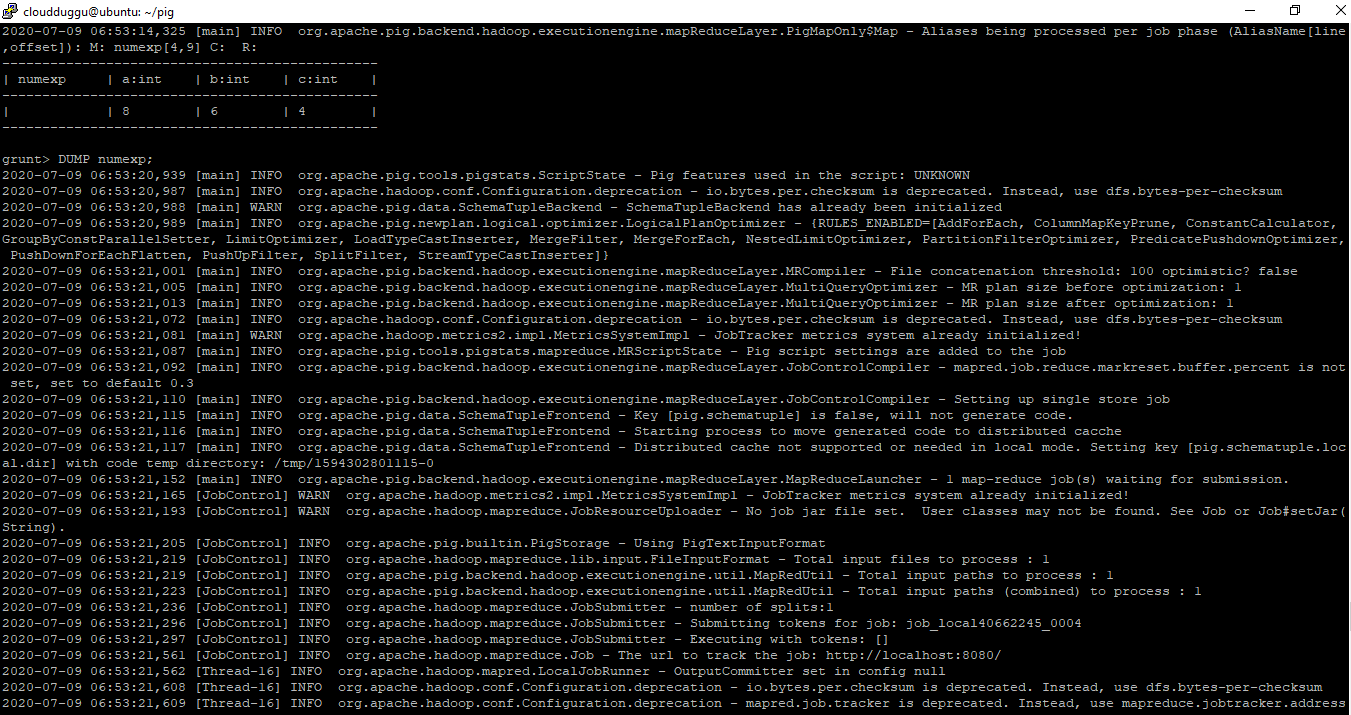
grunt> ILLUSTRATE numexp;
grunt> DUMP numexp;
Output:
2. Transformations
2. Transformations
We can perform some calculative operations on the dataset. Pig allows us to perform transform of data in various ways.
Using Filter Operator
Filter Operator is used to selecting the data that you require. We can use Filter Operator to work with tuples or rows of data.
Syntax:
grunt> alias = FILTER alias BY expression;
In this example, we will load the 'num.txt' file in local mode(pig -x local) and project the records where the third column “c” == 3.
Command:
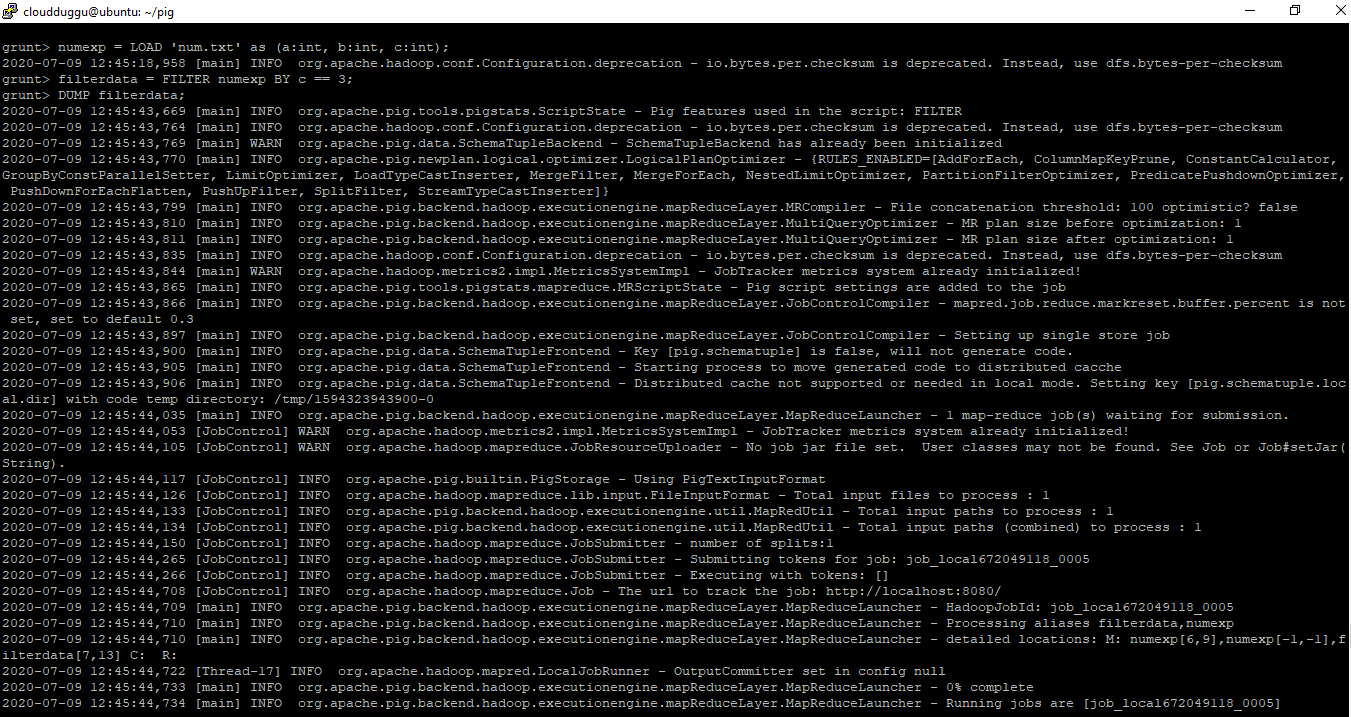
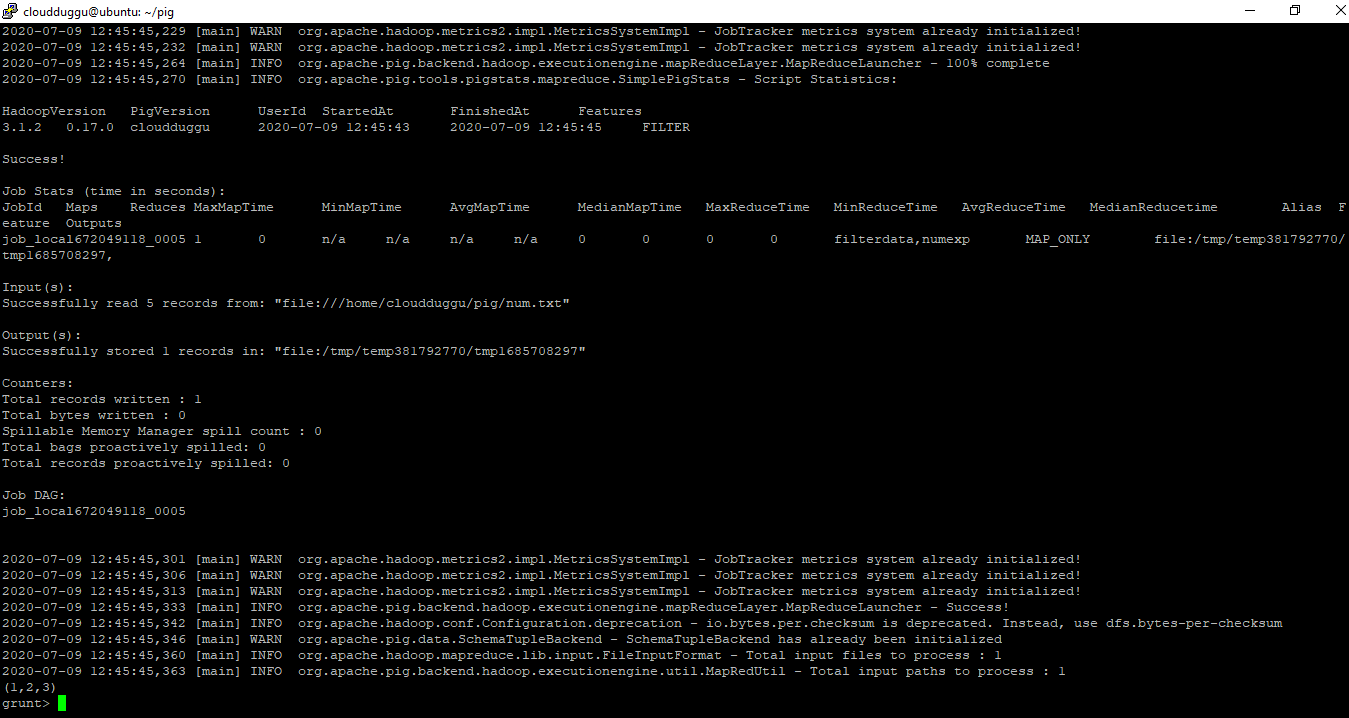
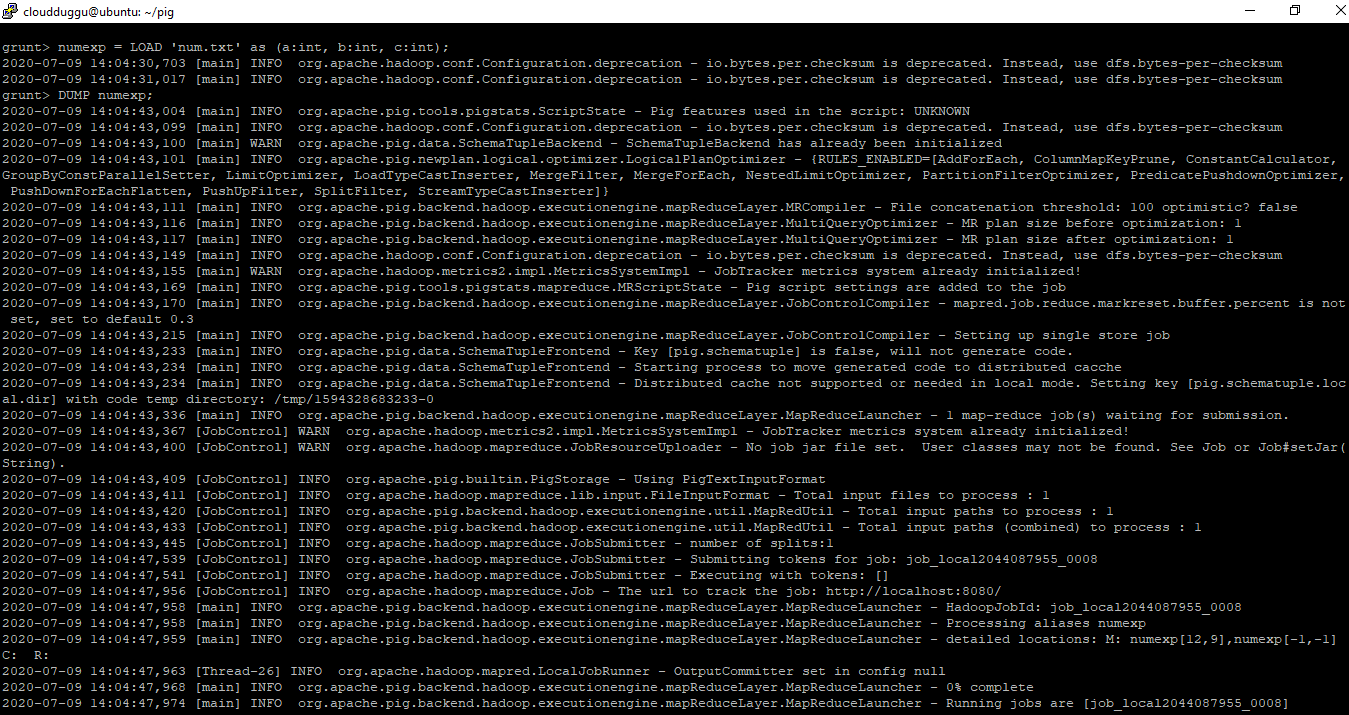
grunt> numexp = LOAD 'num.txt' as (a:int,b:int,c:int);
grunt> filterdata = FILTER numexp BY c == 3;
grunt> DUMP filterdata;
Output:
Using Group Operator
Using Group Operator
GROUP operator performs the grouping of the same group of tuples. After grouping, the result is generated as a relation that will have one tuple in each group.
Syntax:
grunt> alias = GROUP alias { ALL | BY expression} [, alias ALL | BY expression …] [USING 'collected' | 'merge'] [PARTITION BY partitioner] [PARALLEL n];
In this example, we will load the 'num.txt' file in local mode(pig -x local) and project the records by using the GROUP operator for column “c”.
Command:
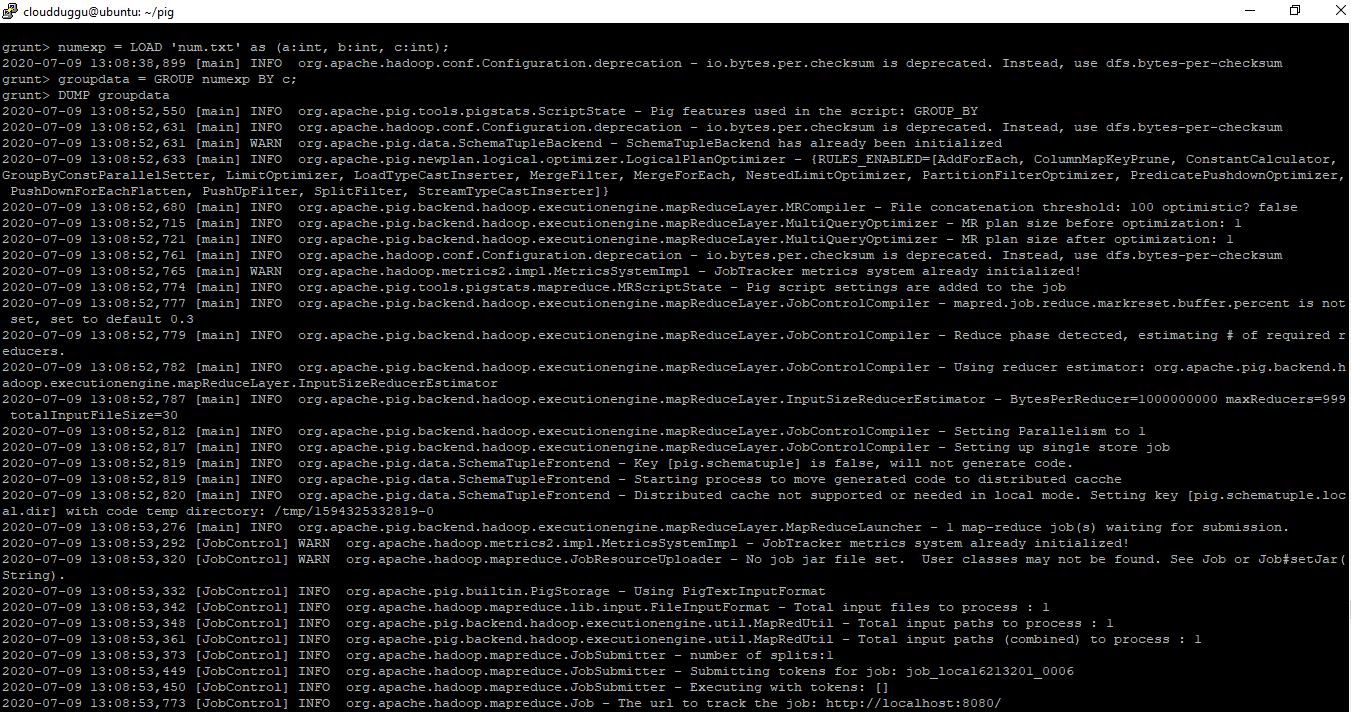
grunt> numexp = LOAD 'num.txt' as (a:int,b:int,c:int);
grunt> groupdata = GROUP numexp BY c;
grunt> DUMP groupdata;
Output:
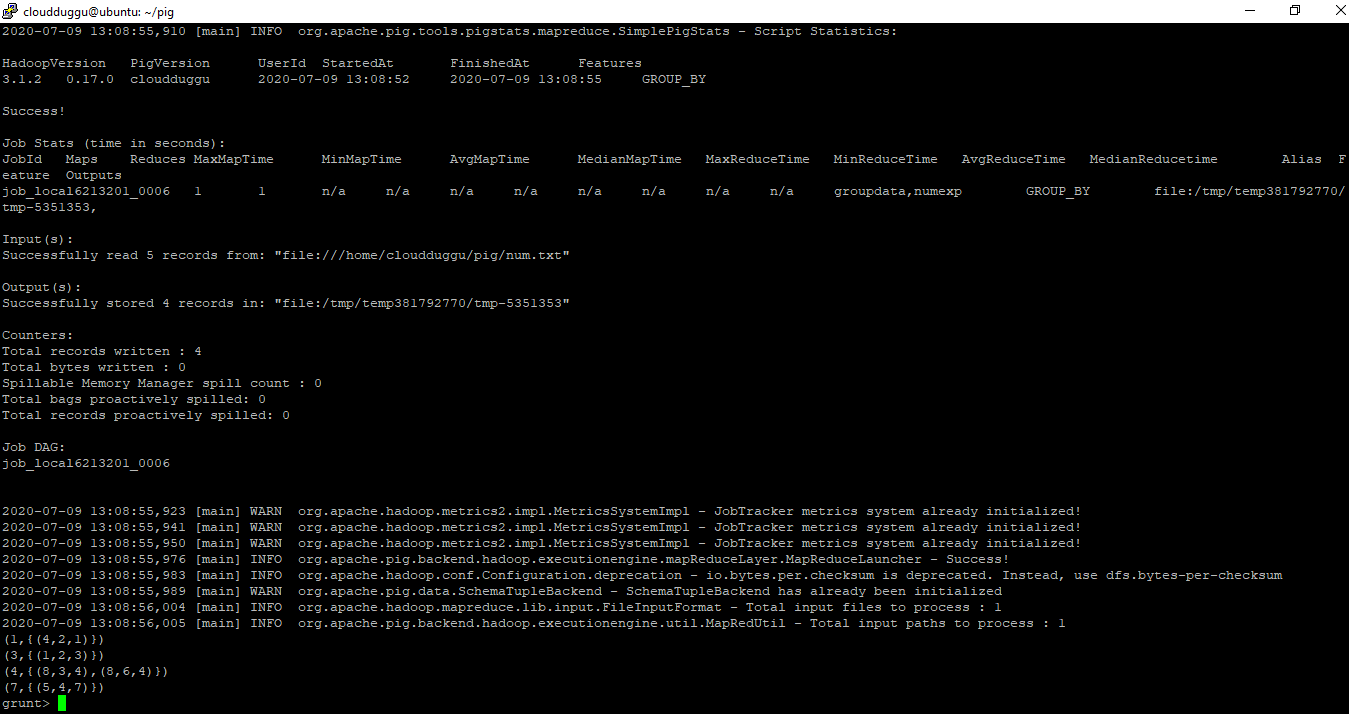
Intermediate Results
Intermediate Results
By default, Pig stores intermediate data generated between MapReduce jobs in the “/tmp” directory of HDFS.
3. Dump
A dump operator is used to display output on screen only. It is used for interactive mode, statements are executed immediately and the results are not saved (persisted). Dump can be used as a debugging device to make sure that the results you are expecting are generated.
Syntax:
grunt> DUMP alias;
Command:
grunt> numexp = LOAD 'num.txt' as (a:int,b:int,c:int);
grunt> DUMP numexp;
Output:
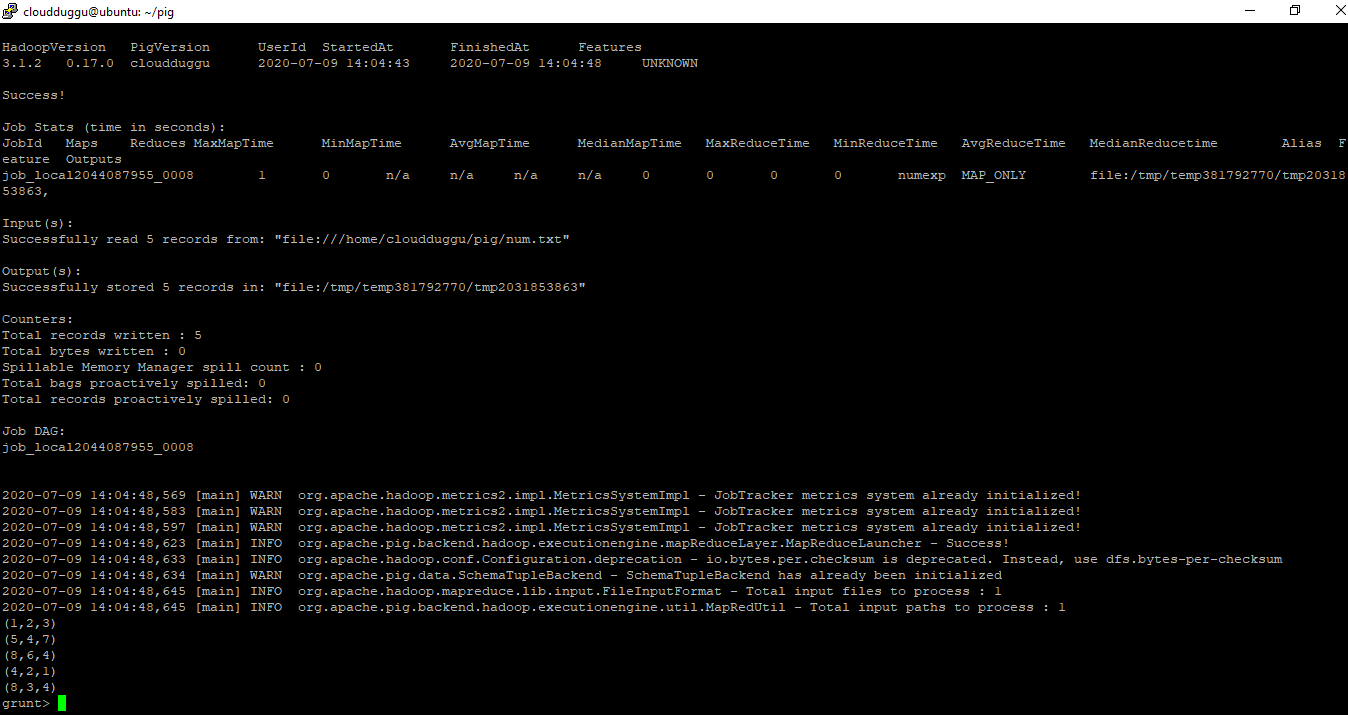
4. STORE Operator
grunt> DUMP numexp;
Output:
4. STORE Operator
By using the STORE operator we can run Pig Latin statements and save results to the file system.
In this example, we will load 'num.txt' in the numexp variable and then we will store the output of this file in another file “numstore.txt” using the Store operator.
Syntax:
grunt> LOAD 'data' [USING function] [AS schema];
Command:
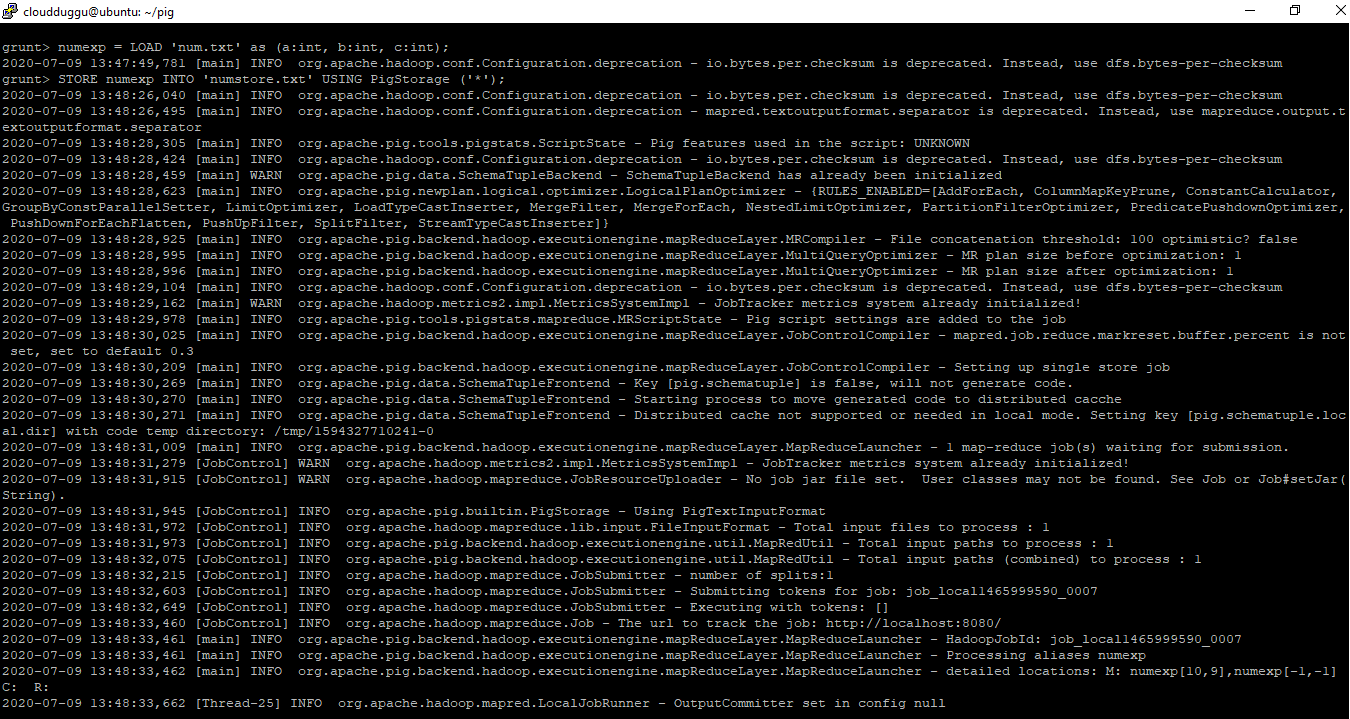
grunt> numexp = LOAD 'num.txt' as (a:int,b:int,c:int);
grunt> STORE numexp INTO 'numstore.txt' USING PigStorage ('*');
grunt> cat numstore.txt;
Output:
Apache Pig Latin Simple Data Types
grunt> STORE numexp INTO 'numstore.txt' USING PigStorage ('*');
grunt> cat numstore.txt;
Output:
Apache Pig Latin Simple Data Types
Apache Pig Latin supports the below list of Simple Datatypes.
| Simple Data Types | Description | Example Of Data Types | int | It represents signed 32-bit integer | 100 | long | It represents signed 64-bit integer | Data: 100L or 100l, Display: 100L | float | It represents 32-bit floating point | Data: 10.5F or 10.5f or 10.5e2f or 10.5E2F, Display: 10.5F or 1050.0F | double | It represents 64-bit floating point | Data: 10.5 or 10.5e2 or 10.5E2,Display: 10.5 or 1050.0 | chararray | It represents character array (string) in Unicode UTF-8 format | hello cloudduggu | bytearray | It represents Byte array (blob) | Byte array (blob) | boolean | It represents boolean | true/false (case insensitive) | datetime | It represents datetime | 1970-01-01T00:00:00.000+00:00 | biginteger | It represents Java BigInteger | 2E+11 | bigdecimal | It represents Java BigDecimal | 33.45678332 |
|---|
Apache Pig Latin Complex Data Types
Apache Pig Latin supports the below list of Complex Datatypes.
| Complex Data Types | Description | Example Of Data Types | tuple | It is an ordered set of fields. | (19,2) | bag | It is a collection of tuples. | {(19,2), (18,1)} | map | It is a set of key value pairs. | [open#apache] |
|---|
Apache Pig Latin Arithmetic Operators
Apache Pig Latin supports the below list of Arithmetic Operators. To show an example we have assumed x=40 and y=60.
| Arithmetic Operators | Description | Example | + | addition | x +y = 100 | - | subtraction | x - y = -20 | * | multiplication | x * y= 2400 | / | division | x / y = 0.6666666 | % | modulo | Returns the remainder of a divided by b (x%y). | ? : | bincond | "y = (x == 1)? 40: 60; if x = 1 the value of y is 40. if x!=1 the value of y is 60." | CASE WHEN THEN ELSE END | case | CASE expression [ WHEN value THEN value ]+ [ ELSE value ]? END |
|---|
Apache Pig Latin Comparison Operators
Apache Pig Latin supports the below list of Comparison Operators.
| Arithmetic Operators | Description | Example | == | equal | (x == y) | != | not equal | (x != y) | < | less than | (x < y) | > | greater than | (x > y) | <= | less than or equal to | (x <= y) | >= | greater than or equal to | (x >= y) | matches | pattern matching | It takes an expression on the left and a string constant on the right expression matches string-constant. |
|---|
Apache Pig Latin Type Construction Operators
Apache Pig Latin supports the below list of Comparison Operators.
| Arithmetic Operators | Description | Example | ( ) | tuple constructor | It is used to construct a tuple from the specified elements. It is equivalent to TOTUPLE. Example (name, age); (joe smith,40); | { } | bag constructor | It is used to construct a bag from the specified elements. It is equivalent to TOBAG. Example {(name, age)}, {(name, age)}; {(joe smith,40),(joan wick,45)}; | [ ] | map constructor | It is used to construct a map from the specified elements. It is equivalent to TOMAP. Example [name,age];[name#joan,age#45]; |
|---|
Apache Pig Latin Relational Operators
Apache Pig Latin supports the below list of Relational Operators.
| Relational Operators | Description | LOAD | This operator is used to load data from the file system (local/HDFS) into a relation. | STORE | This operator is used to save a relation to the file system (local/HDFS). | FILTER | This operator is used to remove unwanted rows from a relation. | DISTINCT | This operator is used to remove duplicate rows from a relation. | FOREACH, GENERATE | This operator is used to generate data transformations based on columns of data. | STREAM | This operator is used to transform a relation using an external program. | JOIN | This operator is used to join two or more relations. | COGROUP | This operator is used to group the data in two or more relations. | GROUP | This operator is used to group the data in single relation. | CROSS | This operator is used to create the cross product of two or more relations. | ORDER BY | This operator arranges the relation in ascending or descending order. | LIMIT | This operator is used to get a limited number of tuples from a relation. | UNION | This operator is used to combine two or more relations into a single relation. | SPLIT | This operator is used to split a single relation into two or more relations. | DUMP | This operator is used to print the contents of a relation on the console. | DESCRIBE | This operator is used to describe the schema of a relation. | EXPLAIN | Using this operator we can see the physical and logical view of an execution plan. | ILLUSTRATE | This operator shows all steps of execution for statements. |
|---|