We can start Apache Pig in two modes, the first mode is Local and the second mode is Mapreduce or HDFS.
Let us see each mode in detail.
1. Local Mode
In this mode of execution, we need a single machine and all files are installed and run using your localhost and file system. This mode is used for testing and development purposes. The local mode does not need HDFS or Hadoop.
To start Local mode type the below command.
$pig -x local
2. Mapreduce Mode
Mapreduce is the default mode of the Apache Pig Grunt shell. In this mode, we need to load data in HDFS and then we can perform the operation. When we run the Pig Latin command on that data, a MapReduce job is started in the back-end to operate.
To start the Mapreduce mode type the below command.
$pig -x mapreduceor
$pig
Apache Pig Execution Methods
A user can execute Apache Pig Latin scripts in three ways as mentioned below.
1. Interactive Mode (Grunt shell)
In this mode, a user can interactively run Apache Pig using the Grunt shell. Users can submit commands and get a result there only.
Let us see the below example. We are running the below statements in interactive mode and getting output there only.
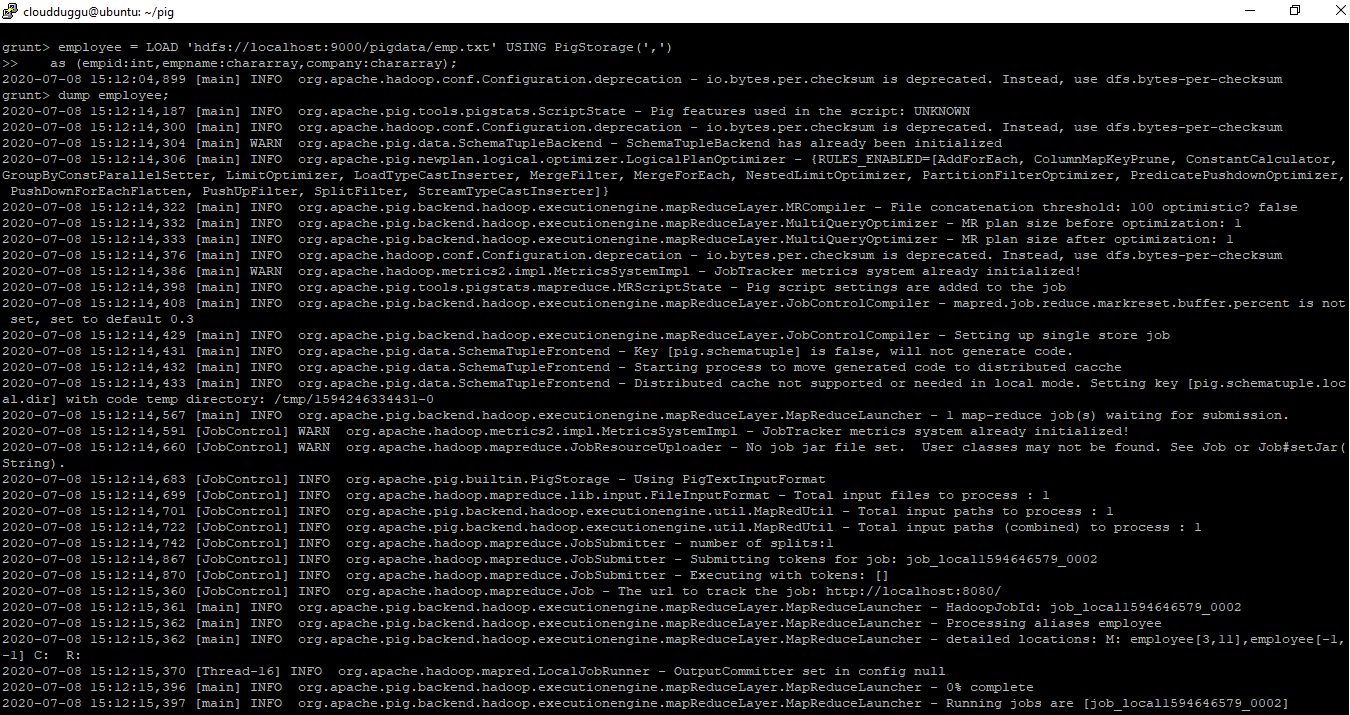
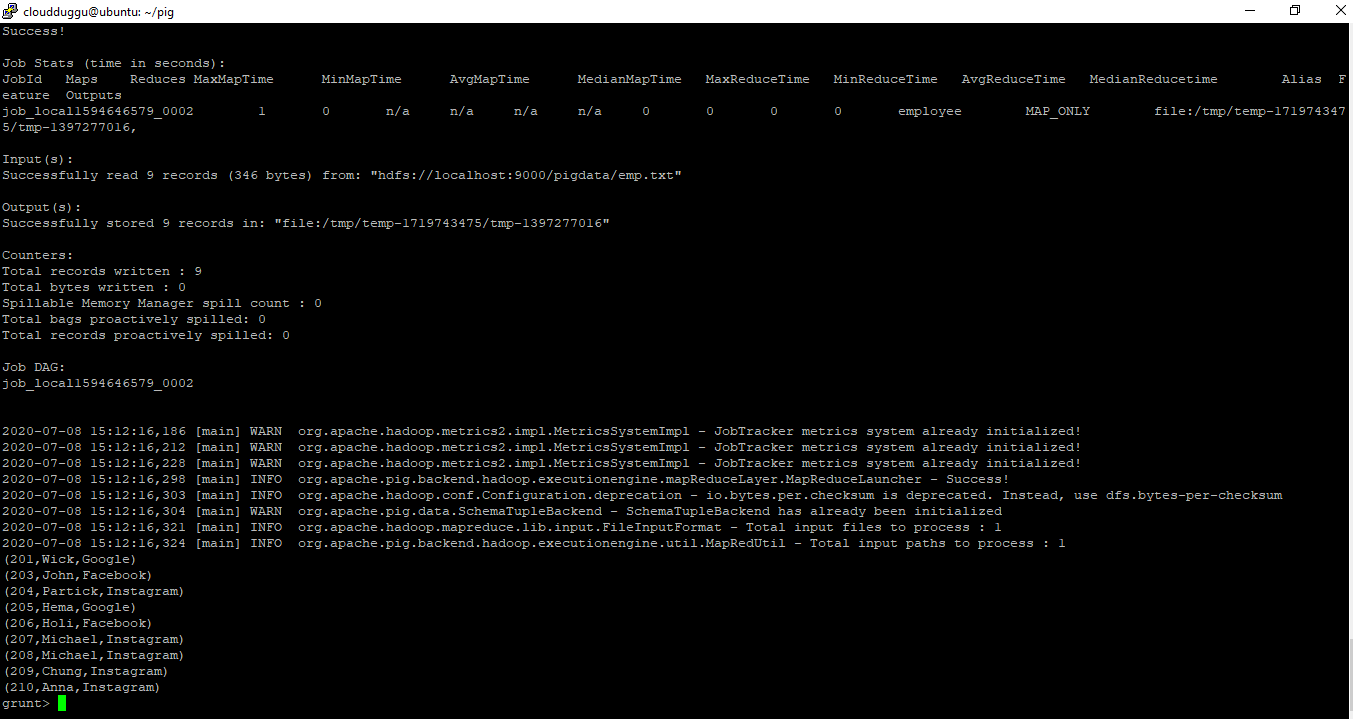
Command:
grunt> employee = LOAD 'hdfs://localhost:9000/pigdata/emp.txt' USING PigStorage(',')
as (empid:int,empname:chararray,company:chararray);
grunt> dump employee;
Output:
2. Batch Mode (Script)
2. Batch Mode (Script)
In this mode, a user can run Apache Pig in batch mode by creating a Pig Latin script file and running it from local or MapReduce mode.
Let us see the below example. We have created a script file with the name “emp_script.pig” and placed it at the HDFS location, now we are calling that file using the batch mode command.
Command:
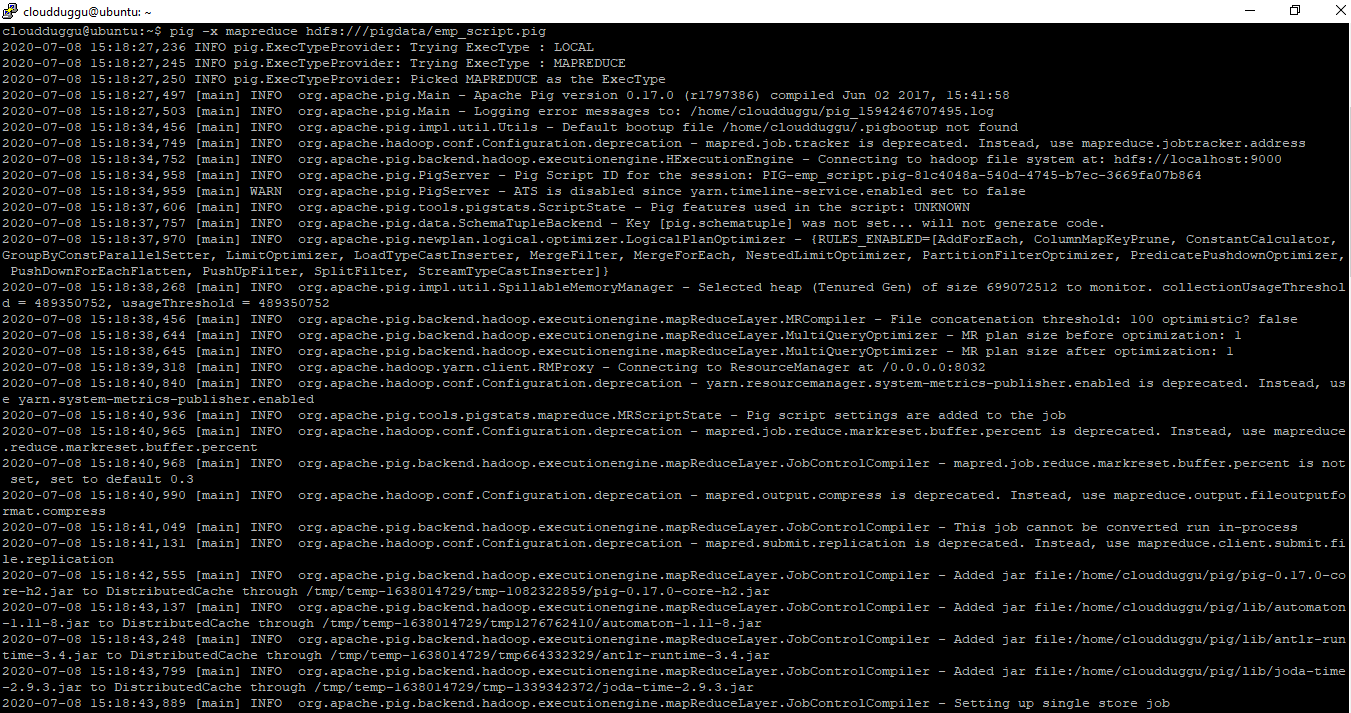
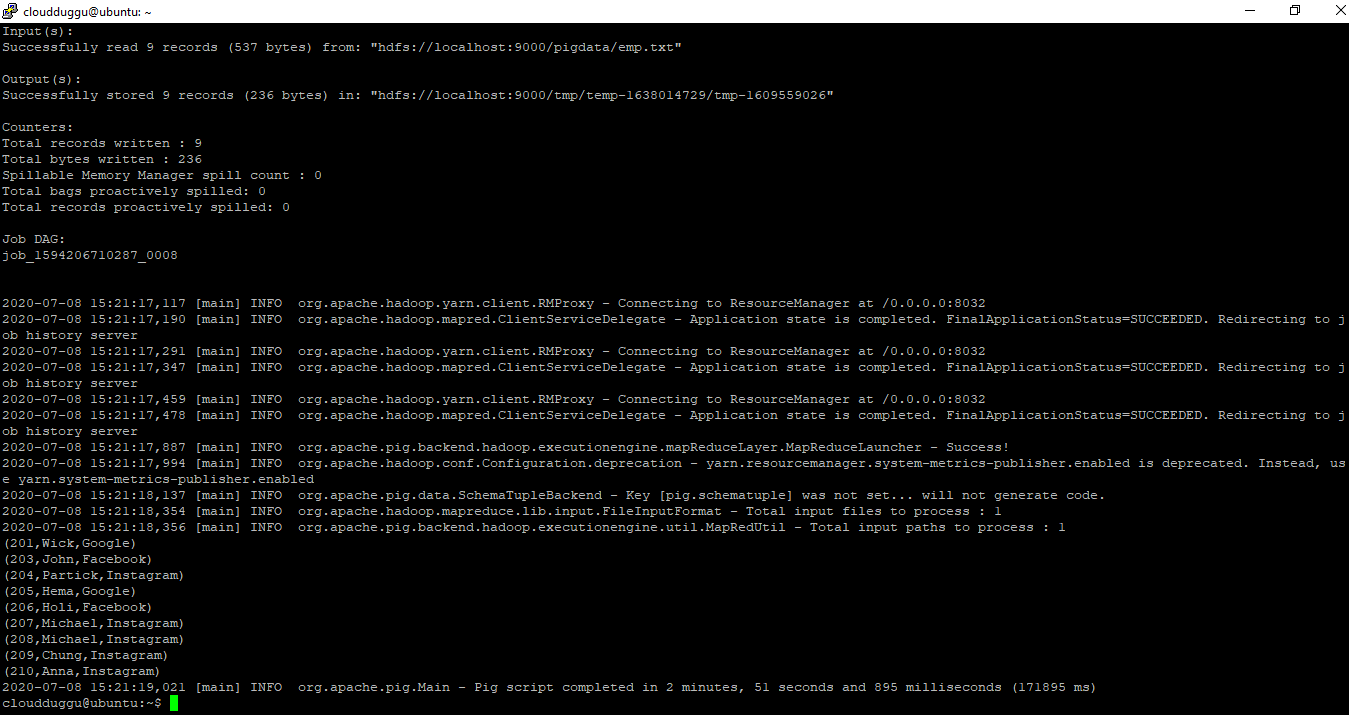
$pig -x mapreduce hdfs:///pigdata/emp_script.pig
Output: