What is Apache Flume?
Apache Flume is a distributed, reliable, and available system that is used for efficiently collecting, aggregating, and moving large amounts of log data from many different sources to a centralized data store. It is based on stream-oriented data flow technology which collects logs from all specified servers and loads them on central storage, such as Hadoop's Hadoop distributed file system. Flume is suitable for building a Hadoop-based Big Data Analysis System.
History of Apache Flume
Let us see a year by year evaluation of Apache Flume.
- 2011: Flume was first introduced in Cloudera's CDH3 distribution.
- 2011: In June, Cloudera moved control of the Flume project to the Apache Foundation.
- 2012: Refactor of Flume was done under the Star-Trek-themed tag, Flume-NG(Flume the Next Generation).
Core Objective of Apache Flume
Apache Flume is a Big Data tool that is designed to present a shared, secure, and highly available system to collect data from the different source systems and perform the aggregation on that and then send those data to a centralized system.
Apache Flume introduces the following summary of concepts.
- Event: An event is a representation of data that is transferred by Flume from its origin to its destination.
- Flow: The movement of events from the point of origin to their final destination is considered a data flow, or simply flow.
- Client: It is an interface implementation that operates at the point of origin of events and delivers them to a Flume agent.
- Agent: It is an independent process that hosts flume components such as sources, channels, and sinks, and thus can receive, store and forward events to their next-hop destination.
- Source: It is an interface implementation that can consume events delivered to it via a specific mechanism. If we take an example of Avro source that receives Avro events from the source system.
- Channel: It is a transient to store the upcoming event. The events are present in the channel unless the sink consumes it.
- Sink: It is an interface implementation that can remove events from a channel and transmit them to the next agent in the flow, or the event’s final destination.
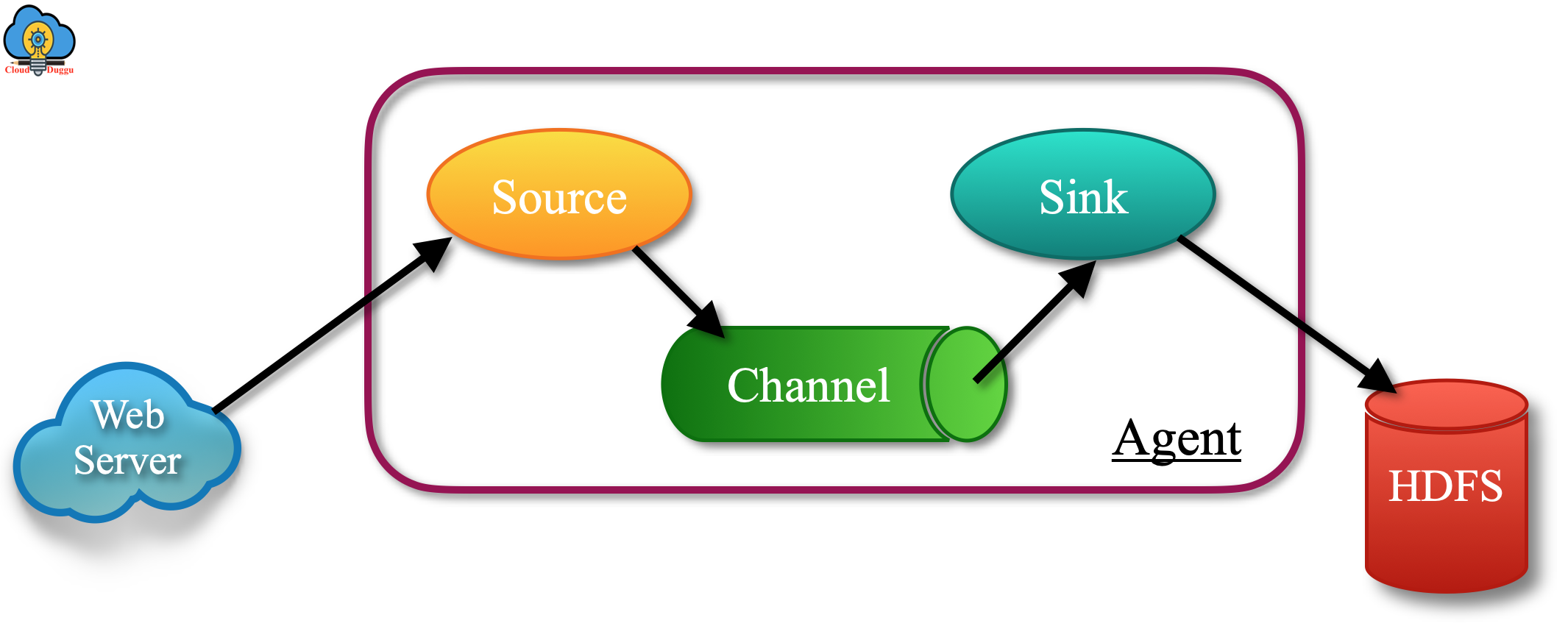
Flow Pipeline of Apache Flume
In Apache Flume a flow pipeline starts from the client that transmits the event to its next-hop destination which is an agent. Now agent will receive the event generated from the client and transfer it to more or multiple channels. Now the sinks will consume data from channels and deliver it to the next destination. In case the sink type is regular then it will send the event to another agent and in case the sink is terminal type them it will send the events to the destination.
If there is a configuration to send an event to multiple channels then flows can fan-out to more than one destination in which the source would write the event to two channels namely Channel 1/2.
The following figure shows, how the various components of Apache Flume interact with each other within a flow pipeline.
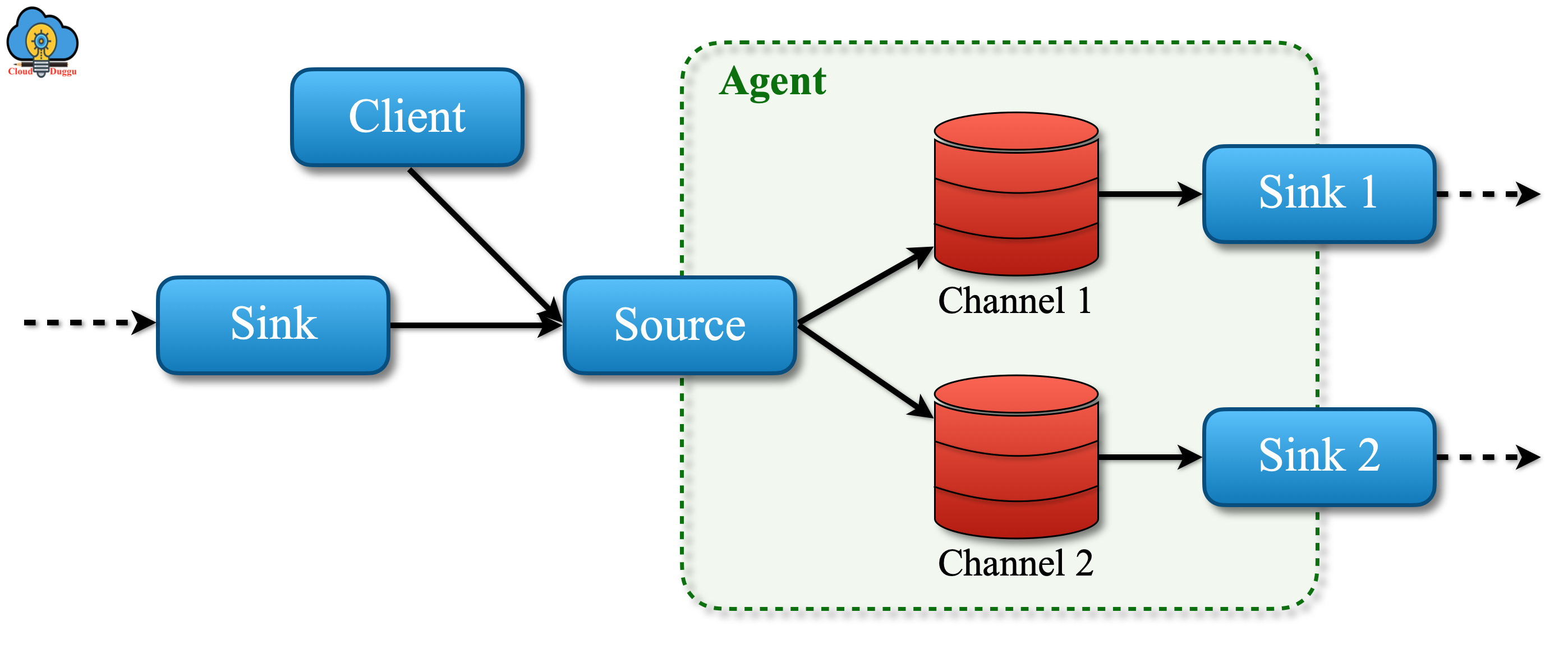
Equally the flows can be joined by having multiple sources operating within the same agent write to the same channel.
The following figure shows the physical layout of the converging flow.
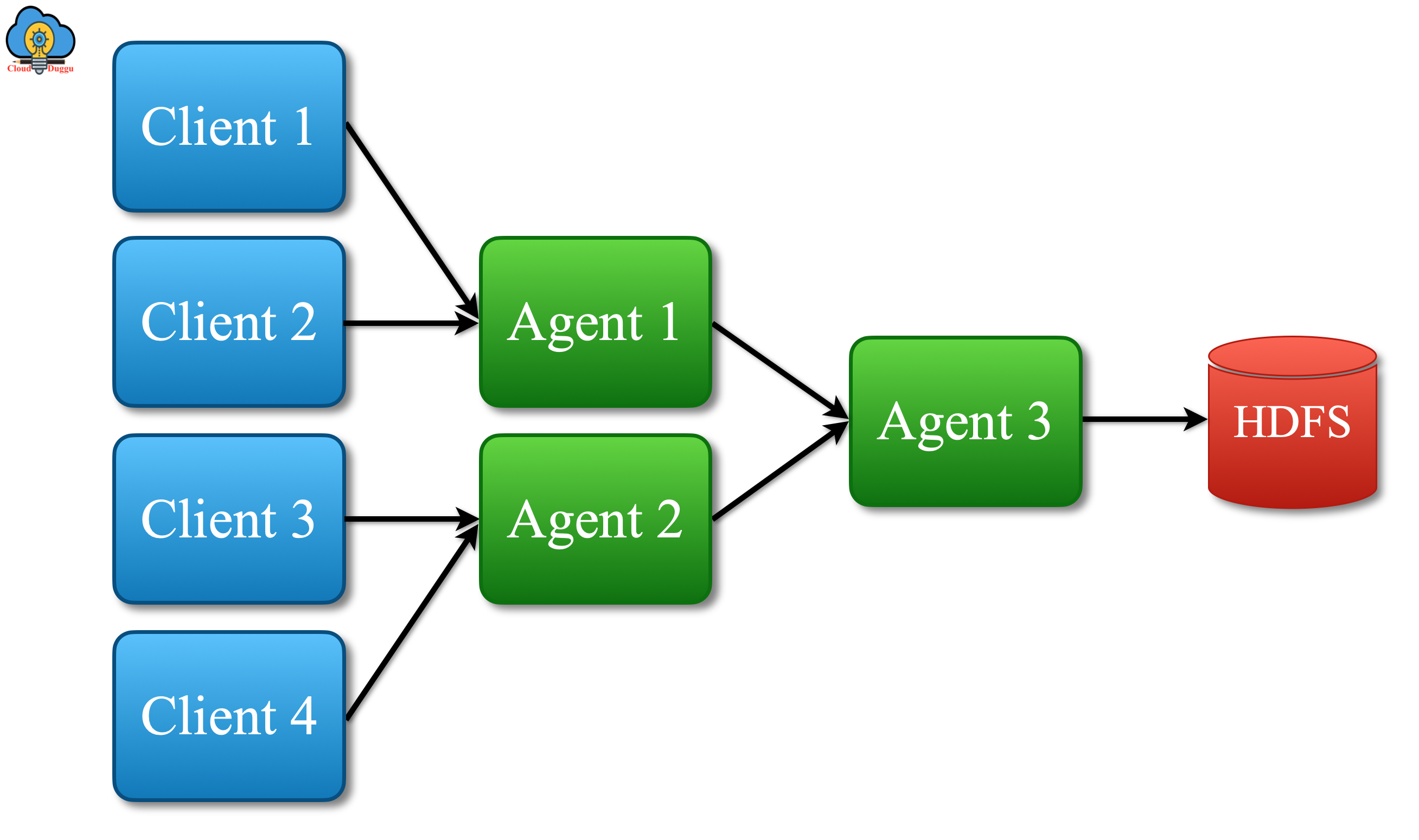
Features of Apache Flume
The following is a list of some of the important features of Apache Flume.
- Apache Flume is used to ingest data from multiple web servers in centralized storage such as Hadoop HDFS and Hbase.
- Apache Flume uses channel-based transactions to guarantee reliable message delivery.
- In case of failure, it can transmit logs without loss.
- Apache Flume provides an easy-System to add and remove agents.
- Apache Flume's data flow is based on stream-oriented data flow in which data is transferred from source to destination through a series of nodes.
- Apache Flume allows building multi-hop fan-in and fan-out flows, contextual routing, and backup routes (fail-over) for failed hops.
- Apache Flume is also used to import a huge volume of events data such as data generated by Twitter, Facebook, Amazon, Walmart.
- Apache Flume provides high throughput with low latency.
Advantage of Apache Flume
Apache Flume provides below a list of advantages.
- Flume can be easily scaled, customized, and provides a fault-tolerant and reliable features for the multiple source system and the sinks.
- Flume can scale horizontally.
- Flume provides a stable flow of data between reading and writes operations even if the read rate exceeds the write rate.
- For each message delivery, two transactions (one sender and one receiver) are maintained.
- Flume is helpful to ingested data from a variety of sources such as network traffic, social media, email messages, log files in HDFS.
- Flume can be used to ingest data from a variety of servers in Hadoop.
Disadvantage Of Apache Flume
Apache Flume architecture can become complex and difficult to manage and maintain when streaming data from multiple sources to multiple destinations. Also, Flume’s data streaming is not 100% real-time. Its alternatives like Kafka can be used if more real-time data streaming is needed. The other challenge with Apache Flume is a delicacy as it sends duplicate data as well from source to target system that is a difficult task to identify.