Apache Flume is a data streaming tool that is based on a stream-oriented data flow architecture. It is a robust, reliable, fault tolerance and distributed big data tool that is used to capture logs from various source systems and send data to a centralized destination system which are Hadoop HDFS and so on.
Apache Flume can handle the challenge of distributed systems that includes Hardware failure, network bandwidth, memory issue, CPU overflow, and so on. The data collection in Flume will continue even if there is a system down detected.
The design object of Apache Flume is,
- System Reliability: Ability to transmit without loss of log in case of failure.
- System Scalability: Easy-System to add and remove agents.
- Manageability: Combined structure makes it easy to manage.
- Feature Extensibility: Easily add new features.
Let us see the architecture of Apache Flume which shows that data is getting generated from web servers and the kind of data is event files, log files that get collected by agent (in agent we have three components such as SOURCE, CHANNEL, and SINK) and after applying aggregation, data is getting pushed to a centralized store(HDFS or HBase).
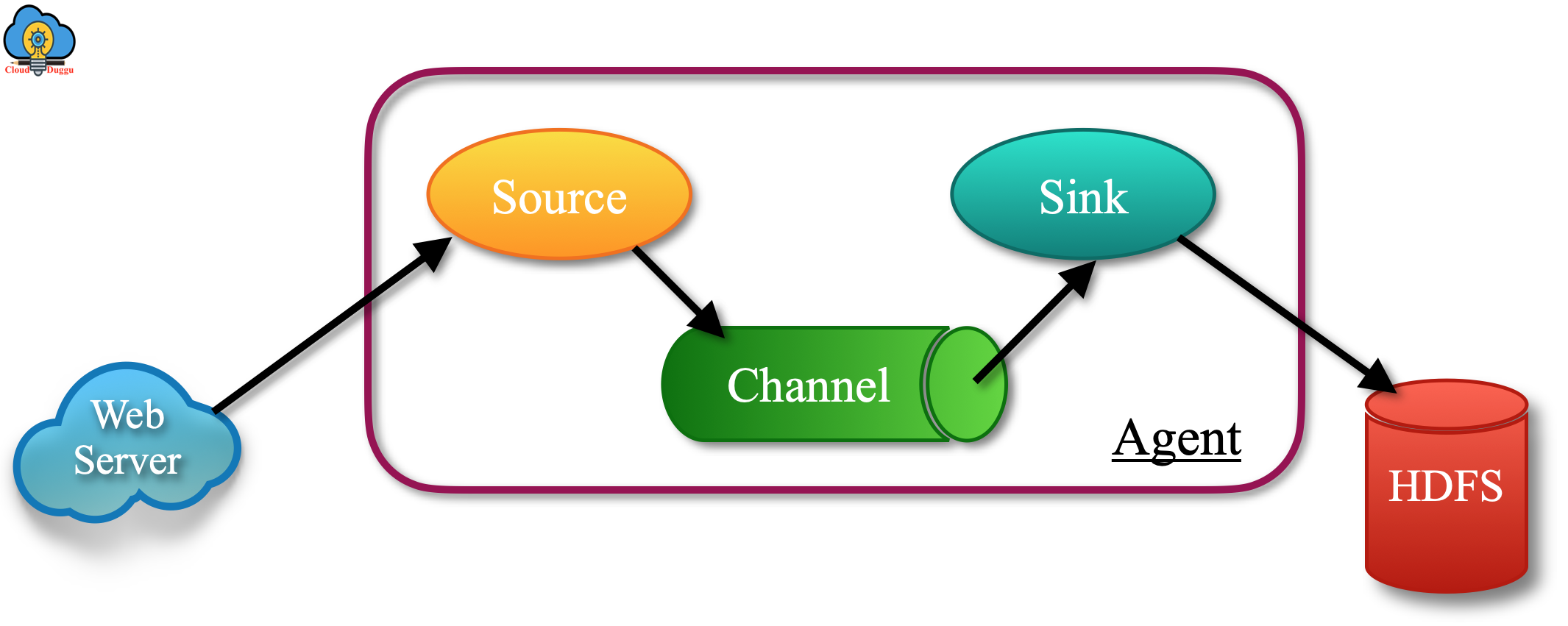
Apache Flume Data Event
An event is a form of data that Apache Flume transfers from the source system to the destination system. In this transformation process, the event has to go through different components such as source, channel, and sink.
Apache Flume Agent
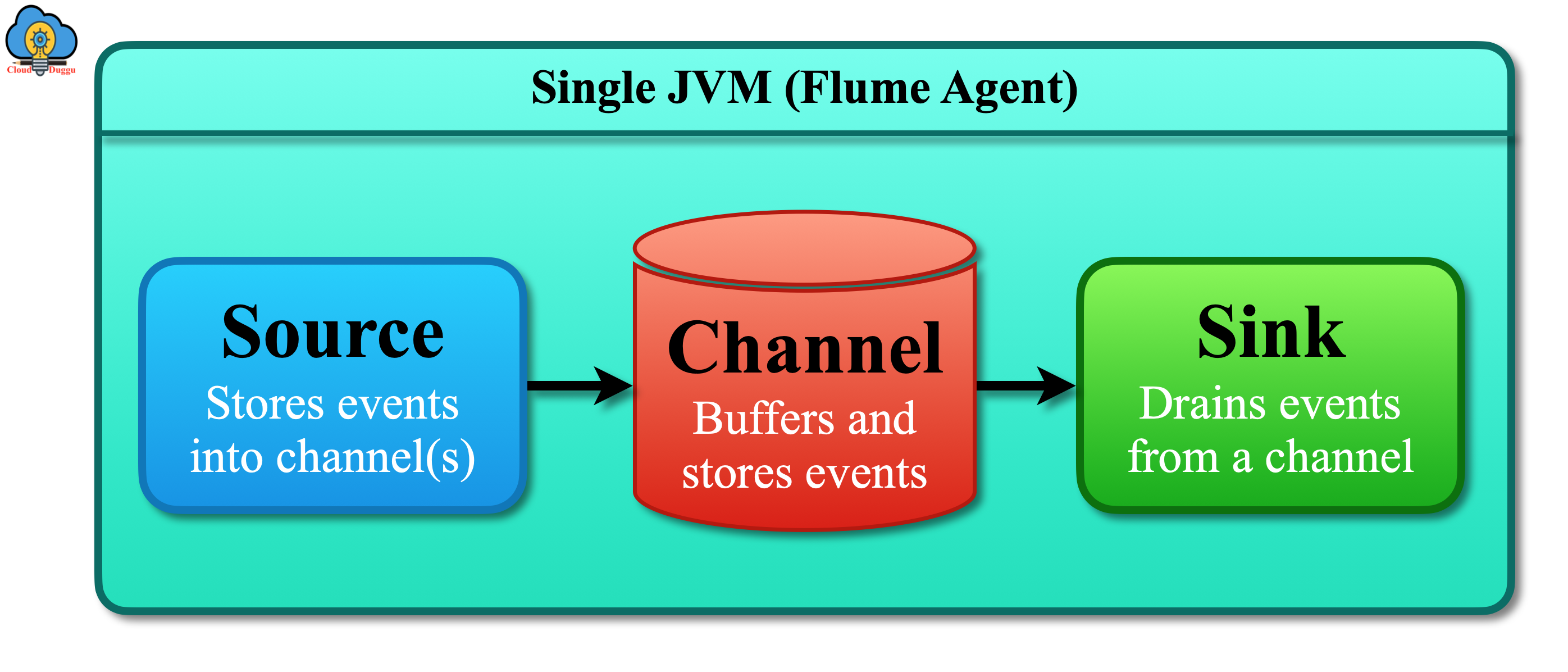
Apache Flume agent gets stream data from the different source systems and moves those data to other destinations. It is a JVM process and in production Flume architecture there can be more than one agent to transfer stream data.
Apache Flume agent has three major components.
- Source
- Channel
- Sink
1. Source
A Flume source is used to receive data from data sources such as web servers and transfer it to channels in the form of Flume events. Flume supports multiple types of sources such as Avro source, Exec source, Thrift source, NetCat source, HTTP source, Scribe source, twitter 1% source, etc.
2. Channel
Apache Flume Channel is used to store the events which are received from the source and then the same is consumed by the sink. Some Flume channels are Custom Channel, File system channel, JDBC channel, Memory channel, etc.
3. Sink
A Sink is used to remove an Event from the Channel and put it into an external repository like HDFS (in the case of an HDFSEventSink) or forward it to the next Source. Some Flume Sinks are HDFS sink, AvHBase sink, Elasticsearch sink, etc.
Apache Flume Centralized Store
The Centralized Store is the storage component where data will be stored such as Hadoop HDFS, HBase, etc.
Other Components of Flume Agent
Apache Flume provides few more components that are important while moving data from the data source system to the destination system.
Let us see additional components of the Apache Flume agent.
1. Interceptors
Interceptors are used to inspect the events which are transferred between source and channel, channel and sink. It is a part of the Flume extensibility model.
2. Channel Selectors
Channel selectors are used to deciding which channel should be selected to transfer data in case we have multiple channels.
There are two types of Channel selectors.
- Default channel selectors: These channels are used to replicate all events in each Flume channels.
- Multiplexing channel selectors: Based on the address provided in the event header, Multiplexing channel selectors decide the channel name to which an event is to be sent.
3. Sink Processors
Sink Processors are used to starting a sink from a selected group of sinks. These are useful in the creation of failover paths for our sinks and balance the loads across sinks.