Cassandra uses several stages to perform the Read and Write operation. In this section, we will go through the steps of the Read and write operation in Cassandra.
1. Read Operation in Cassandra
The Cassandra Read operation goes through different stages to find out exact data starting from the data present in the Memtable(RAM) till the data present in the SSTable(DISK) files.
The following steps are followed to read the data from Cassandra.
- The Read request will be made from the Client.
- The request data will be checked in the memtable(RAM). If the requested data is present then data will be read from memtable(RAM) and merged with SSTables(DISK) files to send final data to the client.
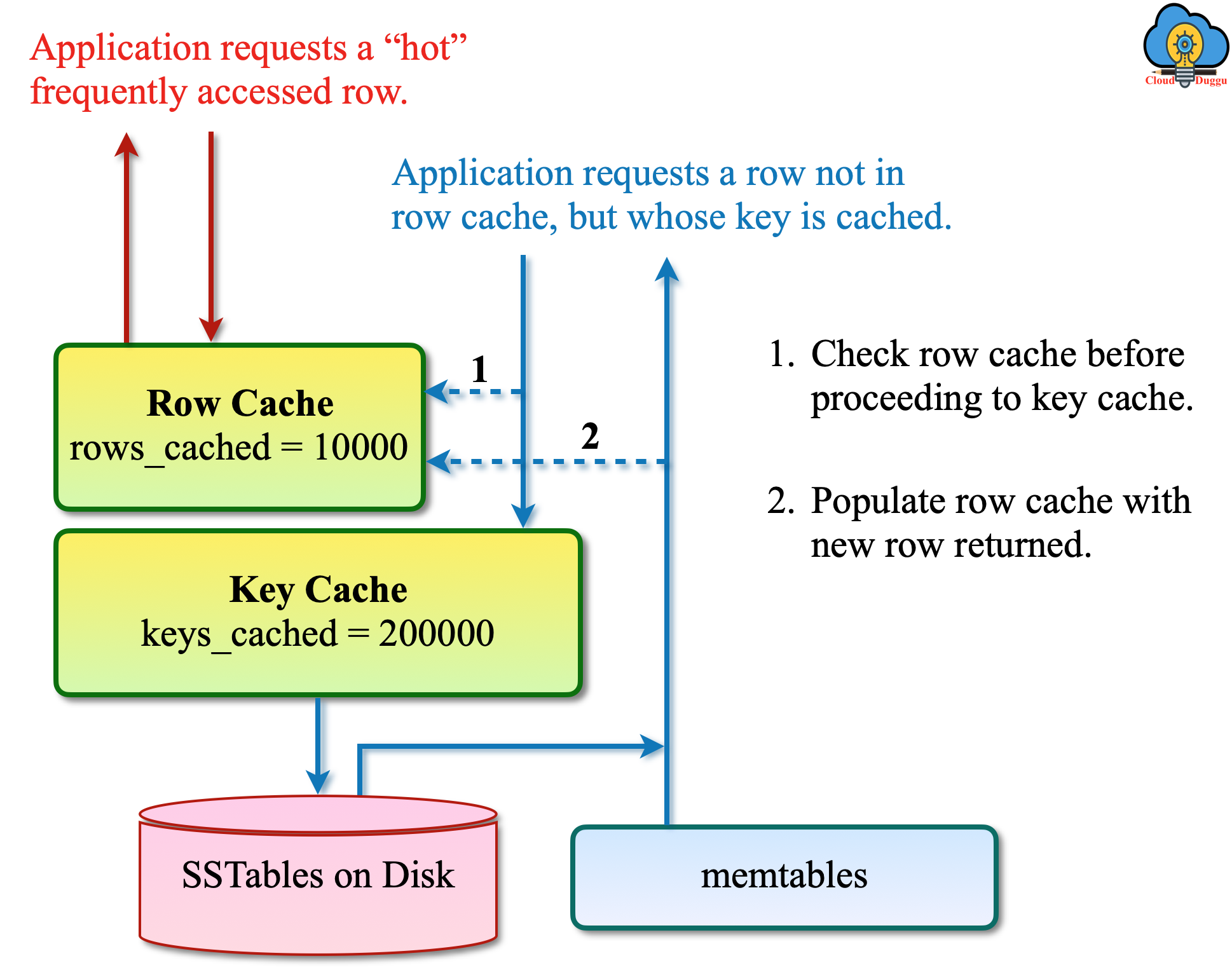
- If the row cache is enabled then it will be checked to find the data.
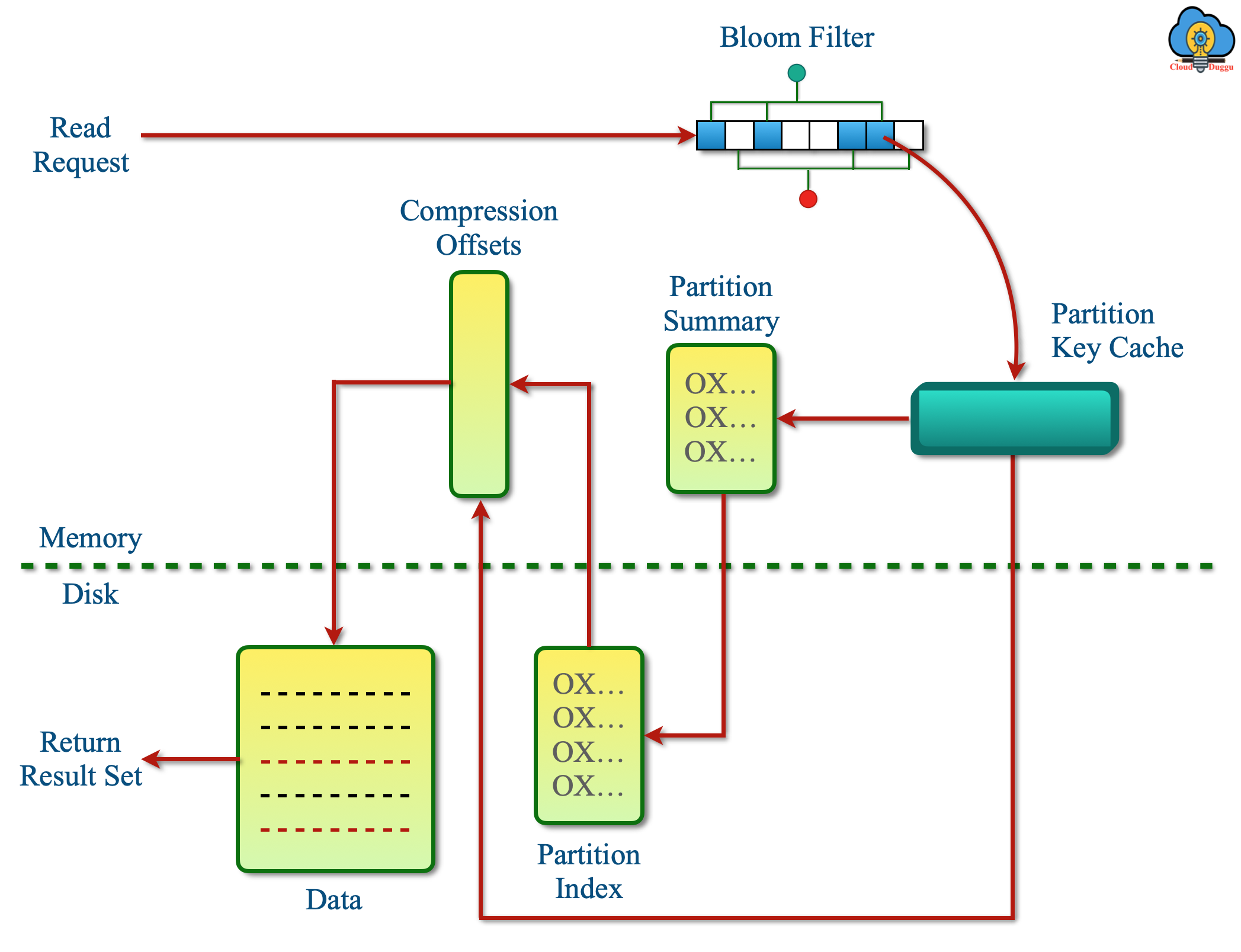
- The Bloom Filters are loaded in the Heap memory that will be checked to find out the SSTables file that can store the requested partition data. Since Bloom Filters works on probabilistic function and can return false positives. In some cases Bloom Filters does not return the SSTable file then Cassandra further checks in the partition key cache.
- The Partition Key Cache is used to store the partition index in heap memory and the partition index of data will be searched in that. If the Partition Key is present in the Partition Key Cache then Cassandra will go to compression offset to find the Disk that has the data. If the Partition Key is not present in the Partition Key Cache then the partition summary is searched to find user-requested data.
- Partition Index is used to store the Partition key of the data that will be used in the Compression offset map to find out the exact location of the Disk which has stored the data.
- The Compression offset map is used to hold the exact location of data. It uses the Partition key to locate that. Once the Compression offset map indicates the location where data is stored the further process is to fetch the data and share it with the user.
The following figure shows the flow and steps of the read operation in Cassandra.
The below figure shows the flow and steps of the read operation in Cassandra when the data will be present in the Row Cache(the frequent access data are stored here).
2. Write Operation in Cassandra
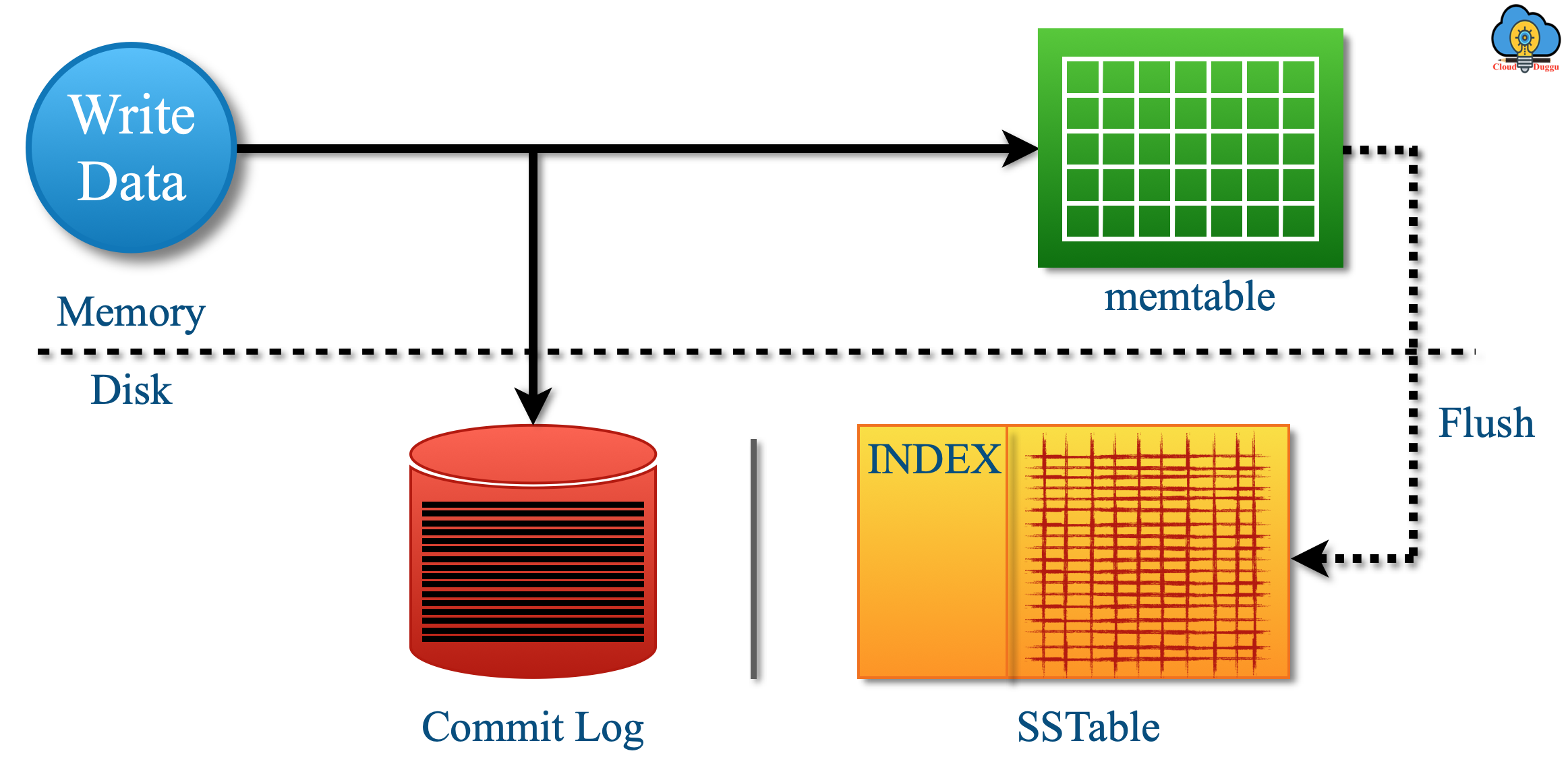
The Cassandra Write Operation follows the following steps to write data in the memtable, commit log, and then the SStables.
- Cassandra stores the data in memory structure in memtable(RAM) when the initial write request is generated from the Client. Concurrently the writes are written on Commitlog(Disk) as well which are permanent even if the light goes off for the node.
- The data from the memtable(RAM) is flushed to the SSTables(Disk) and the partition index is also created that points to the location of data in the disk. The flushing of data from memtable(RAM) to SSTables(Disk) is done using the configurable threshold or when the commit log threshold commitlog_total_space_in_mb is exceeded.
- The Data is written on the SSTables tables which are immutable which means when the memtable is flushed the data is not overwritten in SSTables despite a new file being created. The partitions are stored on multiple SSTables so that they can be easily searched.
The following is the flow of Cassandra's write operation.
Cassandra Structure For Each SSTable
Cassandra creates the following structure from each of the SSTable. Let's understand all of the components.
1. Data (Data.db)
Cassandra stores the data in the data.db file of SSTable.
2. Primary Index (Index.db)
This structure is used to store the index of the row key that points to the data which are stored in the data file.
3. Bloom filter (Filter.db)
It is a memory stored structure that is used to check the data is present in the memtable before going to the SSTables.
4. Compression Information (CompressionInfo.db)
This file is used to store the detail of uncompressed data length, chunk offsets, and other important details concerning compression.
5. Statistics (Statistics.db)
This file is used to store the Statistical metadata information of the data stored in the SSTable.
6. SSTable Index Summary (SUMMARY.db)
It is used to store the SSTable partition Index Summary and some portions in the memory.