1. What is Apache Cassandra?
Apache Cassandra is a widely used No SQL database solution that was developed on Facebook and uses by many organizations. Cassandra Masterclass hybrid architecture provides high availability, Linear scalability, and the fault-tolerance feature due to which it can be deployed on the commodity hardware and cloud system making it the best platform for the mission-critical application data. Apache Cassandra is capable of serving both as a real-time datastore for online transaction applications and reads intensive databases for reporting business applications. Its peer-to-peer architecture provides high availability even a region is down which makes it the best choice.
2. Why use Apache Cassandra?
The following are some of the important reasons to use Apache Cassandra.
- Apache Cassandra can scale from Gigabyte to Petabyte.
- Apache Cassandra can achieve linear performance by adding nodes in the cluster.
- The replication and the data distribution take place easily.
- Cassandra can be easily deployed on commodity hardware and the cloud system.
- In Cassandra architecture, there is no separate caching layer involved because its peer-to-peer architecture removes the need for caching layer.
- Cassandra provides the flexible schema structure for structure, semistructured, and unstructured data.
- Cassandra compresses the data by using Google's Snappy data compression algorithm.
3. What are the Disadvantages of Apache Cassandra?
The following are the some of the Disadvantages of Apache Cassandra?
- Cassandra does not support the ACID properties.
- Cassandra does not offer the subquery support or the join support.
- Due to the high number of requests and data handling, the transaction gets slow and latency issues start coming.
- The data modeling of Apache Cassandra is attached to the queries and not the structure hence data is get stored multiple times.
4. Explain the different types of database elements of Apache Cassandra?
The following are the different types of database elements in Apache Cassandra.
- Cassandra Clusters: It is the containers where keyspaces are stored.
- Cassandra Keyspaces: Keyspaces are placeholders to store objects such as a table, indexes, etc.
- Cassandra Column Family: The Cassandra Column Family is a similar set of rows that has the same structure.
- Cassandra Tables: Tables are used to store the actual data.
5. What are the major differences between MongoDB and Cassandra?
The following are some of the major differences between Cassandra and MongoDB.
| Cassandra | MongoDB |
|---|---|
| Apache Cassandra was developed by Apache Software Foundation and the initial version was released in July 2008. | MongoDB was developed by MongoDB Inc and the initial version was released in Feb 2009. |
| Cassandra supports the JSON data format only. | MongoDB supports the JSON and BSON data formats. |
| Cassandra is developed in Java. | MongoDB is developed in a combination of languages which are C++, Javascript, Python. |
| Cassandra supports the Selectable Replication Factor for replication. | MongoDB supports the Master and Slave replication method. |
| Cassandra does not support the ACID transaction. | MongoDB provides support for multilevel ACID transactions. |
| The read operation in Cassandra is much better compared with MongoDB. | Read operation in MongoDB is low compared with Cassandra. |
| Cassandra supports the use of the secondary index. | MongoDB does support the secondary index. |
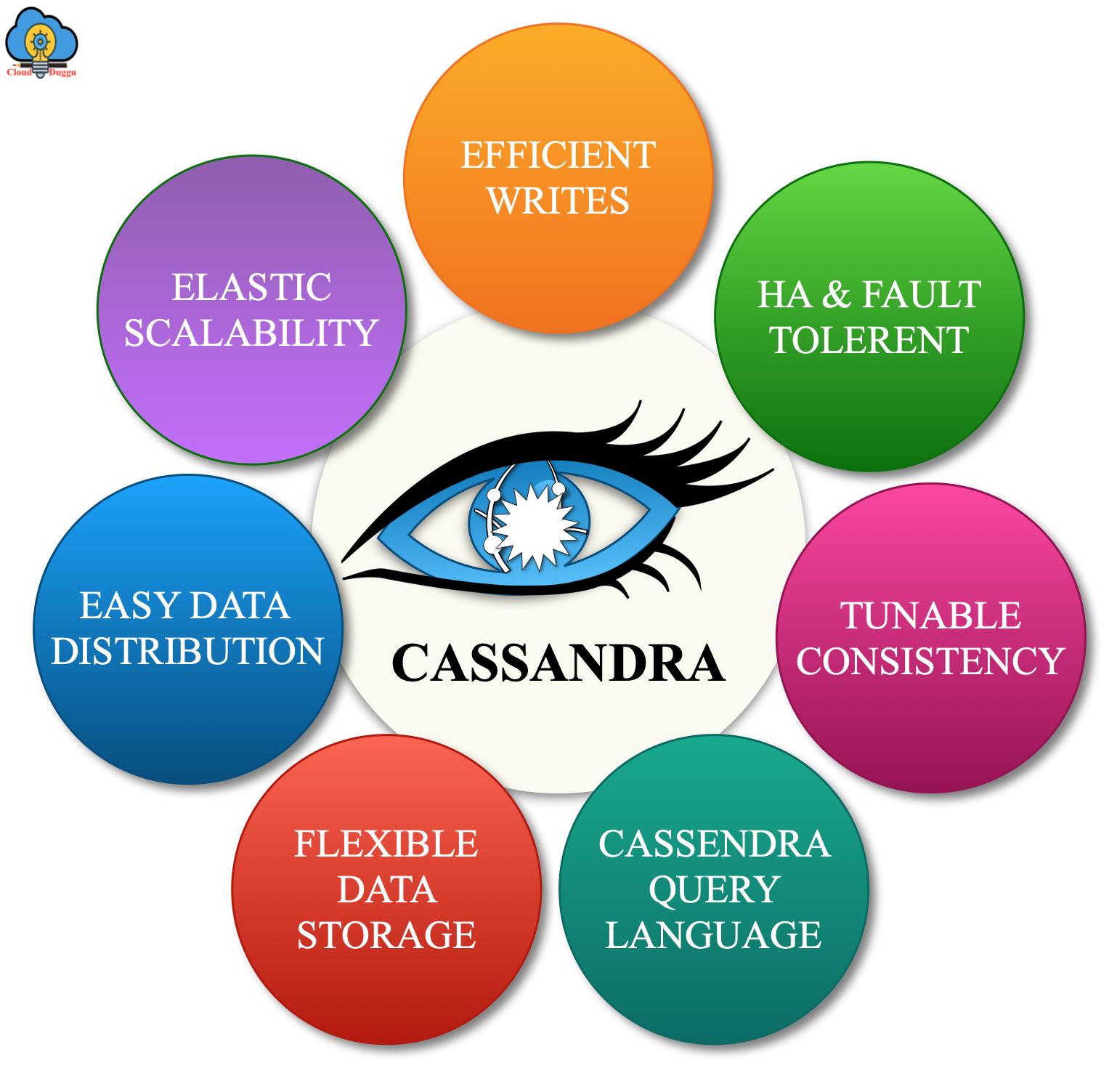
6. What are some of the important features of Apache Cassandra?
The following figure shows some of the important features of Apache Cassandra.
7. What is CQLSH in Apache Cassandra?
Apache Cassandra cqlsh stands for Cassandra Query Language. It is the command-line interface tool that is used to interact with Cassandra to define the schema, insert data and execute the query? CQLSH comes with the Cassandra package and is present in the bin/ directory.
8. What is the important component of Apache Cassandra's architecture?
The following is the list of the important component of Apache Cassandra's architecture?
- Cluster
- Data cluster
- Node
- Commit log
- Meme-table
- SSTable
- Bloom filter
9. Does Apache Cassandra support the acid transactions?
Apache Cassandra does not support the RDBMS ACID transactions. Just like RDBMS, Cassandra does not support the joins or foreign keys and hence can't guarantee consistency in the sense of ACID(Atomicity, Atomicity, Isolation, Durability).
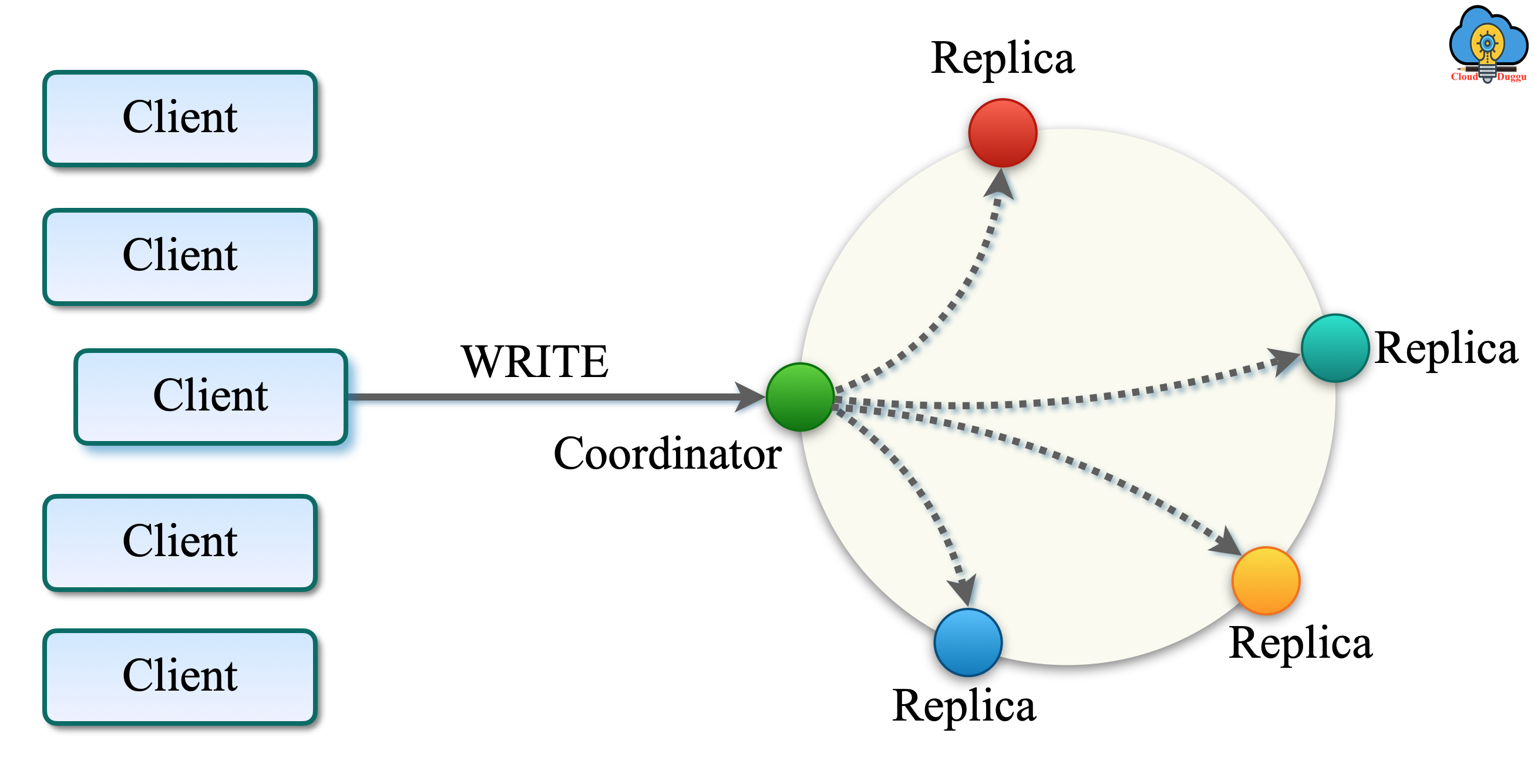
10. What is the replication factor in Cassandra?
To ensure reliability and fault tolerance, Apache Cassandra stores the data on multiple nodes so in case of failure the data can be accessed from any node. The number of total replicas is considered as the Cassandra Replication factor. If the replication is defined as 1 that means there is one copy of data, if the replication factor is defined as 2 then there are two copies of data. Cassandra follows two replication strategies named SimpleStrategy and NetworkTopologyStrategy.
In the following figure, we can see the data is copied two times which are indicated as the (2 red and 2 blue).
11. What is the Node in Cassandra?
The node is the basic unit to store the data in the Apache Cassandra architecture. It is part of the Cassandra cluster and one of the key components.
12. Explain the primary key in Cassandra and their types?
The Cassandra Primary Key is used to uniquely identify a row. Compared to RDBMS primary key, the Cassandra primary key is used to determine the data locality. When a row is inserted the hashing function is applied to the partition key and the output decides which node will hold the data.
There are three types of Primary Keys in Apache Cassandra.
13. What is the difference between Single Primary Key, Compound Primary Key, and the Composite Partitioning Key in Cassandra?
The Single Primary Key has one column defined as the primary key and acts as the partition key as well and the data is distributed based on that column over nodes. In the Compound Primary Key, the data is partitioned based on the partitioning key and then clustering will take place which sorts the data on partitions. When the data is sorted in the partition then the row fetching becomes very efficient. The Composite Partitioning Key creates multiple partitions for the data. It is basically used when high data is present on one cluster.
14. What is the work of the coordinator node in Apache Cassandra?
The Coordinator node in Apache Cassandra is used to handle the request coming from the client and decide which node in the ring should get the request. It is responsible for handling the complete request coming from the client and sending the result to the client.
15. What is SSTable in Apache Cassandra?
The Cassandra SSTable stands for Sorted Strings Table is the file used to hold the data persistently and efficiently. It is the place where data is stored permanently in the Cassandra database. If there is an update on data then a new SSTable file is created. SSTable uses the Log-Structured Merge (LSM) structure to store the data. This structure is basically used for write-intensive and fast-growing large data sets.
16. What is a NoSQL database?
NoSQL stands for Not only SQL are the databases that provide the way to store data other than the traditional relational databases management tables. The NoSQL database is schema-less and provides easy distribution and replication of data over a cluster of nodes. The NoSQL database is capable of handling structured, semistructured, and unstructured data.
The following are some of the important features of NoSQL databases.
- NoSQL databases are schema-free databases.
- The data is replicated over multiple nodes easily.
- The majority of the NoSQL databases are open source.
- NoSQL database provides distributed support.
- NoSQL database can scale horizontally.
- NoSQL databases can store and process a huge amount of data.
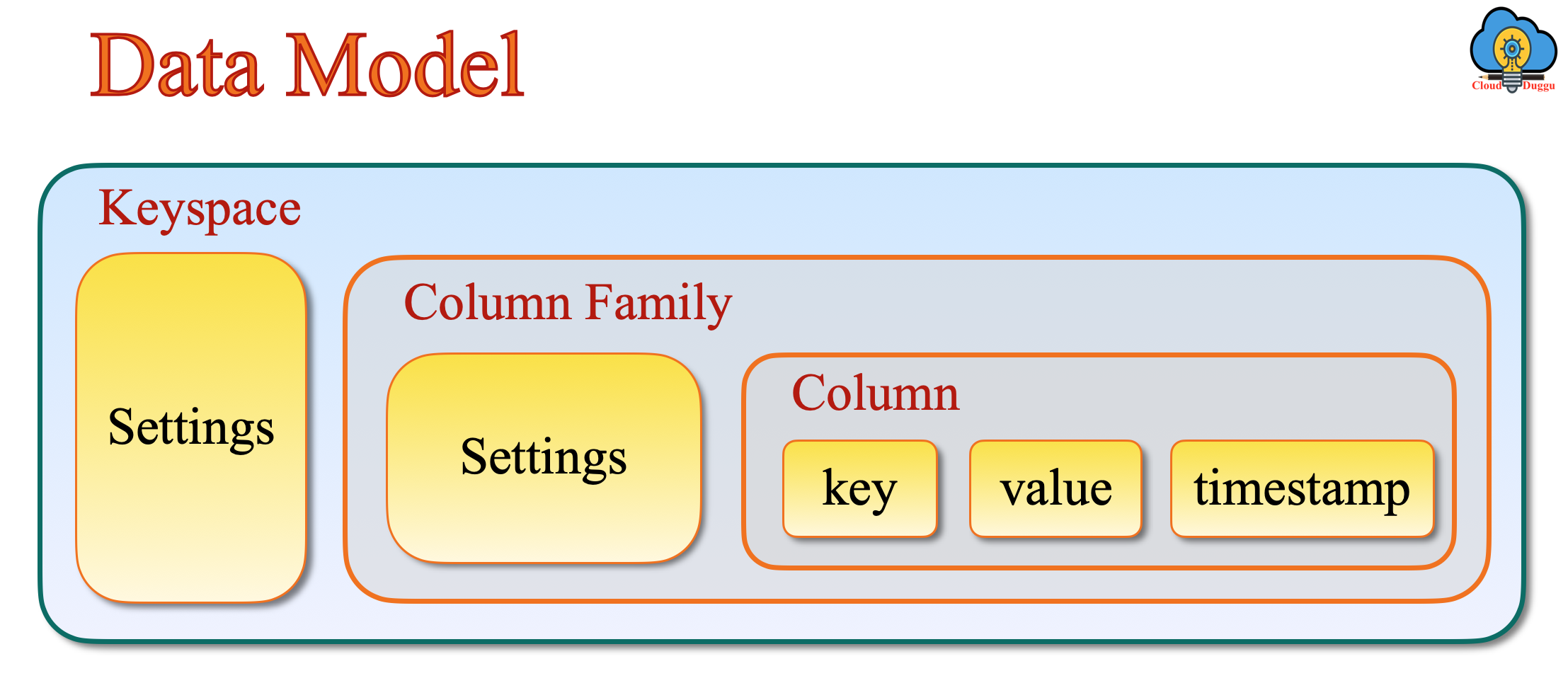
17. Explain the data model of Apache Cassandra?
The Major component of the Apache Cassandra Data model is as below.
Cluster
The Cassandra Cluster is the combination of individual nodes which are connected in the ring format and operate together. Each node in the cluster contains the replica and in case of failure, the replica carries a charge. Cassandra handles the ring cluster architecture and assigns them the task.
Keyspace
The Cassandra Keyspace is similar to the databases in the RDBMS system. It is the outermost layer in the Cassandra architecture and stores the objects.
Column Family
Cassandra Column Family is the collection of sorted rows which are used to store related data.
Column
Cassandra Column is the basic data structure used to store various data such as key, value, timestamp, big integer, text, Boolean, double, float, and so on.
The following figure represents the high-level overview of Apache Cassandra.
18. Explain Nodetool Utility.
Cassandra Nodetool utility is the command-line interface to work on the administration and monitoring of the Cassandra cluster. It helps to narrow down the problem of the cluster such as node down and give a piece of insight information. There are many commands supported by the Nodetool which can be viewed by using nodetool help command.
19. What is the Logging in Cassandra?
The Logging in Cassandra provides information about the work that is happening on the database. The logs are written on the system.log, debug.log, and gc.log. These log files store the system-related general details, the debugging details, and the Java garbage collection logs. The logging can be configured manually or through code to get more information.
20. What are the different logging levels in Apache Cassandra?
The following are the different levels of loggings in Apache Cassandra.
- ALL In this logging level, all levels of information are captured.
- TRACE In this logging level, the tracking-related information is logged.
- DEBUG This level logged the information that is required for debugging.
- INFO The basic information is logged in this logging level.
- WARN In this logging, the warning-related information is logged.
- ERROR The error-related information is logged at this level.
- OFF This option is used to turn off the logging level.
21. What is the major difference between SSTable and memtable in Cassandra?
The memtable is the memory structure that temporarily holds data during the write operation, but it can't store it permanently. SSTable is the physical structure in which data is permanently stored. The data stored in SSTable can't be changed rather for any data change operation a new SSTable file is created.
22. Explain the difference between the Truncate and Drop commands in Cassandra CQLSH?
The major difference between the CQLSH Truncate and Drop commands is that Drop Table is used to drop a table from the keyspace and the Truncate Table is used to delete the rows from the table, except the table structure.
23. What is the commit log in Apache Cassandra?
Cassandra Commit log is used to log any data that is written to Cassandra before applying on the memtable. Commit log provides a crash recovery mechanism in Cassandra. In case of any unexpected shutdown, the commit log is checked and changes are applied in the memtable.
24. What are the different ports used in Apache Cassandra?
Apache Cassandra uses port 7000 to make cluster communication. It uses port 9161 for the clients and port 8080 for the JMX communication. The configuration of these ports is defined in bin/cassandra.in.sh file and it can be editable.
25. What is the command to start the Cassandra cqlsh?
We can use the following command to start Cassandra cqlsh.
cloudduggu@ubuntu:~$ cd apache-cassandra-4.0.1cloudduggu@ubuntu:~/apache-cassandra-4.0.1$ cd bin
cloudduggu@ubuntu:~/apache-cassandra-4.0.1/bin$ ./cassandra
cloudduggu@ubuntu:~/apache-cassandra-4.0.1/bin$ ./cqlsh
26. In write operation where does Cassandra write data?
Cassandra writes the data in the following three components.
- Commitlog write
- Memtable write
- SStable write
27. What is gossip in Cassandra?
Cassandra gossip is the communication protocol that is used by nodes to check the state of other nodes in the cluster? The gossip runs every 3 seconds and checks the status of at least 3 nodes. The gossip carries a version with it so once it communicates with other nodes the old message is overwritten with the most recent message of the node.
28. What is Bloom Filters in Cassandra?
Bloom Filters is the data structure that is used to check the SSTable data file for the requested data in the read operation. It provides the two possible states in Cassandra, the first one is data is present in the given SSTable file, or the second one is data is not present in the SSTable file. Bloom Filters does not guarantee that the data is present in the SSTable file but the probability can be increased by assigning more space to the Bloom Filters.
29. When to use Apache Cassandra?
We can use Apache Cassandra in the following use cases?
- Sensor data
- Messaging systems
- Ecommerce websites
- Entertainment websites
- Fraud detection for banks
- E-commerce and inventory management
30. When we should not use Apache Cassandra?
We should not use Apache Cassandra in the following use cases.
- ACID transaction
- To Achieve Strong consistency
- Heavy updates and deletes operations
- Heavy read operation