What is Apache Cassandra?
Apache Cassandra is a Distributed, High Performance, Scalable, Fault-Tolerant, and NoSQL Database solution system developed by Apache Software Foundation to handle a high volume of data without compromising on the performance. Apache Cassandra is used by more than 1000 organizations across the globe for high availability and best performance. Apache Cassandra provides Linear scalability for on-prem or the cloud system to support mission-critical applications. Cassandra can be used to store the data from online transactional applications as well as it can be used for reading only operations for business intelligence applications.
The following figure represents the quick overview of What is Cassandra?
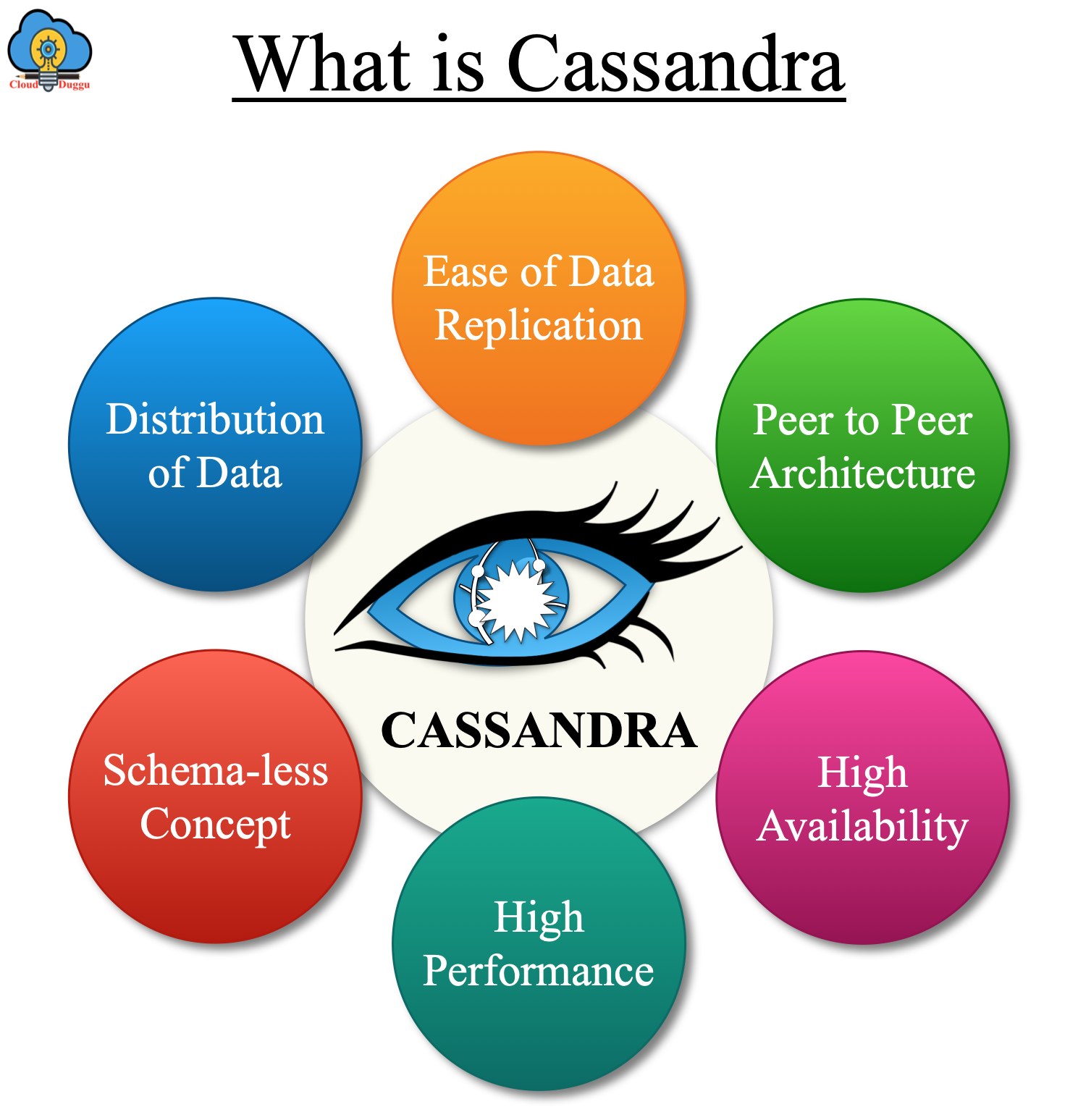
Why Apache Cassandra?
The following are some of the important facts to use Apache Cassandra.
- Cassandra can scale from Gigabytes to Petabytes based on the requirement.
- By adding nodes Cassandra provides the Linear Performance.
- There is no such failure at any point.
- The data distribution and replication take place easily.
- Cassandra is flexible on Cloud as well as On-Premise systems.
- Cassandra does not require a separate layer of cashing.
- Cassandra supports the Writes and reads the level of tunable level consistency in which write operation never fails and all replicated blocks are readable.
- Cassandra can be easily deployed on commodity hardware, there is no such special level of Hardware is required.
- Cassandra offers the capability to compress the data at the Table level by using Google's snappy data compression algorism.
- Cassandra uses the CQL(Cassandra Query language) which is similar to SQL.
Features of Cassandra
Let us see the Characteristic of Cassandra in the following section.
1. Hybrid Solution
The Architecture of Cassandra is a master class that provides high throughput and a low level of latency due to that it provides the best class performance on Public Cloud, Private Cloud, or the On-Premises.
2. Fault-Tolerant
The Fault-Tolerant feature of Cassandra provides the high availability of data with less latency in case of Disk Drive failure. Also, the replacement of failed Disk Drives requires no downtime that provides peace of mind to the end-users.
3. High Reliable and Stable
The Reliability and the Stability test of Cassandra have been done over 1000 nodes and different types of measurement have been done in terms of, Load testing, real-world use cases, faulty injection, and so on.
4. Distributed
The Architecture of Cassandra has been developed in such a way that there is no concept of a Master node. Based on the user request, every node is capable of processing and serving the data. The data is distributed over the cluster of nodes and each node has been assigned the same set of responsibilities due to that there is no point of failure.
5. Scalable
Cassandra is designed in such as way that if we are scaling the architecture by adding a node in the Cluster that case the read and write operation will scale linearly without any service interruptions or any outage for applications.
6. Security and Observability
Cassandra logs all the DML, DDL, and DCL commands activity into the audit logs so that they can be tracked in case of any security issues. Logging these activities in Cassandra's audit logs does not put more load on the system performance and the system performs well.
7. Query language
The CQL(Cassandra Query Language) is used to access the Cassandra database and perform the operation such create table insert data, creating keyspace, dropping keyspace, and so on. The CQL is similar to the SQL query language.
8. MapReduce language
Cassandra can be easily integrated with Hadoop and provide support with MapReduce. Along with Hadoop, it also supports the Apache Ping, Apache Hive, and so on.
9. Peer to Peer Architecture
Cassandra works on the Peer to Peer architecture in which there is no centralized node and each node will work as a client and server. Cassandra does not have a Master-Slave architecture.
10. Cloud Availability
Cassandra can be easy installation on the Cloud infrastructure.
History of Cassandra
Apache Cassandra was developed by Avinash Lakshman and Prashant Malik on Facebook to boost Facebook index searching. In July 2008, Facebook release Cassandra as an open-source on Google code. In March 2009, Cassandra become the Apache Incubator project and become the top-level project on February 17, 2010.
The following figure represents the History of Apache Cassandra.
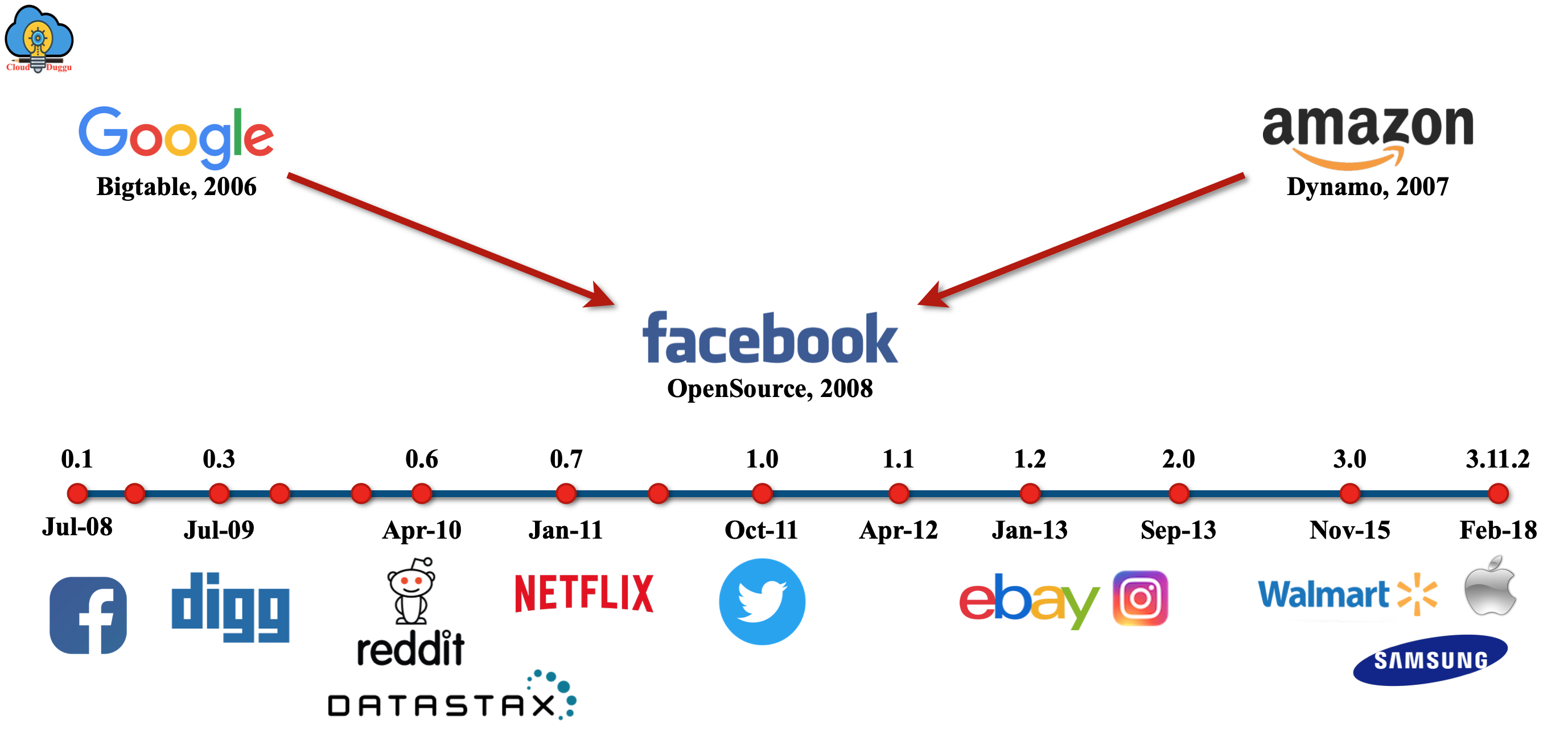
Apache Cassandra Releases
The following table shows the year-by-year releases of Apache Cassandra.
| Sr. No. | Cassandra Version | Release Date |
|---|---|---|
| 1 | 0.6 | 12 April 2010 |
| 2 | 0.7 | 08 January 2011 |
| 3 | 0.8 | 02 June 2011 |
| 4 | 1 | 17 October 2011 |
| 5 | 1.1 | 23 April 2012 |
| 6 | 1.2 | 02 January 2013 |
| 7 | 2 | 01 September 2013 |
| 8 | 2.1 | 10 September 2014 |
| 9 | 2.2 | 20 July 2015 |
| 10 | 3 | 11 November 2015 |
| 11 | 3.11 | 23 June 2017 |
| 12 | 3.11.2 | 19 February 2018 |
Cassandra Advantages
The following is the list of Cassandra's Advantages.
- Cassandra provides a flexible schema in which a new column can be added while accessing the existing data.
- Cassandra supports high availability and scalability without a single failure.
- The throughput of reading and writing operations is very high.
- Cassandra supports the searching through a secondary index and uses the SQL-like language called CQL(Cassandra Query Language).
- The implementation of the NoSql column family can be done in Cassandra.
- Cassandra supports the tunable consistency in which a client can specify the consistency level. If there is a higher consistency level specified then multiple replicates are written before the write operation is complete.
Cassandra Disadvantages
The following is the list of Cassandra's Disadvantages.
- Cassandra does not support the ACID(Atomicity, Consistency, Isolation, and Durability) properties.
- Cassandra is optimized and provides a high throughput on write operation. If the use case is for a heavily read operation then Cassandra will not be suitable.
- The complete transaction management for the tables is not supported in Cassandra.
- The support of joins can be an issue and create an overload condition for Cassandra.
- The data is distributed across all nodes and hence if there is a failure then it spread across all nodes.
- Cassandra is based on JVM and hence it requires lots of effort to tune the garbage collection for reading and write operations.
Cassandra vs Hadoop-HDFS vs MongoDB
The following table shows the difference between Cassandra, Hadoop-HDFS, and MongoDB on different parameters.
| Mapping Parameters | Cassandra | Hadoop/HDFS | MongoDB |
|---|---|---|---|
| Primary use cases | Cassandra stores data that come in Petabytes for analytics engines. | Hadoop-HDFS is used to store structured, unstructured, and semistructured data to perform big data analytics. | MongoDB is based on a Flexible JSON format used for fast development. |
| Development Model | It is maintained by the Apache Foundation. | It is maintained by the Apache Foundation | AGPL open source does the MongoDB restricted development. |
| Reliability | Cassandra has a Masterless architecture that is extremely reliable and flexible, It requires no failover and supports bi-directional multi-datacenter support. | Hadoop has a master-slave and very high available architecture in which failures are handled automatically. | MongoDB has multiple replicas architecture which provides high availability and automated failover. |
| Read/write latency | On average it takes 5-15 milliseconds to perform a standard operation which will be consistent if the datasets are growing. | Hadoop is developed to perform the Batch operation. | MongoDB performance is similar for a standard operation, but the complexity in the query creates an unevenness. |
| Scalability | There is no practical limit for Cassandra and it can scale up to multi Petabytes. | Hadoop also has no practical limit and can scale up to multi Petabytes. | MongoDB can scale up to TB and beyond that, it requires sharding that is very difficult to manage on large scale. |
| Query Language | Cassandra uses the CQL(Cassandra Query Language) that is similar to SQL. | Hadoop uses the Map-Reduce programming model to operate. | MongoDB uses JSON and API-based queries. |
| Data Model | Cassandra's data model has a structure table that can store multi-value fields. | Hadoop has a schema-less data model. | MongoDB has a Schema-less JSON data model. |
Top Industries are Using Apache Cassandra
The following is the chart of industries that are using the Apache Cassandra. The Computer Software that contributes 34% and the Information Technology and Services that contributes 14% are the highest one.
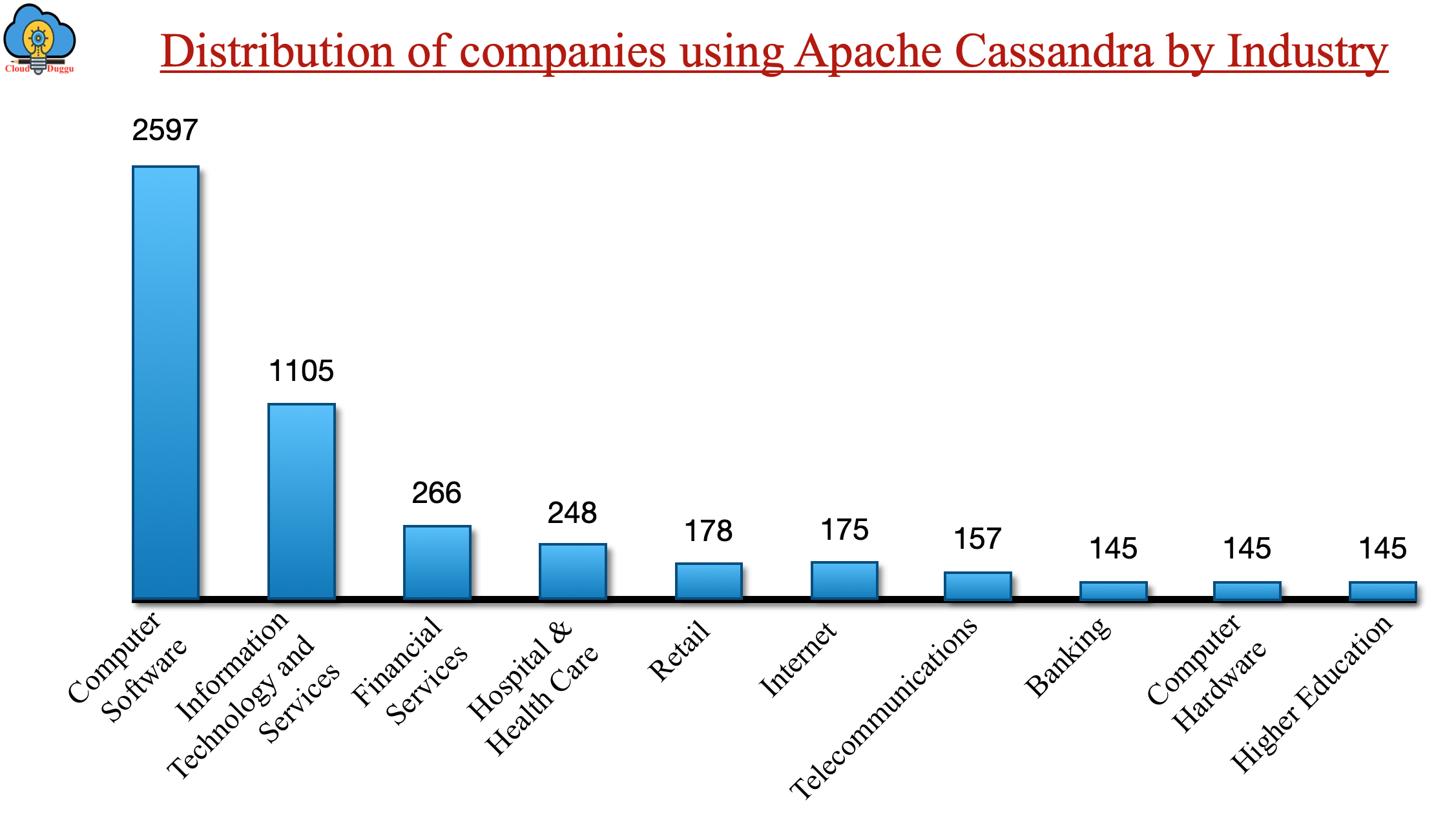
The following figure represents the list of companies and organizations that are using Cassandra in their Production system.
