In Cassandra, we can create an Index using the Cassandra Create Index Command. In case the data is already present in the column then during the execution of the query the indexing of data is done. For the new data, the indexing automatically takes place when the data is inserted in the index column. Cassandra Index is used to improve the performance during query processing and searching of the data.
The following are some of the conditions where we should not use the Cassandra Index.
- We should not create an index for the high cardinality columns of huge volumes which is fetching a small number of results.
- The index should not be created for those columns which are getting updated or deleted frequently.
- We should avoid creating an index on the columns which are accessing the large cluster because the response will be required from all clusters which will make the query slow, and the query response will get even slow down when more clusters will be added. It can be avoided by narrowing the search.
Create Index
To create a Cassandra index we will use the Create Index command. The syntax of creating an index is mentioned below.
Syntax:
CREATE INDEX IF NOT EXISTS indexnameON keyspacename.tablename ( KEYS ( column_name ) );
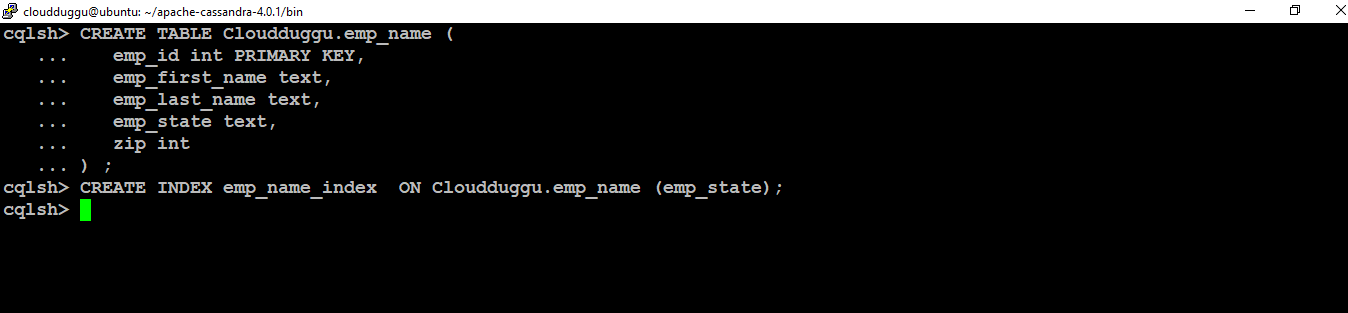
Let's take an example to create a table name emp_name in the Cloudduggu keyspace and post that we will create the index named emp_name_index on the table as mentioned below.
Command:
cqlsh> CREATE TABLE cloudduggu.emp_name (emp_id INT PRIMARY KEY,
emp_first_name TEXT,
emp_last_name TEXT,
emp_state TEXT,
zip INT
);
cqlsh> CREATE INDEX emp_name_index ON cloudduggu.emp_name (emp_state);
Output:
Drop Index
To drop an Index in Cassandra, we can use the Drop Index Cassandra Command. In the following section, we will drop the index named emp_name_index which was created in the Create index section.
Syntax:
DROP INDEX IF EXISTS keyspace.indexname;Command:
cqlsh> DROP INDEX IF EXISTS cloudduggu.emp_name_index;Output:
