Apache Cassandra is the NoSQL, distributed, and highly scalable database solution developed to handle mission-critical data without any single failure. The journey of Cassandra was started from Facebook where it adopted the Distributed feature from Amazon Dynamo DB and the Data Model and Storage solution from Google Big Table.
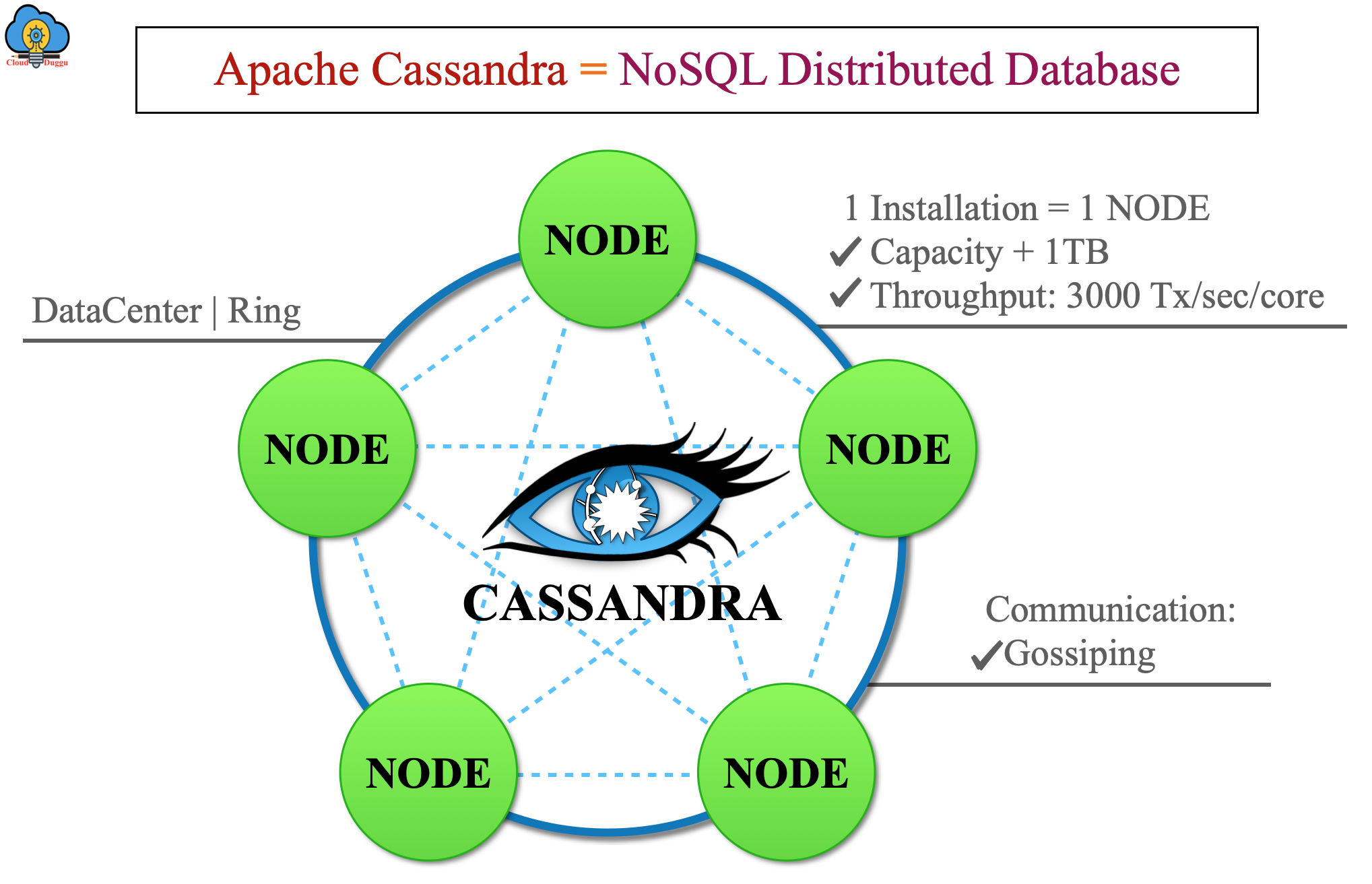
Apache Cassandra has the Peer to Peer cluster architecture in which there is no concept of Master and Slaves. It is very easy to set up and maintain. Cassandra's architecture looks like a ring in which nodes are logically distributed and communicate with each other using the gossip protocol to exchange the node status. The Data is spread across the nodes using hash values of the keys. Each node of the Cassandra cluster stores the written operation logs in the Commit Log to maintain the data durability. Post that the data is written to the in-memory structure of each node called memtable. So when the memtable is full, the data is written to the SSTables data file. The write operation in Cassandra is automatic and it's replicated and partitioned across the cluster. To ensure consistency of data across all nodes, Cassandra uses the repair mechanisms which are Hinted Handoff, Read Repair, Anti-Entropy Repair.
The following figure represents the Architecture of Cassandra in which the Gossip Protocol is used to make the communication between nodes of Cluster.
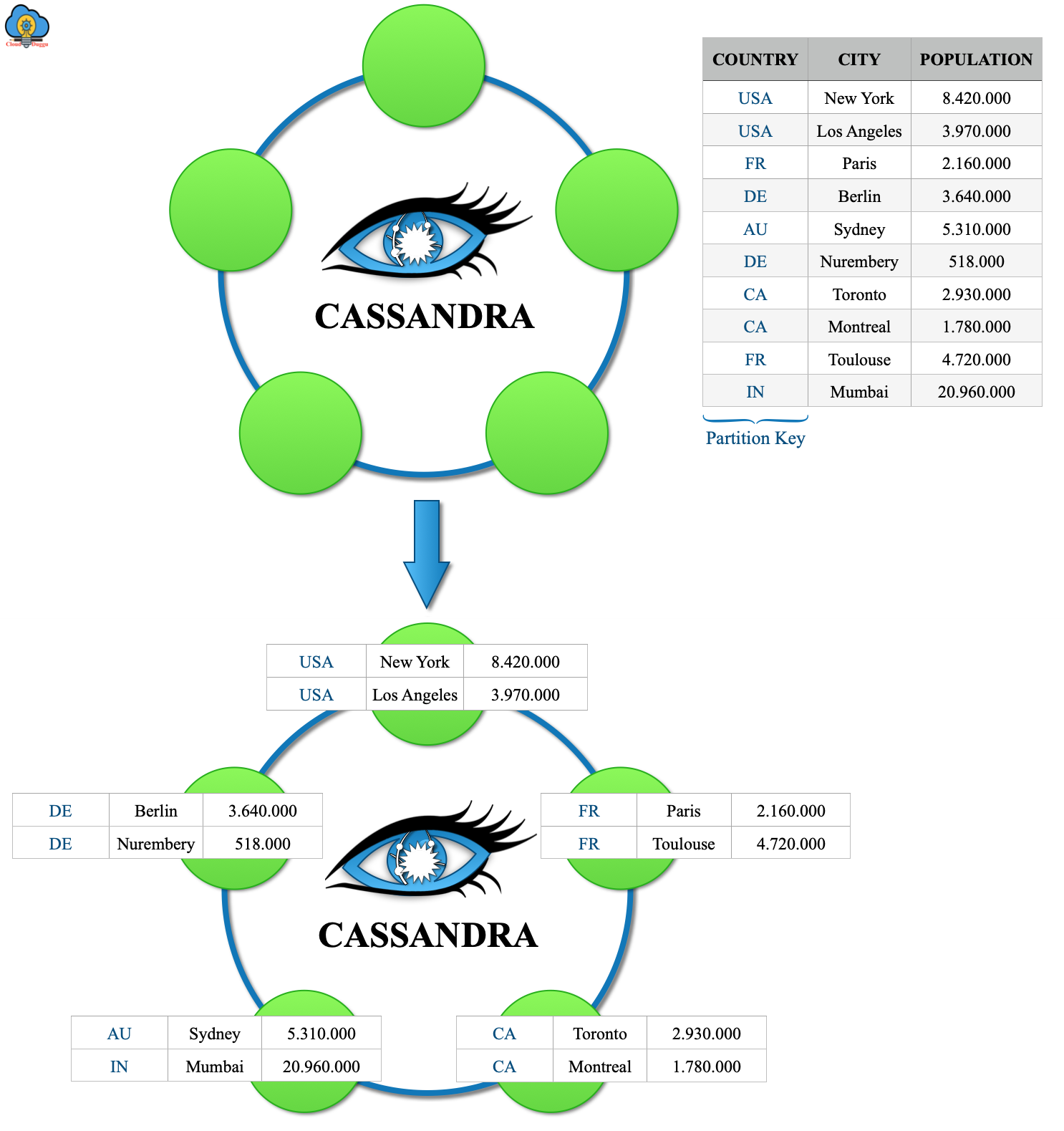
The following figure represents the Ring Type Architecture of Cassandra. The smallest logical unit of this Architecture is a node. Each row in Cassandra has a partition key. After applying the hashing on the partition key the unique token is generated for each row. Now each node has a range of tokens assigned so similar token rows are stored on the same node as mentioned below figure.
Key Components of Cassandra Architecture
Now let us see the key components of Cassandra Architecture in the following section.
1. Node
In the Cassandra Architecture, the Node represents the basic architecture of a cluster and is used to store the user's data and its location. In Cassandra Cluster, there could be many Nodes and altogether provides the Distributed feature of Cassandra. The nodes use the gossip protocol to communicate with each other and provide the same data. The Logical structure of multiple nodes is called a Cassandra Ring or the Cluster.
2. Data Center
The Cassandra Data Center is the collection of related nodes which are configured in the Cluster to perform the replication. The Data Centers can be Physical data centers or Logical data Center and depending upon the workload a separate Data Center can be used.
3. Cluster
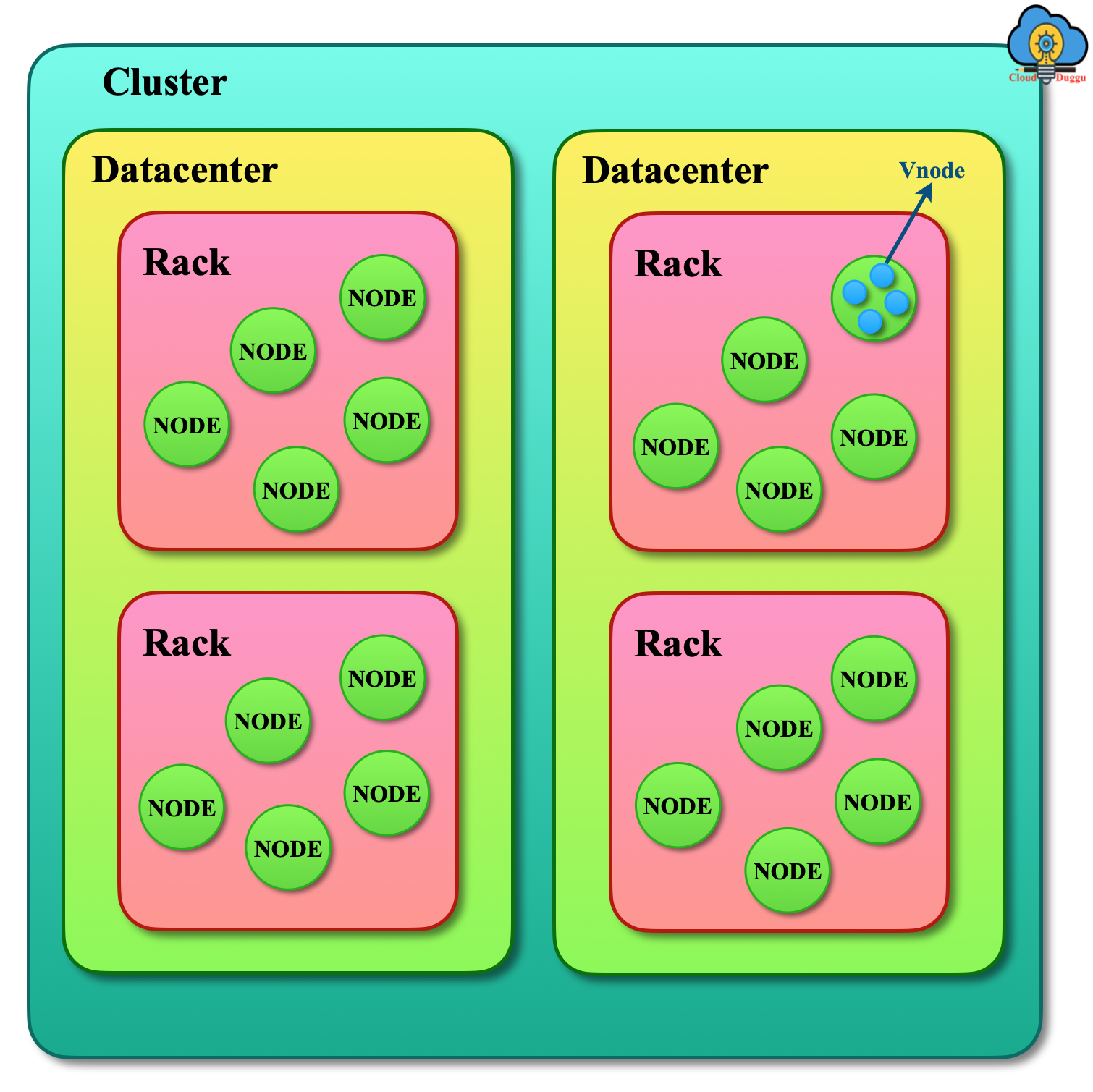
The Cassandra Cluster can contain one or more Data Centers and in the Data Centers, there could be nodes that contain default 256 Virtual nodes. The following figure represents the hierarchy of Cassandra Cluster.
4. Commit log
The Commit Log is used to store the write operation performed in the Cassandra Node. Any write operation is written in the Commit log first before it moves to the memtable. Commit Log is a mechanism to provide durability in case there is a shutdown. Upon system startup, all the logs are applied in the memtable. The Commit Log is archived, deleted, or recycled once the data is flushed to the SSTables.
5. Memtable(RAM)
Once the write operations are written to Commitlog post that data is written to the Memtable. The Cassandra Memtable is a memory resident structure that is used to store the written data in the sorted format unless some defined threshold limit exceeds. In certain cases, there could be multiple Memtable for the single-column family.
6. SSTable(DISK)
SSTable stands for Sorted Strings Table which is a file format used by Cassandra to store the statics and the data from the memtables. The Cassandra SSTables are immutable hence any update on the table creates a new SSTables file. The data structure format used by SSTables is Log-Structured Merge which is qualified for writing intense heavy data sets compared to the traditional B tree structure.
7. Bloom Filters
Bloom Filters are used to check the requested data is present in the memtable(RAM) before checking the SSTables(DISK). During the Read operation, Cassandra merges the data from SSTable and Memtable. This is required to avoid reading every SSTable file for a user request data and to do so Cassandra employs Bloom Filters data structure. Bloom Filters data structures are used to provide the data state "whether the requested data is present in SSTable file or the requested data is not present in SSTable file".
8. Cassandra Query Language
Cassandra CQL stands for Cassandra Query Language which is a query language to access the Cassandra. It is similar to SQL(Structured Query Language) that offers to perform the DML/DDL operations on the dataset. Once the client makes a connection with any of the Cassandra nodes then that node becomes the coordinator and acts as a proxy between the client and the node that is holding the data.