Apache Kafka Streams WordCountDemo Program
Apache Kafka Streams is termed as a client library that is used to create real-time and mission-critical applications. In Kafka Stream operation the input and output data is stored in Kafka cluster.
In this section, we will see a “wordcount” program using Kafka Stream, which will take “text” as input from the command line and process it, after processing it will produce an output of word count.
Let us see the step-by-step implementation of the “wordcount” program using Kafka Streams.
Step 1. Start Kafka and Zookeeper Server
Please start zookeeper and Kafka servers.
Command For Zookeeper:
cloudduggu@ubuntu:~/kafka$ ./bin/zookeeper-server-start.sh config/zookeeper.properties
Command For Kafka:
cloudduggu@ubuntu:~/kafka$ ./bin/kafka-server-start.sh config/server.properties


Step 2. Create Input and Output Topic
Step 2. Create Input and Output Topic
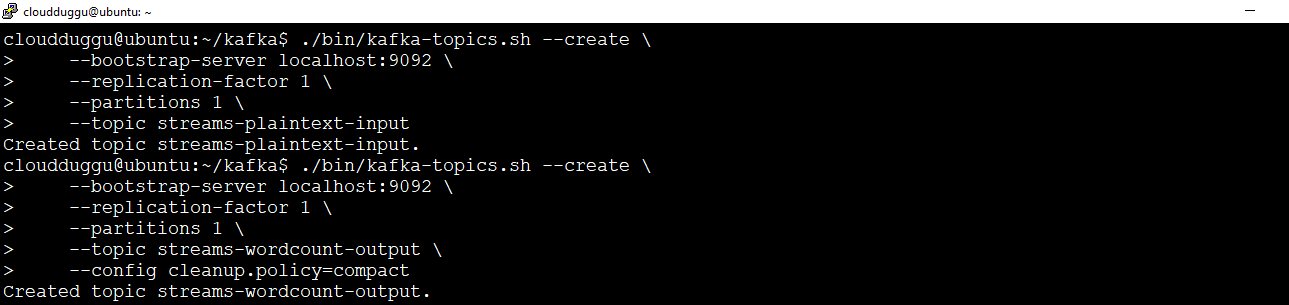
Now we will create an input topic named streams-plaintext-input and the output topic named streams-wordcount-output.
Command For Input Topic:
cloudduggu@ubuntu:~/kafka$./bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Command For Output Topic:
cloudduggu@ubuntu:~/kafka$./bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Step 3. Start the Wordcount Application
cloudduggu@ubuntu:~/kafka$./bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
cloudduggu@ubuntu:~/kafka$./bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
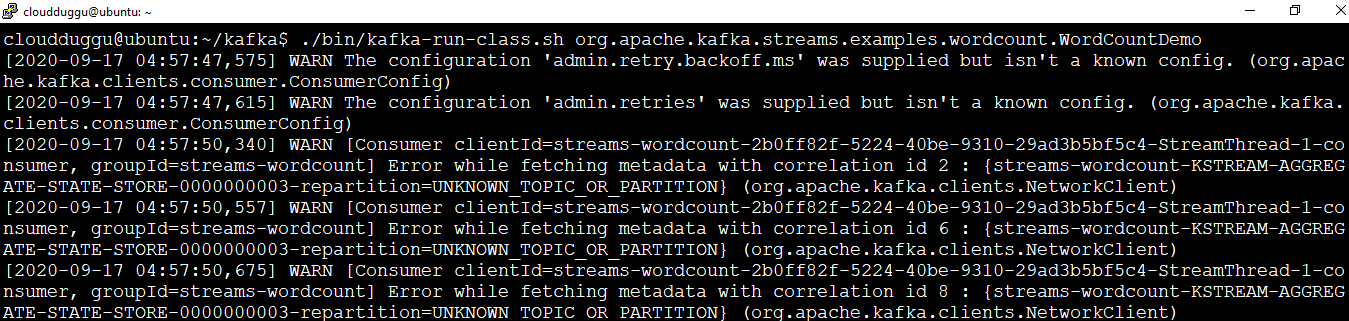
Step 3. Start the Wordcount Application
Now start the wordcount application using the below command in a separate terminal.
The WordCount application program will read data from the input topic streams-plaintext-input and perform the computations of the WordCount algorithm on each of the read messages, and continuously write its current results to the output topic streams-wordcount-output.
Command:
cloudduggu@ubuntu:~/kafka$./bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
Step 4. Start Producer
Open a new terminal and start Kafka producer using tool “kafka-console-producer.sh” and write some input.
Command:
cloudduggu@ubuntu:~/kafka$ ./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input

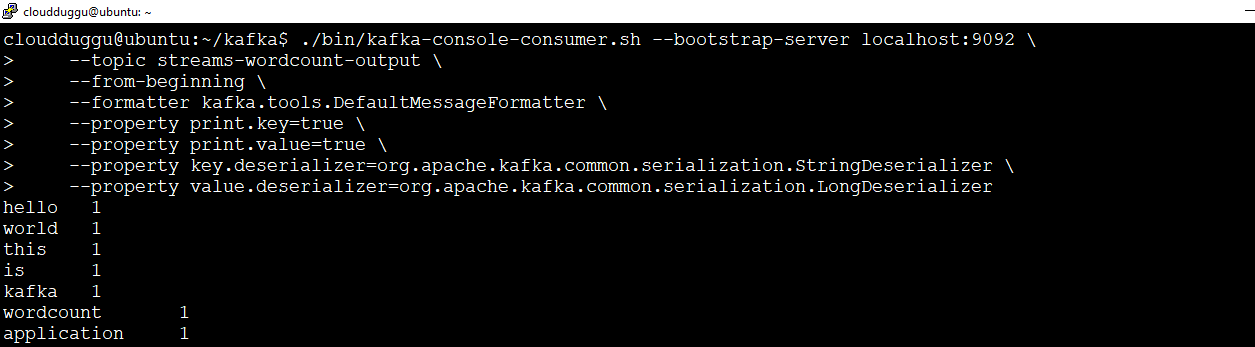
Step 5. Start Producer
Open another terminal and run the consumer tool to read the input, process it, and print word count output.
Command:
cloudduggu@ubuntu:~/kafka$./bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
cloudduggu@ubuntu:~/kafka$./bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
We can see the output of the Wordcount application, which is actually a continuous stream of updates in which each output record is an updated count of a single word.