What is Apache Kafka Architecture?
Apache Kafka is an open-source event streaming platform that is designed to provide the basic mechanisms necessary for managing streaming data, Storage (Kafka core), integration (Kafka Connect), and processing (Kafka Streams). Apache Kafka is a proven technology that is deployed on many production environments to boost some of the world’s largest stream processing systems.
Apache Kafka stores key-value messages which come from randomly many producers after which data is partitioned into different "partitions" within different "topics". In each partition, messages are ordered by their offsets (the position of a message within a partition) and indexed and stored together with a timestamp. There are other processes called “consumers" which are used to read messages from partitions.
Apache Kafka uses Streams API for stream processing, which is used to write Java applications that consume data from Kafka and write results back to Kafka. Kafka also can be used with external stream processing systems such as Apache Apex, Apache Flink, Apache Spark, and Apache Storm.
The following figure shows the architecture of Apache Kafka and its important components.
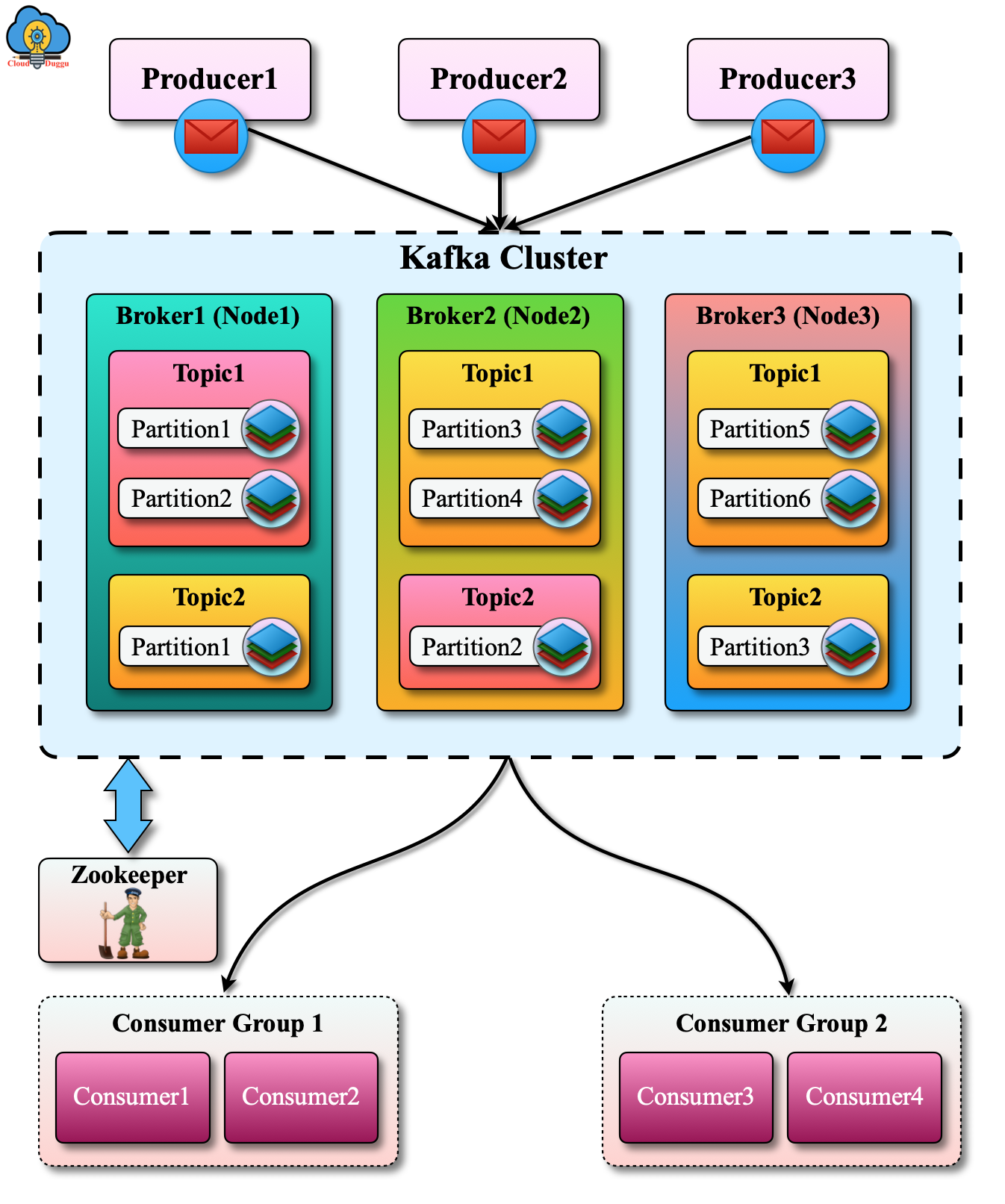
Let us see each component of Apache Kafka in detail.
1. Message
Messages flow from producer to consumer through topics existing in a broker.
2. Producer
The producer is used to produces these stream messages and push them into the topic.
3. Topic
Topic defines the category in which the producer pumps the messages and depending upon the type of messages there is a new topic created.
4. Broker
Apache Kafka cluster has multiple nodes and each node represents a Kafka broker that contains multiple partitions that holds multiple topics.
5. Partition
A partition contains ordered messages from the producer. Writing on each partition is a sequential process that increases Kafka's performance. When writing onto the topic partition, each message is assigned a sequence number which is referred to as offset and this uniquely identifies a message in a partition. Kafka is distributed in nature and hence it distributes these topic partitions across multiple brokers for fault tolerance and durability of messages.
6. Consumer
The consumer is used to subscribe to a particular message category (a topic) and ingests messages in that topic. This consumer reads messages from the topic and is commended with maintaining the audit of which message has been read and actioned. Kafka does not remove these messages nor take an audit of messages read by various consumers connecting to the topic and reading messages.
7. Consumer Group
In Kafka, a logical grouping of consumers is known as consumer groups.
8. Zookeeper
Zookeeper stores the Metadata information in which Kafka store the detail of consumer and cluster configuration.
Apache Kafka in Nutshell
Apache Kafka is a distributed processing system. It consists of Servers and Clients who communicate and process on a high-performing TCP network protocol. Kafka can be deployed on bare-metal hardware, virtual machines, and containers in on-premise as well as cloud environments.
Let us see the action performed by Servers and Clients in Apache Kafka.
Servers
Kafka runs on a cluster of nodes that are deployed in multiple data centers or cloud regions. Kafka can scale its architecture depending upon the requirement and provides a fault-tolerant feature. In case of a node failure, the other nodes of the cluster will take the work of failed node and provide a continous operation.
Clients
The client can create applications and microservices that will on Kafka cluster and perform a read, write stream processing in parallel. Kafka provides the stream library for Java, Python, C, C++, and so on.