Apache HBase data model is distributed, multidimensional, persistent, and a sorted amp that is index by the column key, row key, and timestamp and that is the reason Apache HBase is also called a key-value storage system.
The following are the Data model terminology used in Apache HBase.
1. Table
Apache HBase organizes data into tables which are composed of character and easy to use with the file system.
2. Row
Apache HBase stores its data based on rows and each row has its unique row key. The row key is represented as a byte array.
3. Column Family
The column families are used to store the rows and it also provides the structure to store data in Apache HBase. It is composed of characters and strings and can be used with a file system path. Each row in the table will have the same columns family but a row doesn't need to be stored in all of its column family.
4. Column Qualifier
A column qualifier is used to point to the data that is stored in a column family. It is always represented as a byte.
5. Cell
The cell is the combination of the column family, row key, column qualifier, and generally, it is called a cell's value.
6. Timestamp
The value which is stored in the cell are versioned and each version is identified by a version number that is assigned during creation time. In case if we don't mention timestamp while writing data then the current time is considered.
A sample table in Apache HBase should look like below.
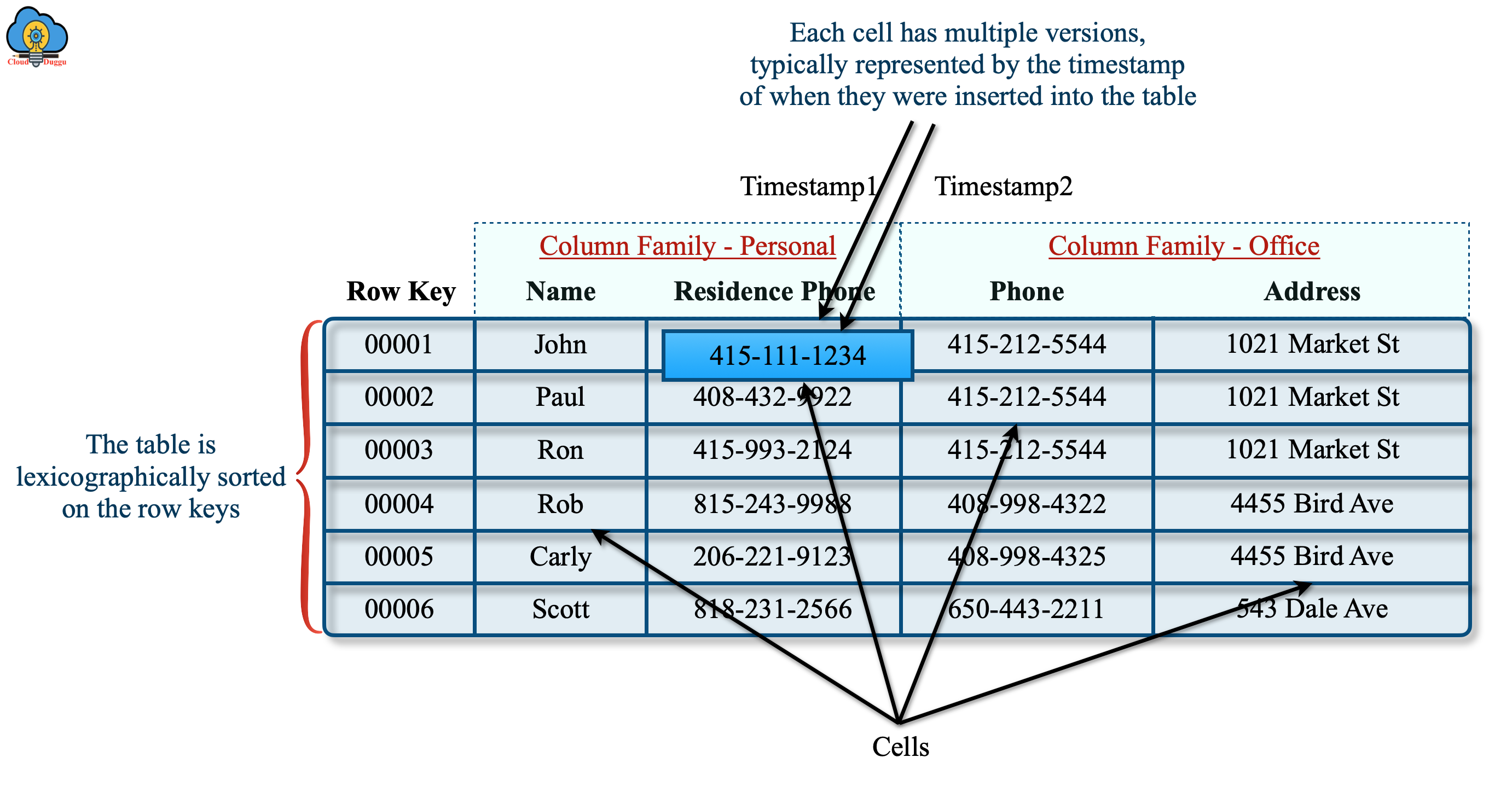
The above table has two column families which are named Personal and Office. Both column families are having two columns. The data is stored in a cell and rows are sorted by row keys.
HBase Data Types
In Apache HBase, there is no such concept of data types. It’s all byte array. It's a kind of byte-in and byte-out database, in which, when a value is inserted, it is converted into a byte array using the Put and Result interfaces. Apache HBase uses the serialization framework to converts user data into byte arrays.
We can store the value up to 10 to 15 MB in the Apache HBase cell. In case the value is higher then we can store it in Hadoop HDFS and store the file path metadata information in Apache HBase.
HBase Data Store
The following is the Conceptual and Physical view of Apache HBase.
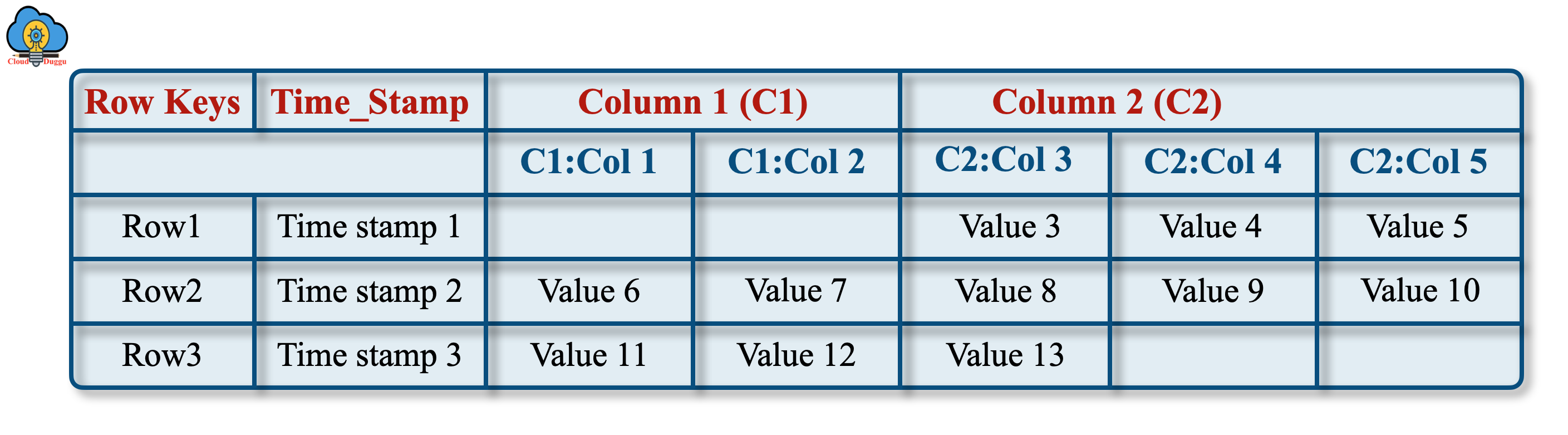
1. Conceptual View
We can see that a table is viewed as a set of rows at the conceptual level.
The following is the conceptual view of how data is stored in HBase
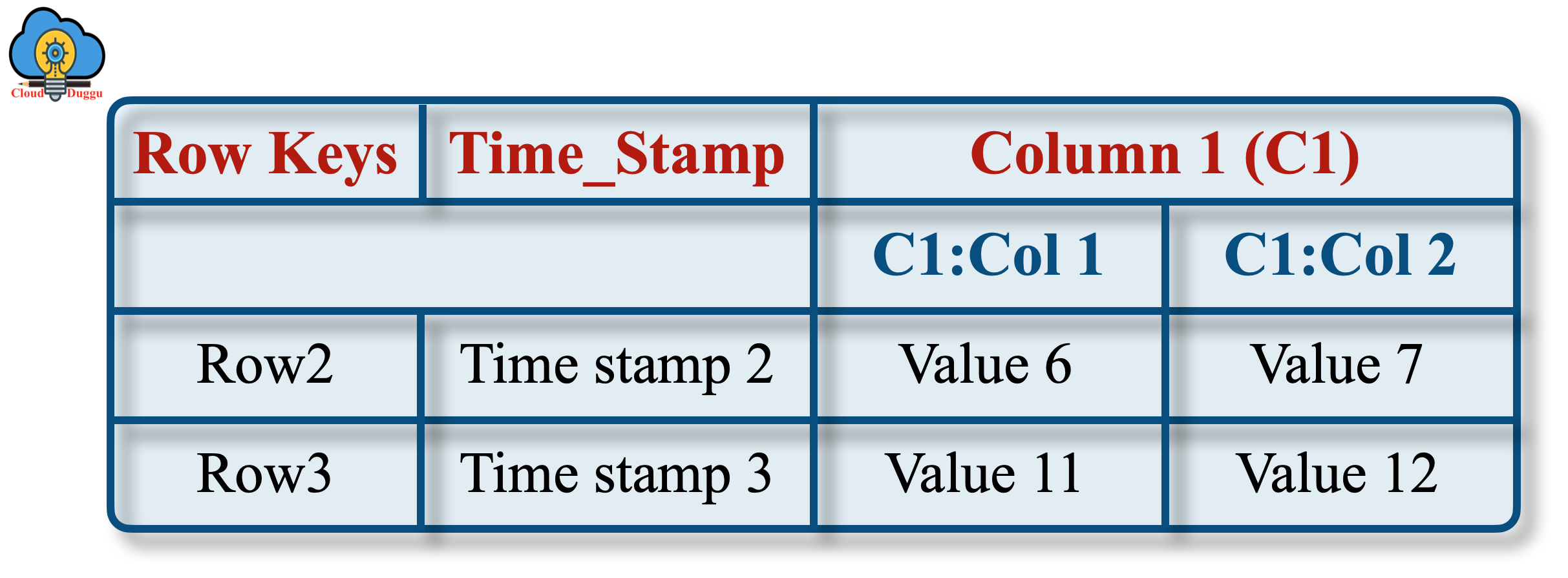
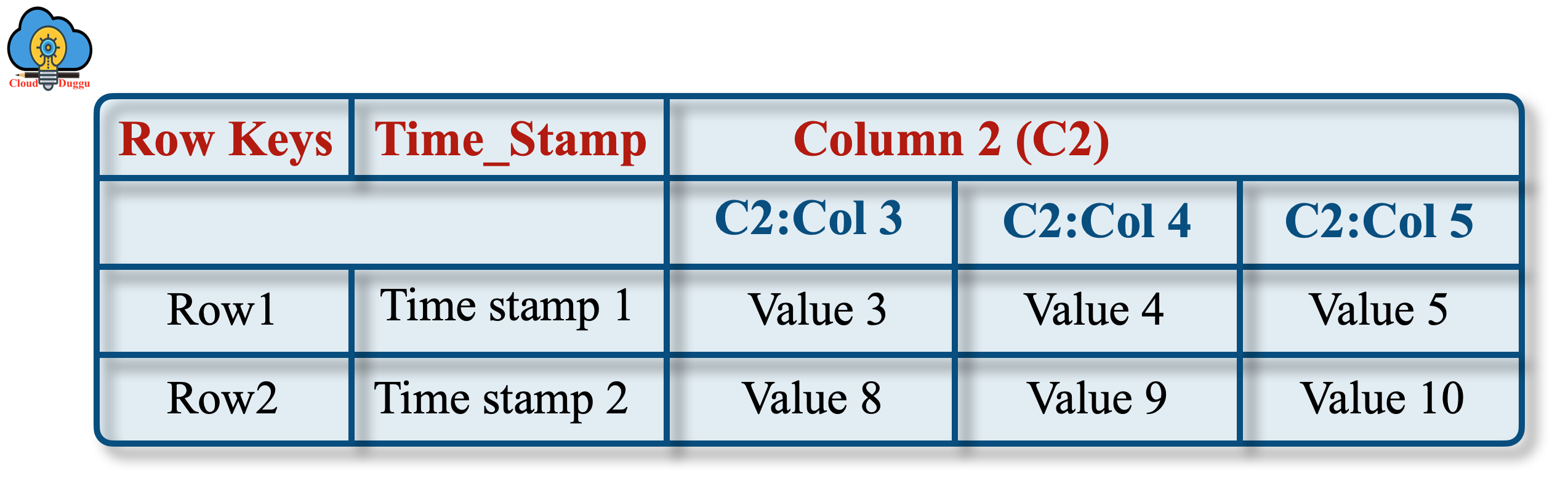
2. Physical View
The Physical view table is physically stored by the column family.
The following example represents the tables that will be stored as column-family-based tables.
Namespace
A namespace is a logical grouping of tables. It is similar to relational databases in group related tables.
Let us see the representation of namespace.
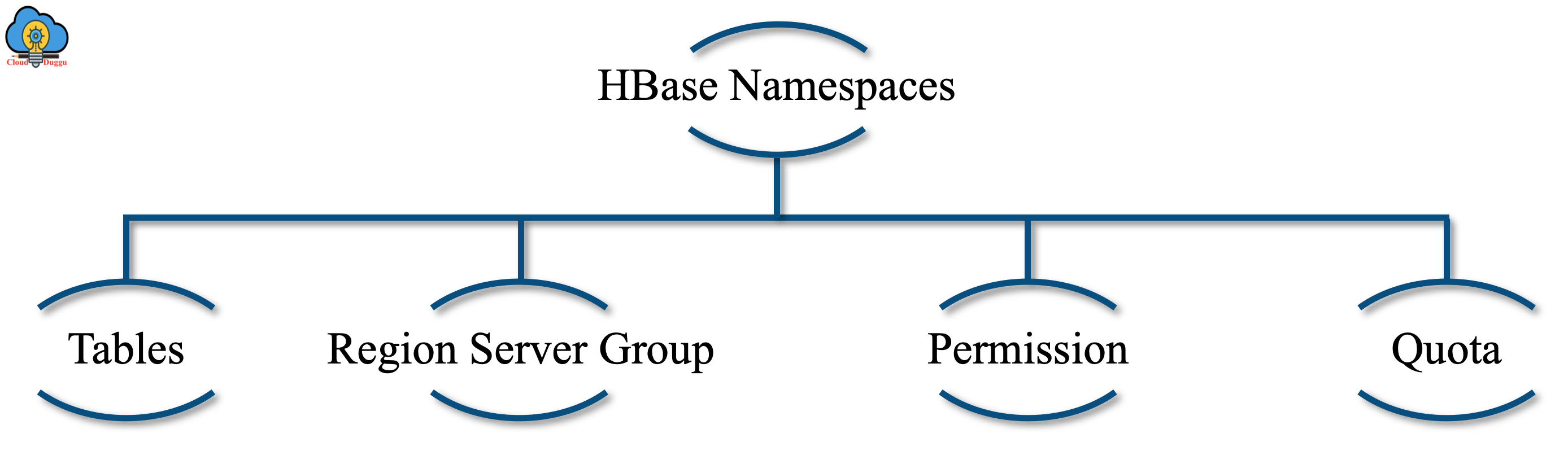
Now let us see each component of the namespace.
1. Table
All tables are part of the namespace. If there is no namespace defined then the table will be assigned to the default namespace.
2. RegionServer group
It is possible to have a default RegionServer group for a namespace. In that case, a table created will be a member of RegionServer.
3. Permission
Using namespace a user can define Access Control Lists such as a read, delete, and update permission, and by using write permission a user can create a table.
4. Quota
This component is used to define a quota that the namespace can contain for tables and regions.
5. Predefined namespaces
There are two predefined special namespaces.
- hbase: This is a system namespace that is used to contain HBase internal tables.
- default: This namespace is for all the tables for which a namespace is not defined.
Data Model Operations
The major operation data models are Get, Put, Scan, and Delete. Using these operations we can read, write and delete records from a table.
Let us see each operation in detail.
1. Get
Get operation is similar to the Select statement of the relational database. It is used to fetch the content of an HBase table.
We can execute the Get command on the HBase shell as below.
hbase(main) :001:0> get 'table name', 'row key' <filters>2. Put
Put operation is used to read multiple rows of a table. It is different from getting in which we need to specify a set of rows to read. Using Scan we can iterate through a range of rows or all the rows in a table.
3. Scan
Scan operation is used to read multiple rows of a table. It is different from Get in which we need to specify a set of rows to read. Using Scan we can iterate through a range of rows or all the rows in a table.
4. Delete
Delete operation is used to delete a row or a set of rows from an HBase table. It can be executed through HTable.delete().
Once the Delete command is executed, it is marked as a tombstone and when compaction takes place, the row is finally deleted from the table.
The various types of internal delete markers as below.
- Delete It is used for a specific version of a column.
- Delete column Can be used for all column version.
- Delete family It is used for all columns of a particular ColumnFamily.