Apache Drill supports and accesses the Plain Text Files and the structure file types such as text files, flat files. In this tutorial, we will create the following file types and will access their data in drill also based on those files we will create the table in Drill.
The Drill-supported text file format is as mentioned below.
- CSV(comma-separated values) file format
- TSV(tab-separated values) file format
- PSV(pipe-separated values) file format
Let us see each File format in detail in the below section.
1. CSV Files Format
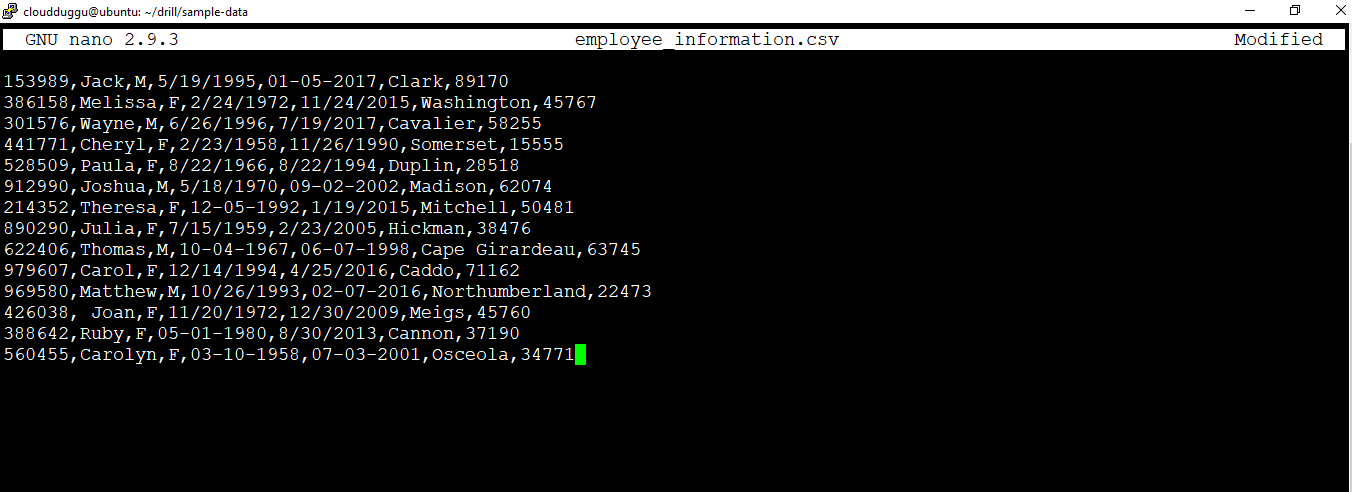
We will create a CSV file with the name "employee_information.csv" under "/home/cloudduggu/drill/sample-data" directory and put the below content in that.
153989,Jack,M,5/19/1995,01-05-2017,Clark,89170
386158,Melissa,F,2/24/1972,11/24/2015,Washington,45767
301576,Wayne,M,6/26/1996,7/19/2017,Cavalier,58255
441771,Cheryl,F,2/23/1958,11/26/1990,Somerset,15555
528509,Paula,F,8/22/1966,8/22/1994,Duplin,28518
912990,Joshua,M,5/18/1970,09-02-2002,Madison,62074
214352,Theresa,F,12-05-1992,1/19/2015,Mitchell,50481
890290,Julia,F,7/15/1959,2/23/2005,Hickman,38476
622406,Thomas,M,10-04-1967,06-07-1998,Cape Girardeau,63745
979607,Carol,F,12/14/1994,4/25/2016,Caddo,71162
969580,Matthew,M,10/26/1993,02-07-2016,Northumberland,22473
426038, Joan,F,11/20/1972,12/30/2009,Meigs,45760
388642,Ruby,F,05-01-1980,8/30/2013,Cannon,37190
560455,Carolyn,F,03-10-1958,07-03-2001,Osceola,34771
Command:
We have used a nano editor to create the "employee_information.csv" file and put the above records. To save the file press CTRL+O and to exit from the file press CTRL+x.
Output:

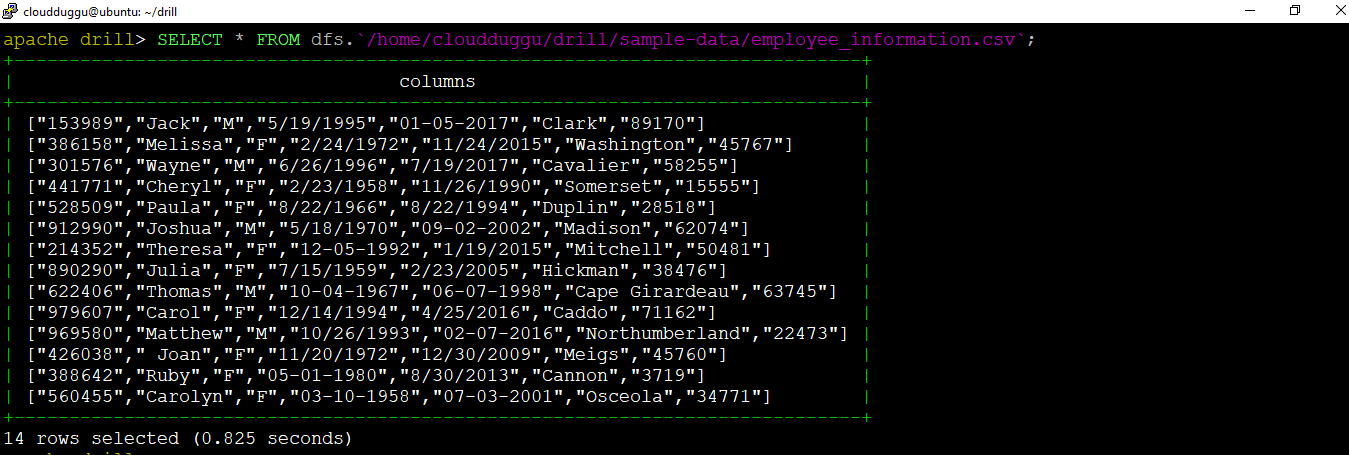
1.1 Query CSV Files Format
Now let's see the records of "employee_information.csv" by querying them from Drill command-line interface.
Command:
Output:
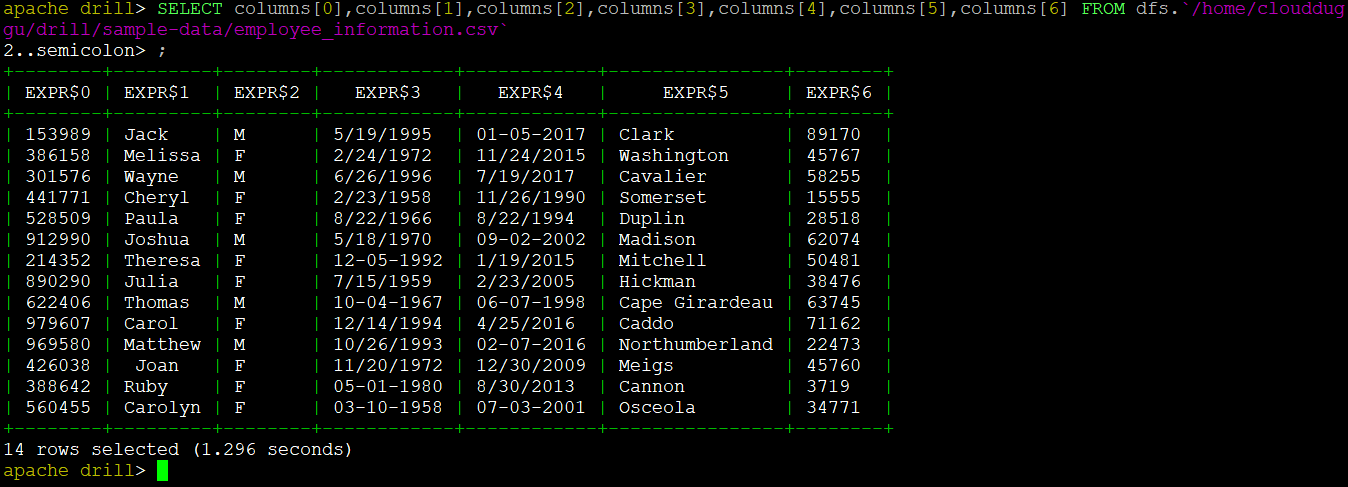
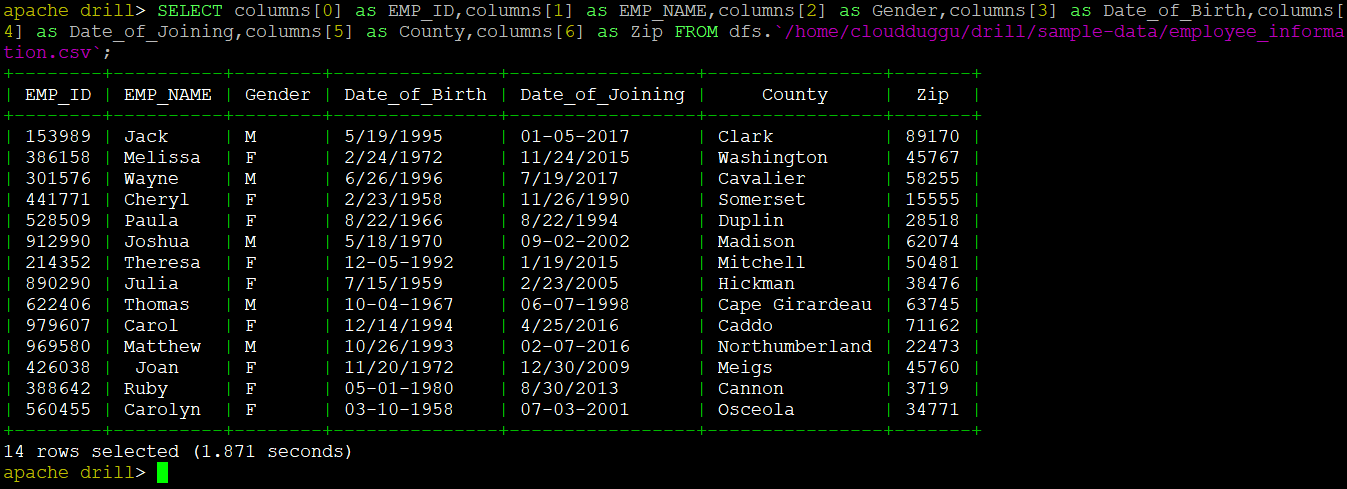
1.2 Query CSV Files with Column[n] Syntax
We can query the CSV file in Drill using the Column[n] Syntax in which the value starts from 0 and goes till n-1. 0 represents the first column. For example, we are fetching all column values of the "employee_information.csv" file and the query would be as below.
Command:
Output:
1.3 Query CSV Files with Column Name
We can convert Column[n] into a meaningful name also called alias as well using the "AS" clause.
Command:
Output:
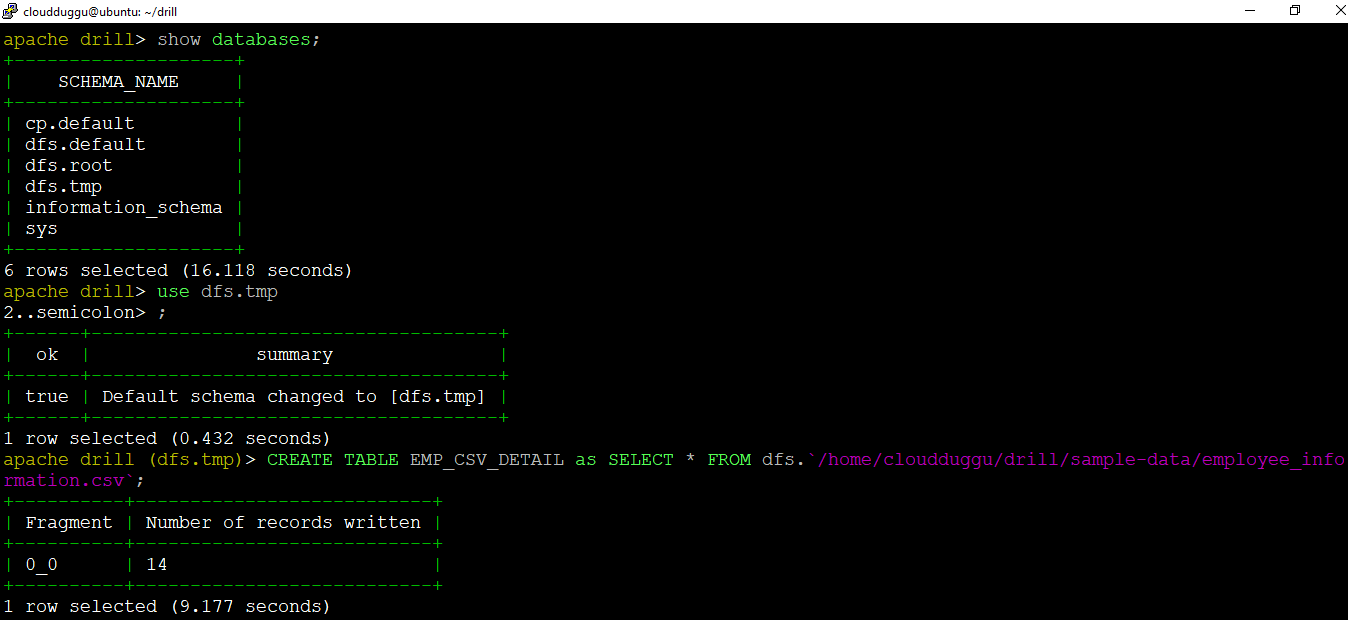
1.4 Create table using CSV Data file
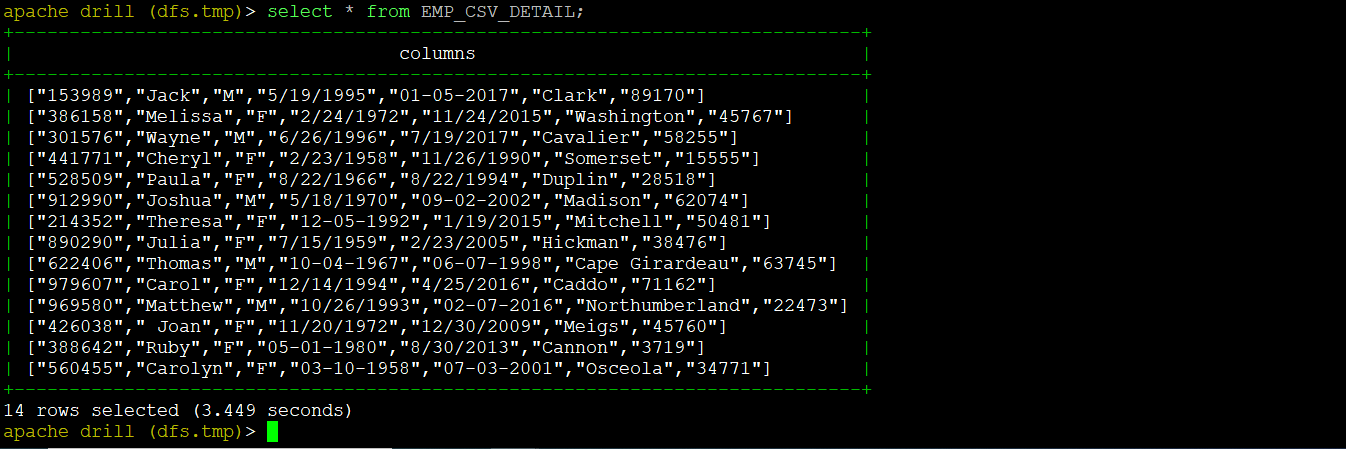
We can create a table name "EMP_CSV_DETAIL" using the CSV data file "employee_information.csv". The below command will be used to create the table. Before creating a table we will use the "dfs.tmp" schema as mentioned below.
Command:
Output:
2. TSV Files Format
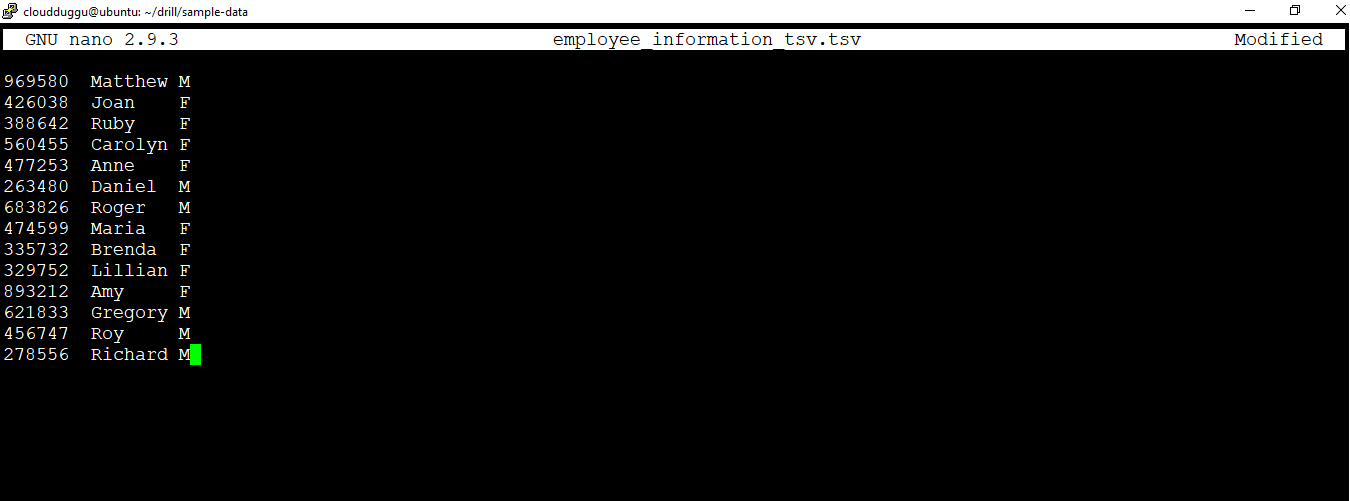
We will create a TSV file with the name "employee_information_tsv.tsv" under "/home/cloudduggu/drill/sample-data" directory and fetch the records using Drill query.
The content of the TSV file is as mentioned below.
969580 Matthew M
426038 Joan F
388642 Ruby F
560455 Carolyn F
477253 Anne F
263480 Daniel M
683826 Roger M
474599 Maria F
335732 Brenda F
329752 Lillian F
893212 Amy F
621833 Gregory M
456747 Roy M
278556 Richard M
Command:
We have used a nano editor to create the "employee_information_tsv.tsv" file and put the above records. To save the file press CTRL+O and to exit from the file press CTRL+x.
Output:

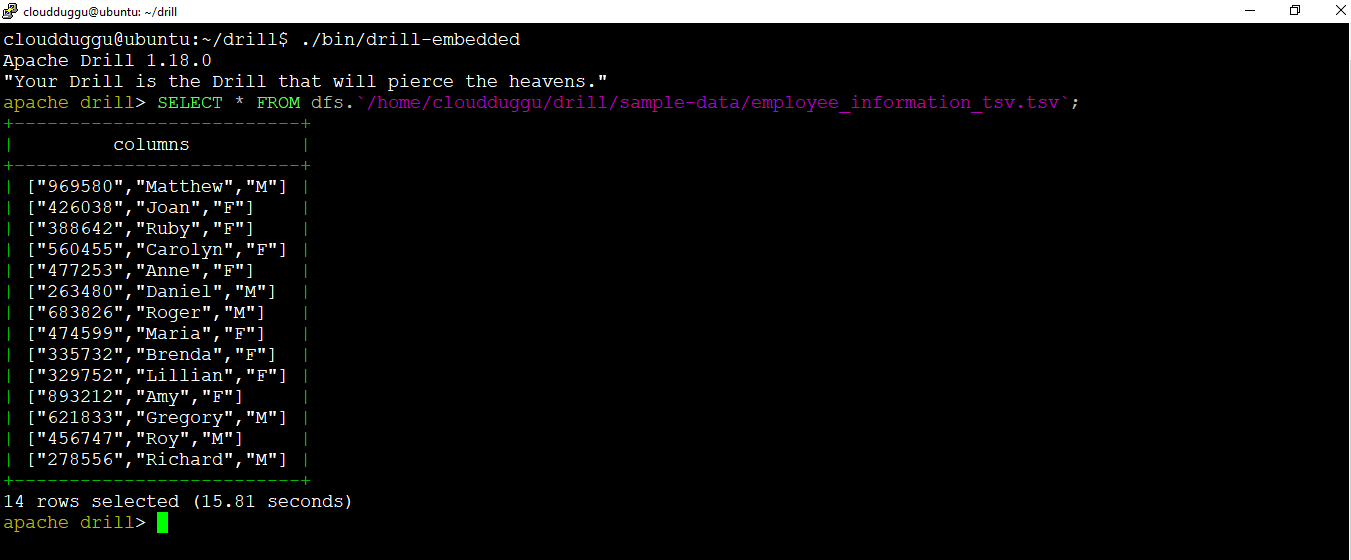
2.1 Query TSV Files Format
We will run the below select query to fetch the data that is present in the "employee_information_tsv.tsv" file.
Command:
Output:
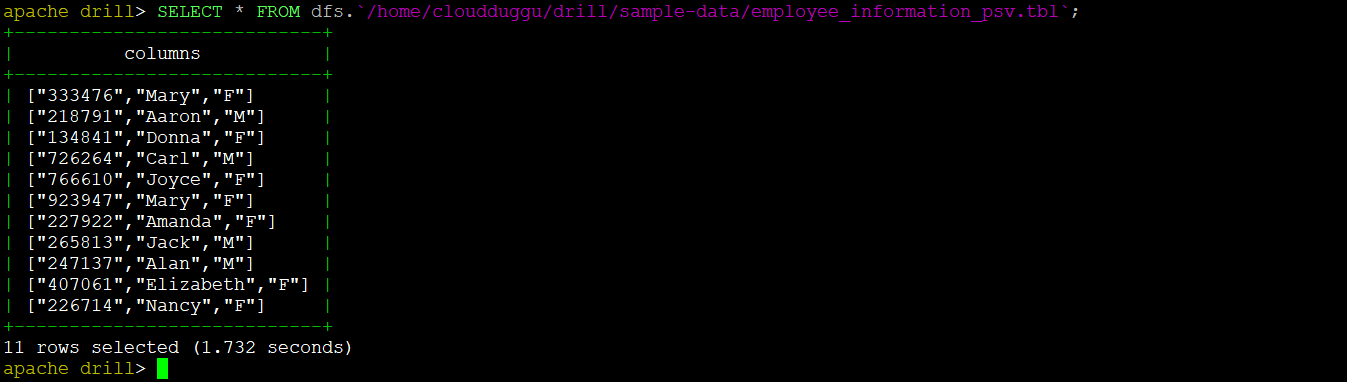
3. PSV Files Format
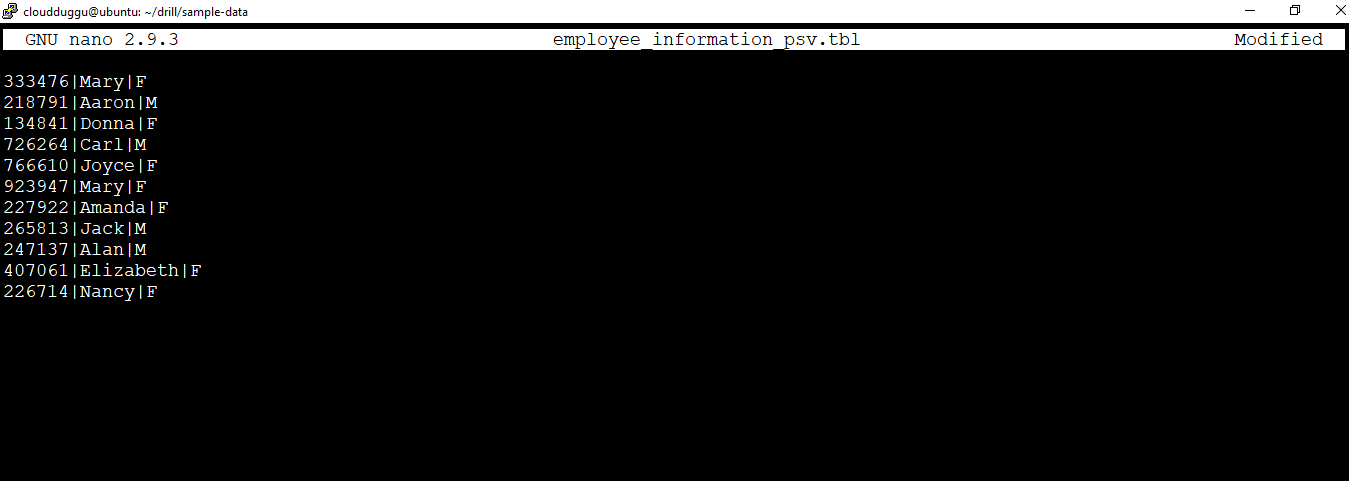
We will create a PSV file with the name "employee_information_psv.tbl" and fetch the data using the Drill select query.
The content of the PSV file is as mentioned below.
333476|Mary|F
218791|Aaron|M
134841|Donna|F
726264|Carl|M
766610|Joyce|F
923947|Mary|F
227922|Amanda|F
265813|Jack|M
247137|Alan|M
407061|Elizabeth|F
226714|Nancy|F
Command:
We have used a nano editor to create the "employee_information_psv.tbl" file and put the above records. To save the file press CTRL+O and to exit from the file press CTRL+x.
Output:
3.1 Query PSV Files Format
Let's run the below select query to fetch the records of "employee_information_psv.tbl".
Command:
Output: