What is Apache Drill?
Apache Drill is a schema-less SQL query engine that is used to process and analyze large-scale datasets. The inspiration for Drill is taken from Google'Dremel which is a Google query engine used to process large data sets. The Drill is capable of handling the petabytes of data that are spread over a cluster of nodes. It processes Adhoc requests with low latency. Drill supports a variety of file systems such as Hadoop HDFS, HBase, MapR-DB, Amazon S3, Google Cloud Storage, Alluxio, Azure Blob storage, and NoSQL databases such as MongoDB.
Why Apache Drill?
The following are some of the strong reasons to use Apache Drill.
1. Setup in Few Minutes and Start Working
Apache Drill can be set in few minutes, it is just that need to untar the drill setup file and Linux, Windows, or the Mac system and start the Drill. There is no additional setup is required in terms of infrastructure and no need to set up schema as well.
2. Schema-Free JSON Model
Drill SQL engine does not require a schema, it is capable of understanding the structure of data automatically. It follows the same schema-free JSON model which Elasticsearch and MongoDB follow.
3. Support Real SQL
Apache Drill supports the SQL language standard SQL:2003 syntax so for a user who already knows SQL is easy to query data using the drill. It also provides the supports for data types such as VARCHAR, TIMESTAMP, INTERVAL, DATE, and DECIMAL, and joining supports in where clause.
4. Supports Standard BI Tools
Apache Drill provides the JDBC and ODBC drivers to connect the standard BI tools such as MicroStrategy, Tableau, Spotfire, Qlik, SAS, excel for fetching data from non-relational datastores.
5. Query complex, semi-structured data in-situ
Using Apache Drill, we can work with complex and semi-structured data in-situ because it uses a schema-free JSON model. Also, we need to note that before processing, there is no transformation of data is required.
6. Access Various Types of Data Sources
The Drill is designed in such a way that it can with any other data source using its storage plugin such as Hadoop HDFS, Amazon S3, MapR-FS. Hive, HBase, etc. We can combine the data in a SQL query on the fly from different data stores.
7. Scale from Single to 1000 Nodes Cluster
Apache Drill can be easily installed on a single computer and start working in an embedded mode also it can be easily scaled to the cluster of commodity hardware and provides the best performance. Drill uses the optimistic pipelined model to aggregate cluster nodes memory for better SQL query execution and if a working data is not fitting in memory then it automatically scatters to disk.
8. Support For User-Defined Functions(UDFs)
Apache Drill supports the custom users-defined UDFs by providing a Java API. We can create our UDFs and use them in Drill. If there is a UDF created in Hive then that also can be used in Apache Drill.
9. Queries on Hive Tables
Apache Drill can access the data stored in Hive and run the query on those data. We can easily join the Hive table with HBase or other log files and fetch data.
10. High performance
Apache Drill is developed in such a way(based on schema-free JSON model) that it provides unparalleled flexibility and the best performance. Drill does not use any execution engine such as Spark, MapReduce, or Tez. It uses cost-based and rule-based optimization techniques for better execution. Drill efficiently uses the memory and CPU by using its vectorized execution and columnar engine.
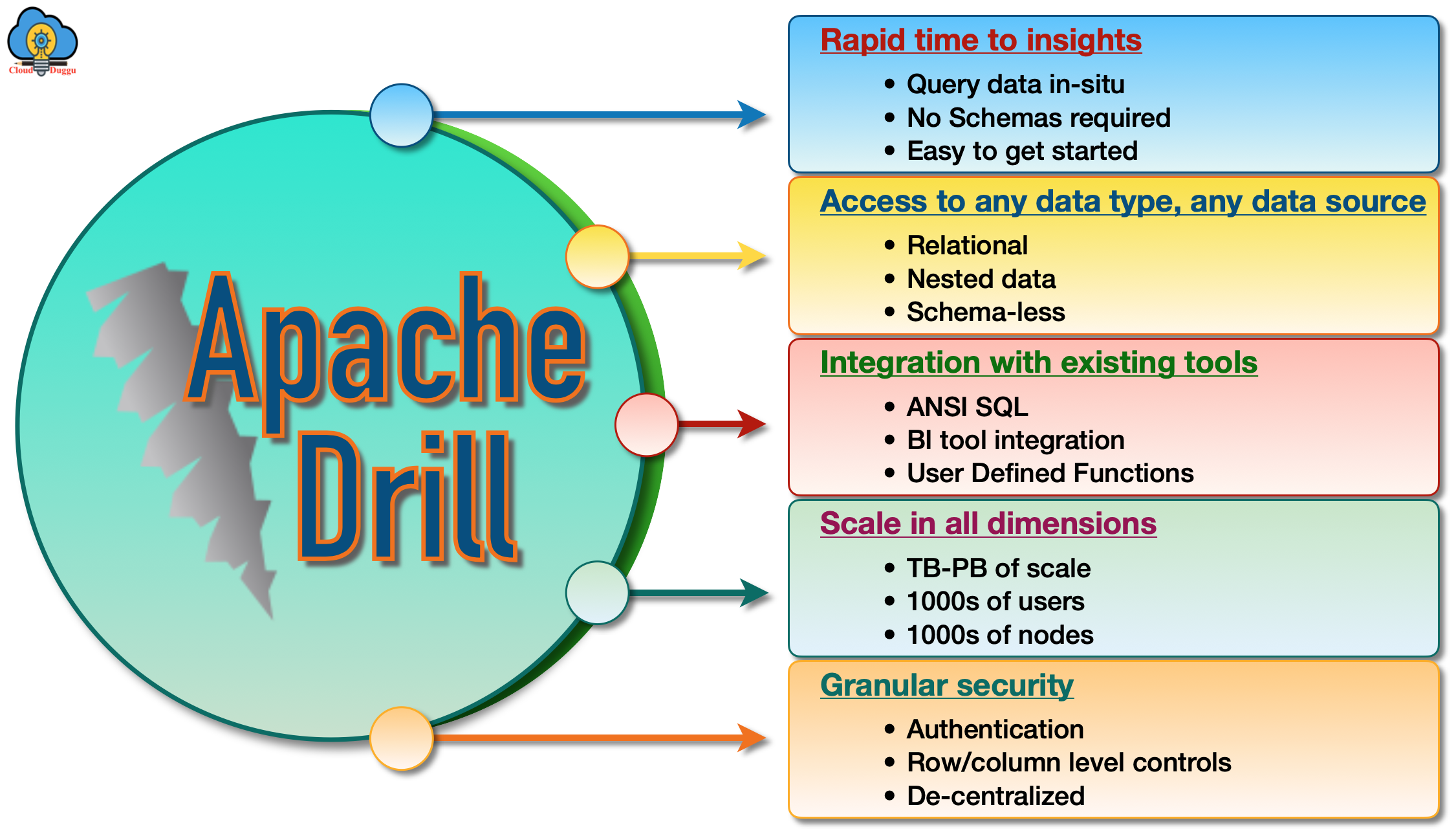
Apache Drill Key Features
The following are some of the important features of Apache Drill.
- Apache Drill Model is based on a schema-free JSON format that is very similar to Elastic search and MongoDB.
- It supports industry-rich API standards such as ODBC/JDBC, ANSI SQL, RESTful APIs, etc.
- The pluggable architecture of Apache Drill opens the door for other datastore systems to connect with Drill.
- Apache Drill can easily scale from one system to 1000 systems and process the request in distributed and optimize way.
- Apache Drill is a columnar execution engine that processes complex and schema-free data and for that Drill uses the columnar data representation.
- Apache Drill uses multiple compilers and the ASM-based bytecode rewriting to check the query and optimize it from the best performance.
- The Drill follows the pipeline execution method and processes data in memory and avoids using the disk unless it is required.
The below figure represents the features of Apache Drill.
Apache Drill Version Releases
The following are the date-wise Apache Drill release.
| Sr No | Apache Drill Release | Month & Date |
|---|---|---|
| 1 | Drill 1.0 Released | May 2015 |
| 2 | Drill 1.1 Released | July 2015 |
| 3 | Drill 1.2 Released | October 2015 |
| 4 | Drill 1.3 Released | November 2015 |
| 5 | Drill 1.4 Released | December 2015 |
| 6 | Drill 1.5 Released | February 2016 |
| 7 | Drill 1.6 Released | March 2016 |
| 8 | Drill 1.7 Released | June 2016 |
| 9 | Drill 1.8 Released | August 2016 |
| 10 | Drill 1.9 Released | November 2016 |
| 11 | Drill 1.10 Released | March 2017 |
| 12 | Drill 1.11 Released | July 2017 |
| 13 | Drill 1.12 Released | December 2017 |
| 14 | Drill 1.13 Released | March 2018 |
| 15 | Drill 1.14 Released | August 2018 |
| 16 | Drill 1.15 Released | December 2018 |
| 17 | Drill 1.16 Released | May 2019 |
| 18 | Drill 1.17 Released | December 2019 |
| 19 | Drill 1.18 Released | September 2020 |
Comparison Between Drill, Hive, and Impala
The below is the list of comparisons between Apache Drill, Hive, and Impala.
| Parameters | Apache Drill | Apache Hive | Apache Impala |
|---|---|---|---|
| Latency | Low | Medium | Low |
| Files Support | All Hive File Formats and JSON, Text file, etc. | All Hive File Formats. | Parquet, Sequence |
| HBase/M7 Support | Yes | Yes, But the performance issue is there. | Yes, But with an issue. |
| Schema | Hive or Schema Less | Hive | Hive |
| SQL Support | ANSI SQL | HiveQL | HiveQL |
| Client Support | ODBC/JDBC | ODBC/JDBC | ODBC/JDBC |
| Hive Compat | High | High | Low |
| Large Dataset Support | Yes | Yes | Limited |
| Nested Data Support | Yes | Limited | No |
| Concurrency | High | Limited | Medium |
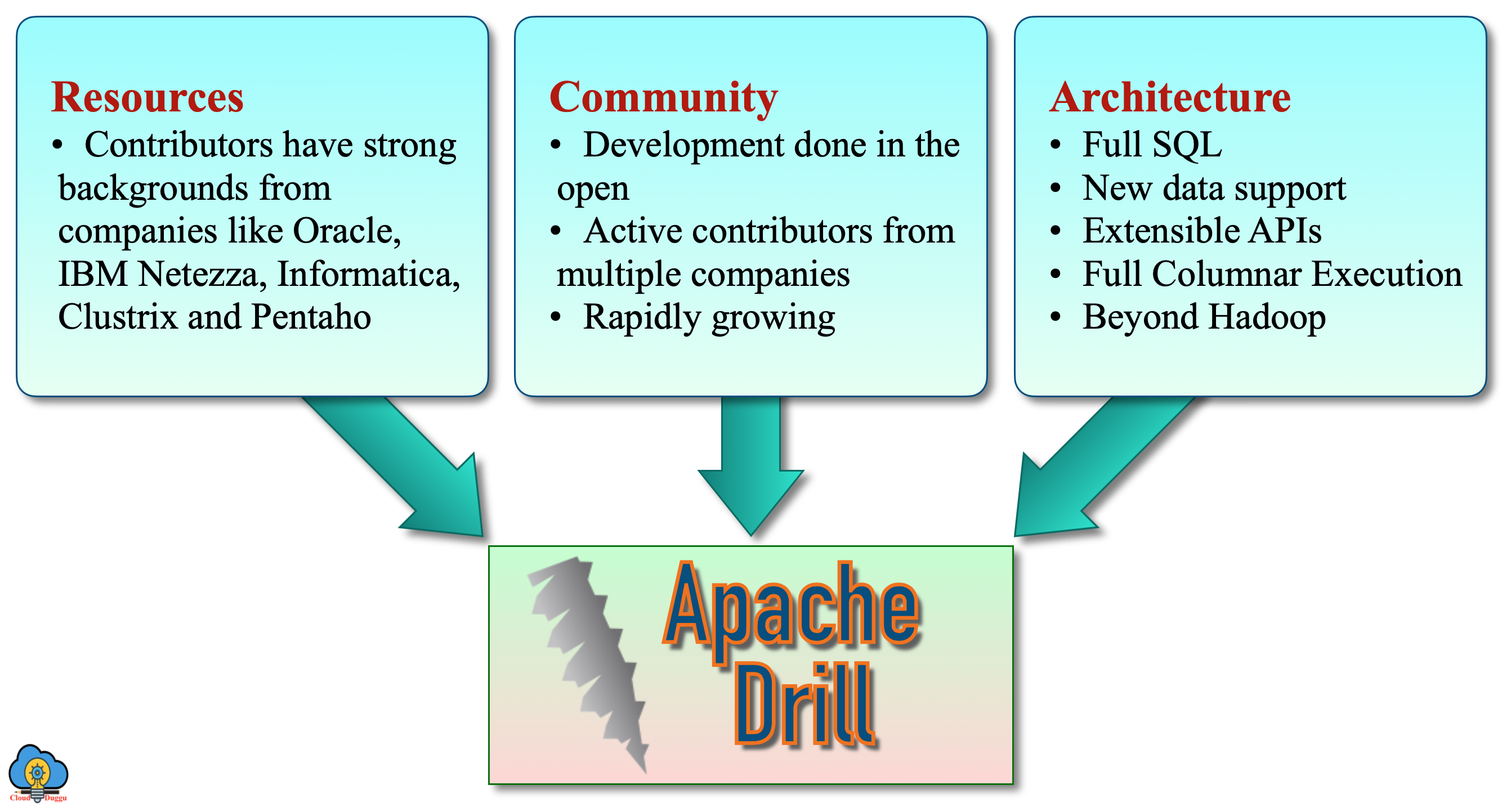
Why Apache Drill is Successful?
The are multiple strong reasons behind the success of Apache Drill and the below figure are representing some of them.