1. What is Apache Drill?
Apache Drill is a schema-less and open-source SQL engine that is used to process the larger data set, semi-structured data which are getting generated from the new era Big data applications. Drill provides the facility of plug-and-play integration with the Hive and Hbase deployments. The Apache Drill is inspired by Google's Dremel file system. We can get a faster insight into data analysis without worrying about schema creation, loading, or any kind of maintenance activity that used to happen in the RDBMS system. Using Drill we can easily analyze the multi-structured data.
2. Why should we use Apache Drill?
The following are some of the important reasons to use Apache Drill.
- Start the Apache Drill by just untaring it and start using it in local mode. It requires no infrastructure setup or creating schema creation.
- It requires no schema to run SQL queries.
- Using Drill, we can query the semi-structured and complex data in-situ.
- Apache Drill is capable to support the SQL:2003 syntax standard.
- BI tools such as QlikView, Tableau, and MicroStrategy can be easily integrated with Drill to provides the analytical capability.
- We can run the interactive query on Drill that will access the table present in Hive and HBase.
- Drill supports multiple data stores such as local file systems, distributed file systems, Hadoop HDFS, Amazon S3, Hive tables, HBase tables, and so on.
- Apache Drill can be easily scalable from a single system up to 1000 nodes.
3. What are the major capabilities through which Apache Drill achieves high performance?
The following are the major capabilities through which Apache Drill achieves high performance.
- Execute the query in a distributed manner.
- Using the Columnar execution Drill process the schema-free and complex data.
- Apache Drill can compile and recompile the code at run time.
- Drill uses the memory to perform the execution and uses the disk very little until it is required.
4. What are the Datastores that are supported by Apache Drill?
Apache Drill is designed to supports primarily the non-relational datastores and the following are some of the datastores supported by Drill.
- The distribution of Hadoop which are Apache Hadoop, Amazon EMR, MapR, Cloudera distribution, and so on.
- It supports NoSQL databases such as MongoDB, HBase.
- It supports cloud storage such as Azure Blog Storage, Amazon S3, Google Cloud Storage, and so on.
5. What are the clients which are supported by Apache Drill?
The below are clients supported by Apache Drill.
- Support for ODBC/JDBC driver for BI tools such as MicroStrategy, Tableau, Business Objects, Excel, QlikView, and so on.
- Support for REST API for custom applications.
- Support for Java and C libraries for Java and C applications.
6. Is Apache Drill alike to Spark SQL?
Apache Drill is not similar to Spark SQL because Spark is developed to use SQL in Spark programs whereas Drill works independently and not dependent on Spark. Apache Drill is used by developers, analysts, Business users, and so on.
7. Is Apache Drill a replacement for Apache Hive?
Both Tools Hive and Drill are used to query the larger datasets where Hive is most suitable for batch processing for long-running jobs whereas Drill provides more advancement and better user experience than Hive. The limitation of Drill is not till Hadoop but it can access and process data from other sources. It is capable of querying the NoSQL databases such as HBase, Mongo DB, cloud storage such Azure Blob Storage, Amazon S3, Swift, Google Cloud Storage.
8. Can we use schema defined in Hive metadata with Drill?
We can use the Apache Drill storage plugin for Hive to connect with Hive Metadata and perform the SQL query over Hive. Drill single cluster can be connected with the multiple Hive nodes and perform the join query.
9. What is the standard of SQL supported by Apache Drill?
Apache Drill supports the standard ANSI SQL:2003 syntax also provides the various functions to explore the complicated datasets such as KVGEN and FLATTEN functions. Apart from this Drill supports the basic SQL such as Create Schema, Create Table, Create View, Alter statement, Drop table, Drop View, Describe, Show, Select, Create function, and so on.
10. Do we need to load the data in Apache Drill before running the query?
We don't need to load data in Drill because Drill is capable of querying the data in ‘in-situ’. It uses storage plugins to check the data type of query the datasets.
11. What is Drillbit in Apache Drill?
Drillbit is the process the receives the client request in the form of a query and responsible to plan distribute and process the request. In the Apache Drill cluster, each node has a Drillbit process that is responsible for processing the request. The first node that receives the user request acts as Foreman which is responsible for driving query execution from start to end.
12. What are the core models of Drillbit?
The Drillbit has the below key components.
- RPC Endpoint:- Using RPC protocol, a client can interact with Apache Drill. Another way to communicate with Drill is by connecting with Zookeeper to check the available Drillbit node and then make a connection.
- SQL Parser:- For parsing of the client request, the Calcite SQL parser framework is used by Apache Drill.
- Storage Plugin Interface:- Using the Storage plugins, Apache Drill interacts with the different data sources and runs the query.
13. What are the core elements of Apache Drill that are responsible for best performance?
The following are the core elements of Apache Drill that provide the best performance.
- Distributed engine
- Columnar execution
- Vectorization
- Runtime compilation
- Optimistic and pipelined query execution
14. How to start Apache Drill?
We can start the Apache Drill in embedded mode using the below command.
cloudduggu@ubuntu:~/drill$ ./bin/drill-embedded15. How to start Apache Drill Web user interface?
To access the Apache Drill user interface just type the http://localhost:8047 or the http://Drill HOST IP address:8047 in the web browser address bar. The Apache Drill should be running in embedded mode in order to access the Drill web user interface.
16. What are the activities that we can perform with the Apache Web user interface?
Below list of the task, we can perform from the Apache Drill Web interface.
- We can run the SQL Queries from the Query tab.
- We can the running queries and cancel them as well.
- We can check the query profile to view the executed queries.
- The storage plugins can be seen in the storage tab.
- We can view logs and metrics in the log tab.
17. How to check the multi-version of Apache Drill in a cluster?
We can use the below commands to check the version detail of Apache Drill.
apache drill> SELECT * FROM sys.drillbits;18. What is the secure path of communication with Apache Drill?
The below are the 4 secure communication paths to connect with Apache Drill.
- Connect Drillbit using Web Client.
- Connect Drillbit using the Java and C++ client.
- Connect ZooKeeper using Java client and Drillbit.
- Connect Drillbit using Hive Storage Plugin.
The below figure represents the secure communication path with Apache Drill.
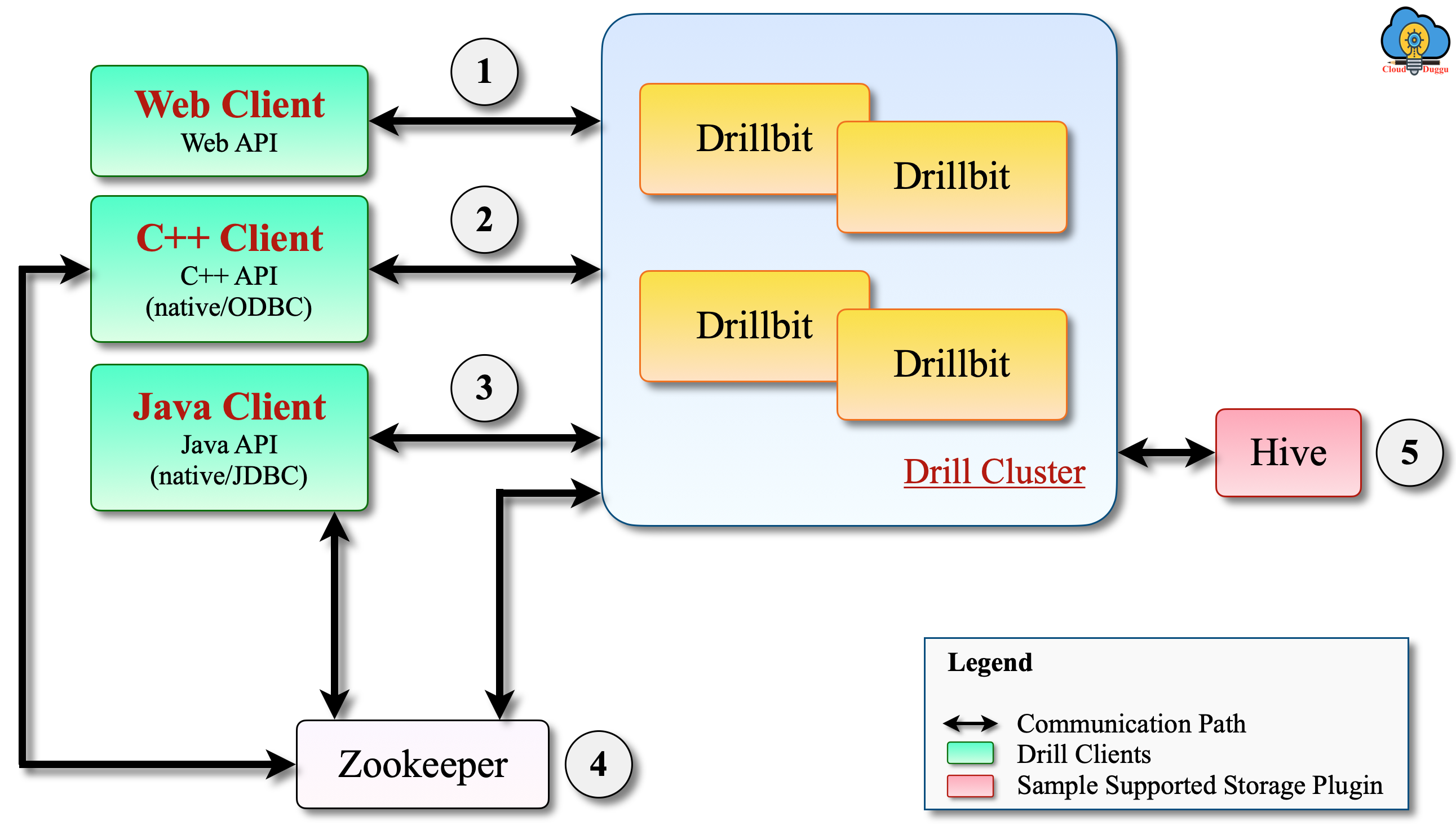
19. What are the Data Storage Plugins supported in Apache Drill?
The below is the list of Data Storage Plugins which are supported in Apache Drill.
- File System Data Source Storage Plugin
- HBase Data Source Storage Plugin
- Hive Data Source Storage Plugin
- MongoDB Data Source Storage Plugin
- RDBMS Data Source Storage Plugin
- Amazon S3 Data Source Storage Plugin
- Kafka Data Source Storage Plugin
- Azure Blob Data Source Storage Plugin
- HTTP Data Source Storage Plugin
- Elastic Search Data Source Storage Plugin
20. What are the type of files that can be queried from Apache Drill?
The below list of files can be queried by Apache Drill.
- Avro Files
- JSON Files
- Parquet Files
- Directories
- Sequesnce Files
- Plain text Files
21. How to run a select query against a JSON file in Apache Drill?
We can use the below select command against the JSON file to fetch its records.
select * from cp.`employee.json` limit 10;22. What is the performance tunning technique suggested for Apache Drill?
To perform the performance tunning in Apache Drill a user must be knowing the data and query plan and source of data. Once these areas are identified then the user can apply the following performance tunning technique to improve the performance of a query.
- Perform the modification of query planning options.
- Per requirement modify broadcast join options.
- Perform the Switching of aggregation between 1 or 2 phases.
- We can enable or disable the hash-based memory-constrained operators.
- Per requirement, we can enable query queuing.
- Put the Control over the parallelization.
- Organize data in the form of partition.
23. How many types of joins are used in Apache Drill?
There are 2 types of joins used in Apache Drill as mentioned below.
- Distributed Joins
- Broadcast Joins
24. What are the functions to query directories in Apache Drill?
The function to query the directory are mentioned below.
- MAXDIR
- MINDIR
- IMAXDIR
- IMINDIR
25. How to check the Foreman node in Apache Drill?
We can identify the Foreman node using the below SQL query.
apache drill> SELECT hostname FROM sys.drillbits WHERE `current` = true;26. What is the command to find out the Apache Drill version?
We can use the below command to check the Apache Drill Version.
apache drill> SELECT version FROM sys.version;27. How to enable the Verbose Error option in Apache Drill?
Use the below SQL to enable the Verbose Error option.
apache drill> ALTER SESSION SET `exec.errors.verbose` = true;28. What is the command to create a table in Apache Drill?
We can create a table in Apache Drill using the CREATE TABLE AS (CTAS) command. For example, if there is a JSON dataset named "empdetail.json" and based on that we need to create a table name "empdata_detail" then the SQL would be as below.
apache drill (dfs.tmp)> CREATE TABLE empdata_detail as SELECT * FROM dfs.`/home/cloudduggu/drill/sample-data/empdetail.json`;29. What will you do if a query in Apache Drill is taking time to return the result?
If a query is taking time to return the result from Apache Drill then check the following points.
- Check the profile of the query to see if it is moving or not. The last update and last change time will determine the query progress.
- Optimize the operation where Apache Drill is taking time.
- Look for the operation like partition pruning and projection pushdown.
30. What will you do if you are receiving error java.net.BindException: Address already in use while starting Apache Drill in an embedded mode?
In an embedded mode you can run only one Drillbit per node and if it is already running and you are trying to run again in that case Drill throws this error. To resolve this error try to stop it or kill the PID using Kill -9 command.