Apache Drill framework is developed in such a way that it can scale without having any compromisation with the Hadoop system or the NoSQL databases. It provides the best performance in the SQL ecosystem that includes relational systems, Hadoop systems, NoSQL databases, etc.
The following are some of the core architectural elements that make Apache Drill Flexible and deliver the best performance.
Drill Flexibility
The following are the come of the elements that make Apache Drill Flexible.
1. Flexible Data Model
Apache Drill is designed to process complex and multi-structured data which includes clickstream, IoT-based sensor data, mobile generated data, social medial generated data. Such data are usually stored in Hadoop systems and the NoSQL databases. Drill uses the hierarchical columnar data model to process such complex and structured data without having worried about its materialization in terms of design time and execution time.
2. Schema Discovery Dynamically
To process a query, Apache Drill does not need a schema, instead, it starts processing of query in the form of record-batches and finds out the schema of data on the fly during query processing time. There is the data format that is self-describing such as JSON, Parquet, AVRO, and the NoSQL databases in which the schema is already defined so Drill uses those schemas on run time to process the query. The Drill operators are also designed in such a way that in case the schema is changing then these operators will reconfigure themselves.
3. Decentralized Metadata
The metadata is used to store the information about the objects which are present in the database but Apache drill will not have the metadata required to run a query. Drill uses the storage plugins to get the metadata information from the data source while running a query. Although a user can create metadata in Drill using the SQL DDL commands and accessible through the ANSI standard INFORMATION_SCHEMA database.
4. Extensible Architecture
Apache Drill is extensible at all layers of its architecture, either it's about the storage plugin layer, query execution/optimization layer, client APIs layer. We can customize any layer of Drill depending upon the use cases. The Drill plugin concept and the built-in classpath scanning helps to combine more storage plugins and operators with less effort.
Apache Drill Architecture provides the below list of capabilities.
- For implementing the custom UDFs/UDAFs, Drill provides Java APIs.
- Using its custom storage plugins, not only Hadoop but we can connect other data sources such as relational databases MSSQL, Oracle, and the non-relational data stores such as Cassandra, MongoDB.
- Custom operators can be implemented by using APIs.
Drill Performance
Apache Drill is developed in such as way that it provides better performance for large data sets.
The following are some of the core elements of Apache Drill that help Drill to provide the best performance.
1. Powerful Distributed Execution Engine
Apache Drill process users query using its powerful distributed execution engine. A user has the freedom to submit a query on any node of the cluster and gets the best performance. To support more data volume, more nodes can be added to the cluster.
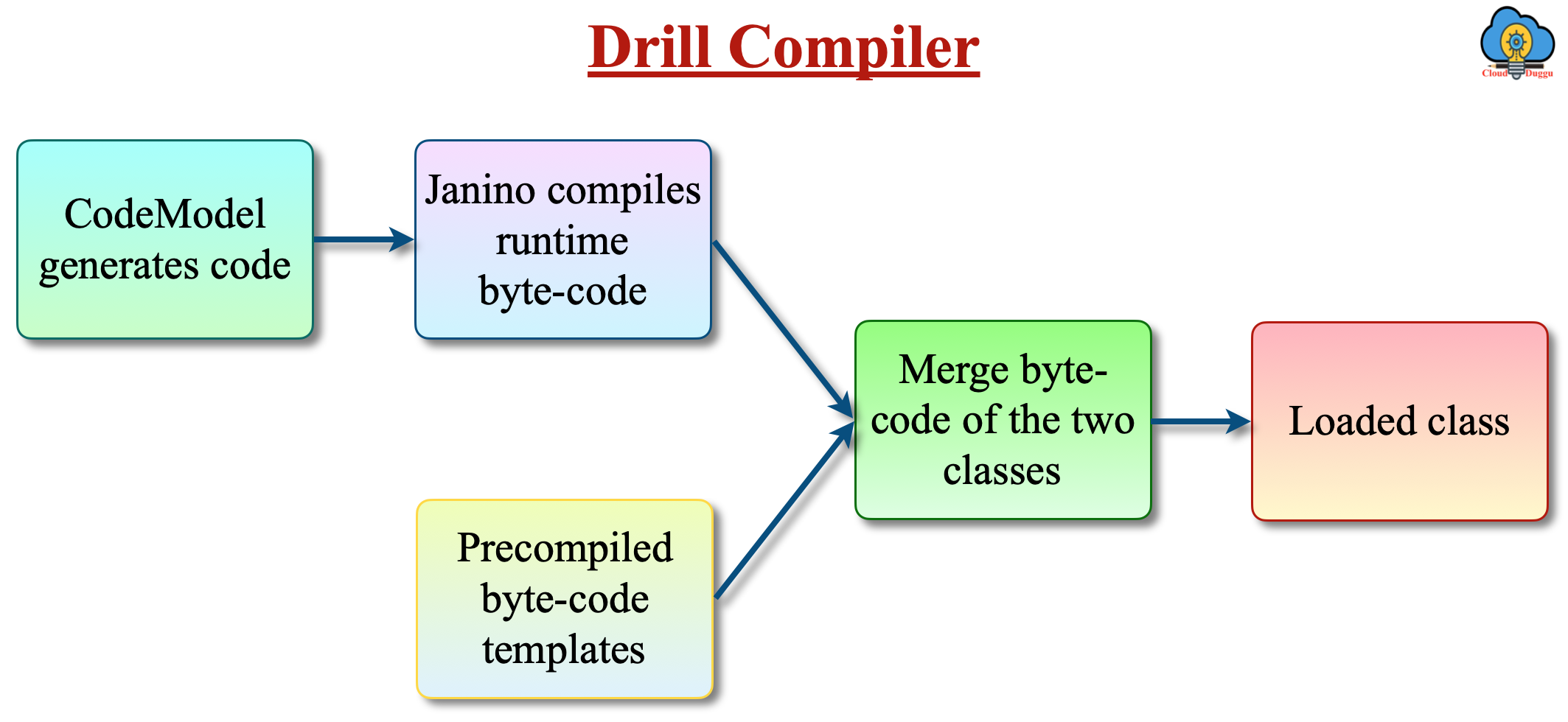
2. Runtime Compilation
Apache Drill performs the run time compilation of each query and operator and generates the custom code. Compare to the integrated code execution the runtime compilation is much faster.
The following is the Drill run time code generation process flow.
3. Columnar Execution
Drill provides the optimized performance for columnar storage and in-memory data execution model. When Drill processes the columnar data format such as Parquet, then it avoids the usage of in disk if a column is not participating in query execution and provides a SQL execution layer to perform the direct SQL processing on columnar data. In this way, the columnar storage and direct query execution utilized less amount of memory and provides the best performance for BI/Analytic type of workloads.
4. Pipelined Query Execution
Drill uses the pipelined query execution model to process the query. In this model, all tasks are scheduled at once and execution is performed in memory so that data movement becomes very fast. The data will be persisted in disk only in case of memory overflow.
5. Vectorization
Using Vectorization, Drill process the data in records batches despite processing single table records. The processing of data in records batches is the modern CPU chip technology that was not there in traditional databases due to query complexity.