What is the Architecture of Apache Drill?
Apache Drill is the first schema-less SQL engine that is capable of processing large datasets that includes structured, semi-structured/nested data. It is designed in a way that it can scale from one system to a thousand systems to process the interactive queries that are needed by the BI tools. Drill provides support for different types of No SQL databases such as Amazon S3, MongoDB, Google Cloud Storage, MapR-DB, Azure Blob Storage, HBase, MapR-FS, Hadoop HDFS, NAS, and local files and joins data from multiple datastore.
In traditional databases first, we need to define the schema and perform some transformation on data and then we can perform the query on that data but the Apache Drill schema-less feature allows users to just include the location of Hadoop HDFS, Amazon S3, and run queries.
Apache Drill architecture is a distributed execution environment that is used for large data sets processing. The core of Apache Drill architecture is the Drillbit service that is responsible to accept the user request, process it, and send the result back to the user. In a cluster environment, the Drillbit service can be installed on all required cluster nodes to provide a distributed cluster processing. When drill works in a cluster environment, then it uses the data locality feature despite moving data over the network from one node to another node. Apache Drill can be deployed and works on any distributed cluster environment and not only tied with Hadoop.
The following is the high-level architecture diagram of Apache Drill.
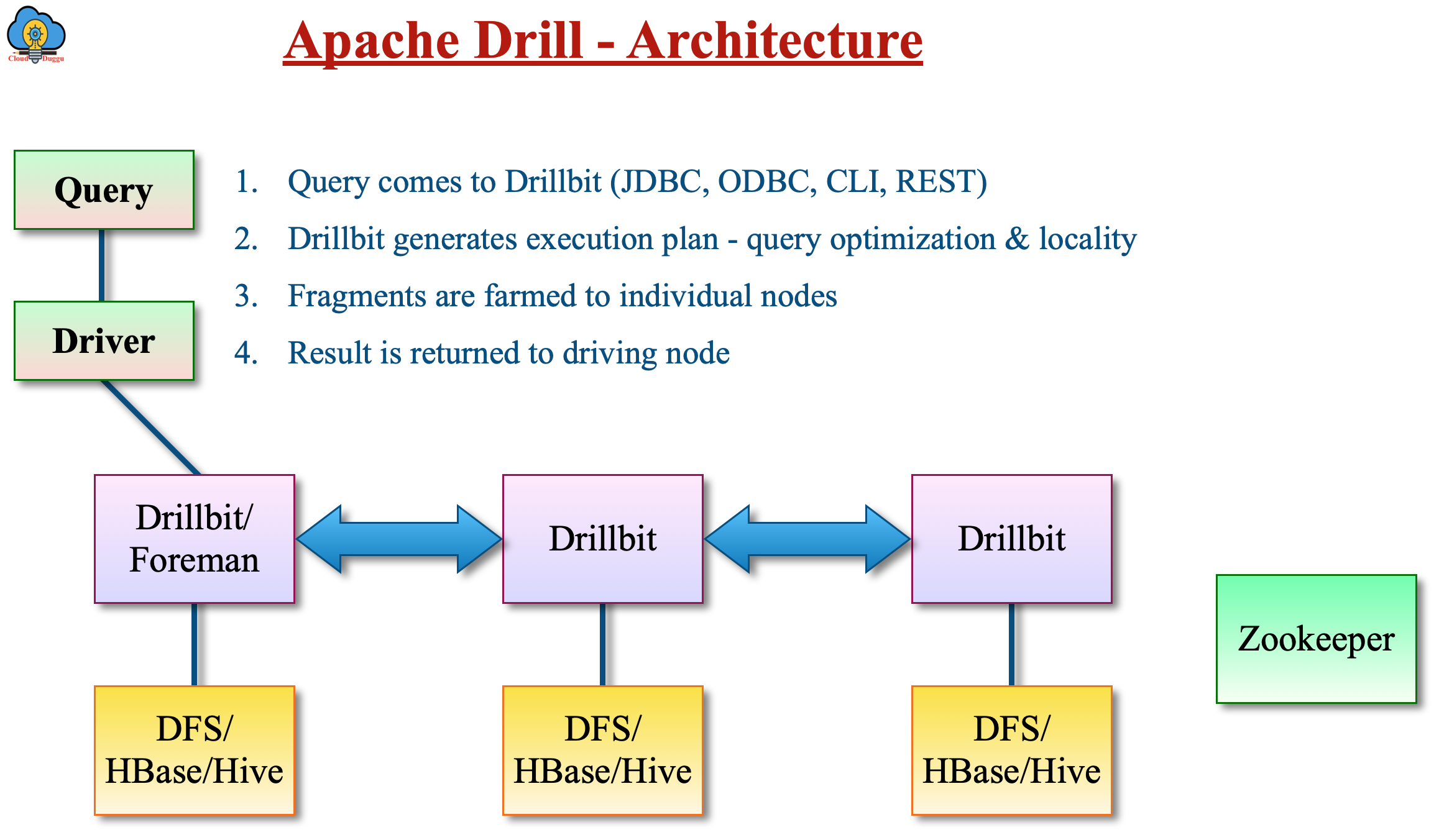
Drill Query Flow Steps
The following steps are involved to process a Query in Apache Drill.
- The Drill client will send a query request using any medium of communication such as JDBC, ODBC, REST API, or the command-line interface.
- The Drillbit receives the request from the client. There is no concept of Master and Slave in Drill any Drillbit can accept the request from the client.
- The Drillbit takes the query and performs parsing and optimization and generates a distributed execution plan for effective and fast execution.
- In the Apache Drill cluster, the Drillbit that received the user's query will act as a driving Drillbit node. Now the driving Drillbit node will check the available Drillbit nodes from Zookeeper and assign the work to the appropriate Drillbit node for execution.
- The Nodes perform their part of the job and send the result to the Driving Drillbit node.
- After receiving data from all nodes, the Apache Drill driving drillbit node sends the output to the user.
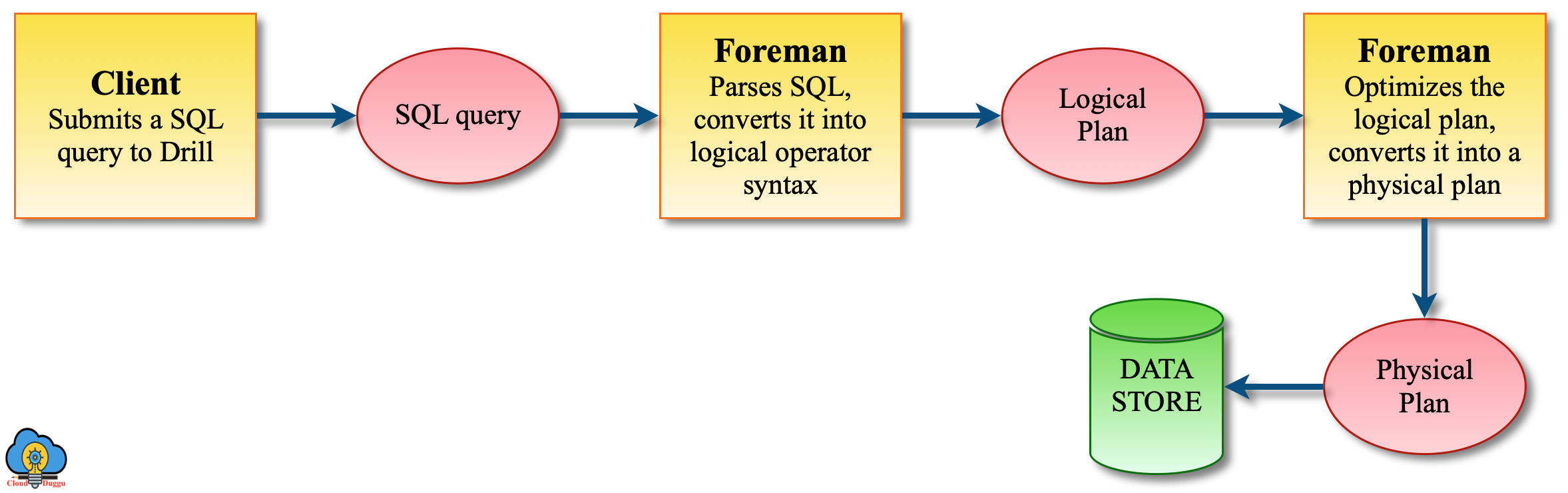
The following figure represents the high-level query execution flow in Apache Drill.
Drillbit Components
The following figure represents the different modules of Apache Drillbit.
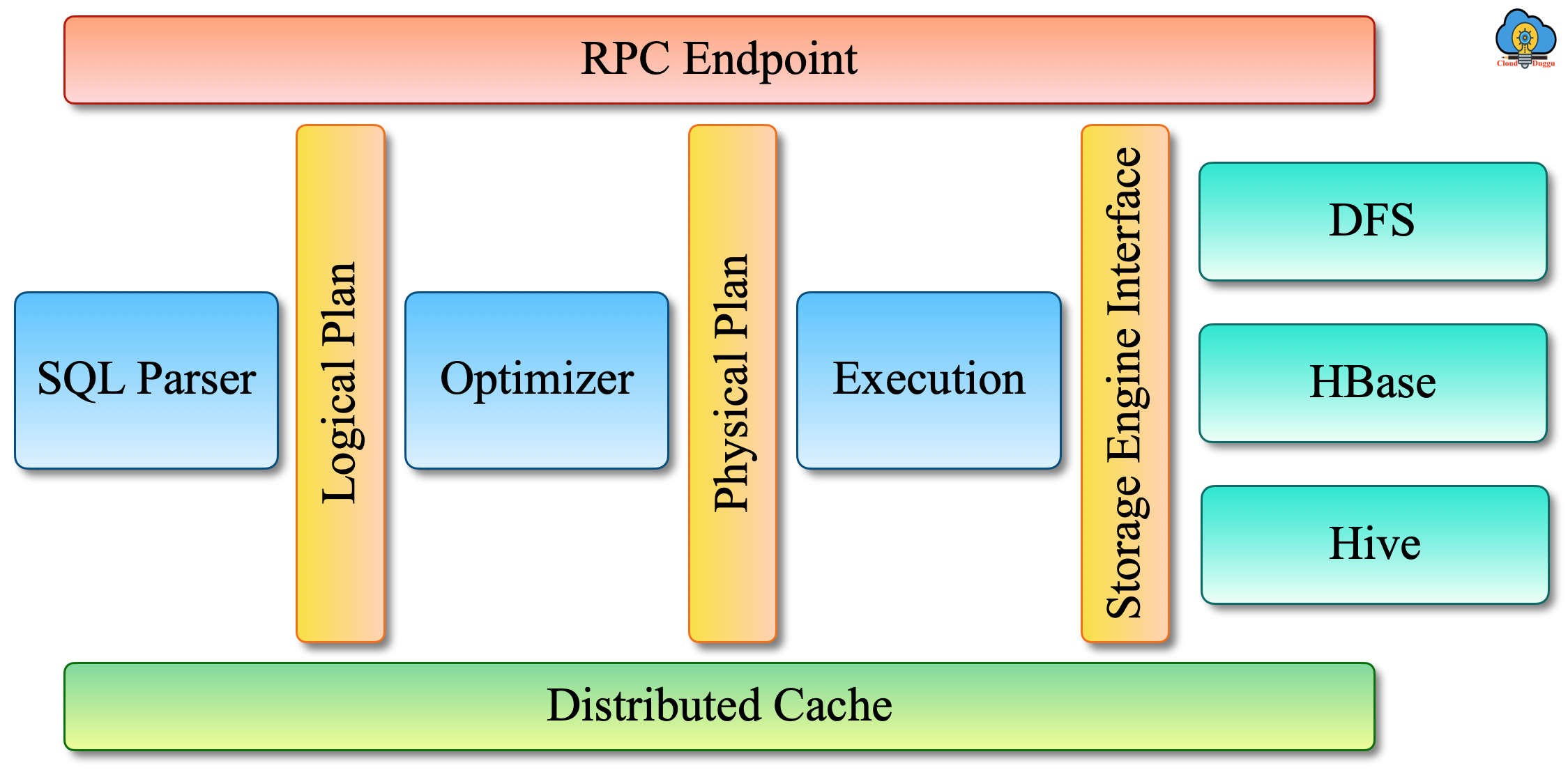
Let us see each Drillbit module in detail.
1. RPC End Point
Drill provides the RPC protocol to make the connection with the clients. It is a low overhead protobuf-based protocol. Additionally, clients can use the Java APIs and C++ APIs to make the connection with Drill. The client can interact with Zookeeper to check the available Drillbit for connection or the client can directly connect with the specific Drillbit.
2. SQL Parser
Drill uses Optiq for parsing operation. After the parsing operation, the logical plan is generated that is a computer-friendly representation of the query.
3. Optimizer
Drill uses cost-based & rule-based optimization techniques to perform the optimization. It also uses the data locality and other storage engine optimization rules to perform the optimization. After optimization, the query plan is generated that shows an effective and fastest way of query execution over the cluster of nodes.
4. Execution Engine
Drill MPP execution engine performs the actual execution of query across multiple nodes.
5. Storage Plugin Interfaces
Drill uses Storage plugins to connect with different data sources. The storage plugins provide the following information to the Apache Drill.
- It provides the metadata information that is available in the source system.
- It provides an interface to perform read and write operations to the data source.
- It also provides the detailed location of data and the optimization rules to execute Drill queries quickly on data so.
6. Distributed Cache
Apache Drill uses the distributed cache to store the metadata information which includes the query plan, query execution intermediate state, fragments, etc. Drill uses the Infinispan technology to manage the distributed cache.