What is Apache Oozie Coordinator?
Apache Oozie workflow can be started manually and on an ad-hoc basis by using Oozie command-line tool but this is not sufficient in all cases. There are some cases in which this practice is not sufficient. For example, if a workflow needs to start based on some external factors such as if a workflow job needs to start by 4 AM every day, this condition is very hard to achieve using the Oozie CLI tool.
Apache Oozie coordinator is used to resolve such trigger-based workflow execution. It provides a simple framework to give triggers or predicts and then it schedules the workflow based on those predefined triggers. It helps administrators to monitor and control the workflow execution depending on cluster conditions and application-specific limits.
Apache Oozie Coordinator Trigger Mechanism
Oozie Coordinator supports two triggering mechanisms, the first one is time and the second one is data availability.
Let us see each triggering mechanism in detail.
1. Time Trigger
In a time trigger mechanism, a workflow is executed at fixed intervals or frequency. A user can mention a time trigger in the coordinator using below three attributes.
1.1 Start time (ST)
This attribute determines when to execute the first instance of the workflow.
1.2 Frequency(F)
This attribute specifies the interval for the subsequent executions.
1.3 End time (ET)
This attribute specifies that no new execution is permitted on or after this time.
2. Data Availability Trigger
An Oozie workflow job process some input data and generate output. So it is very simple to hold workflow job execution until we have all data present with us. For example, if we want to process a workflow at 2 AM but at the same time, we want to make sure that even if we don’t get data by 2 AM job should not be started. This is achieved by Oozie data dependency-based triggering framework.
Apache Oozie Coordinator Job Lifecycle
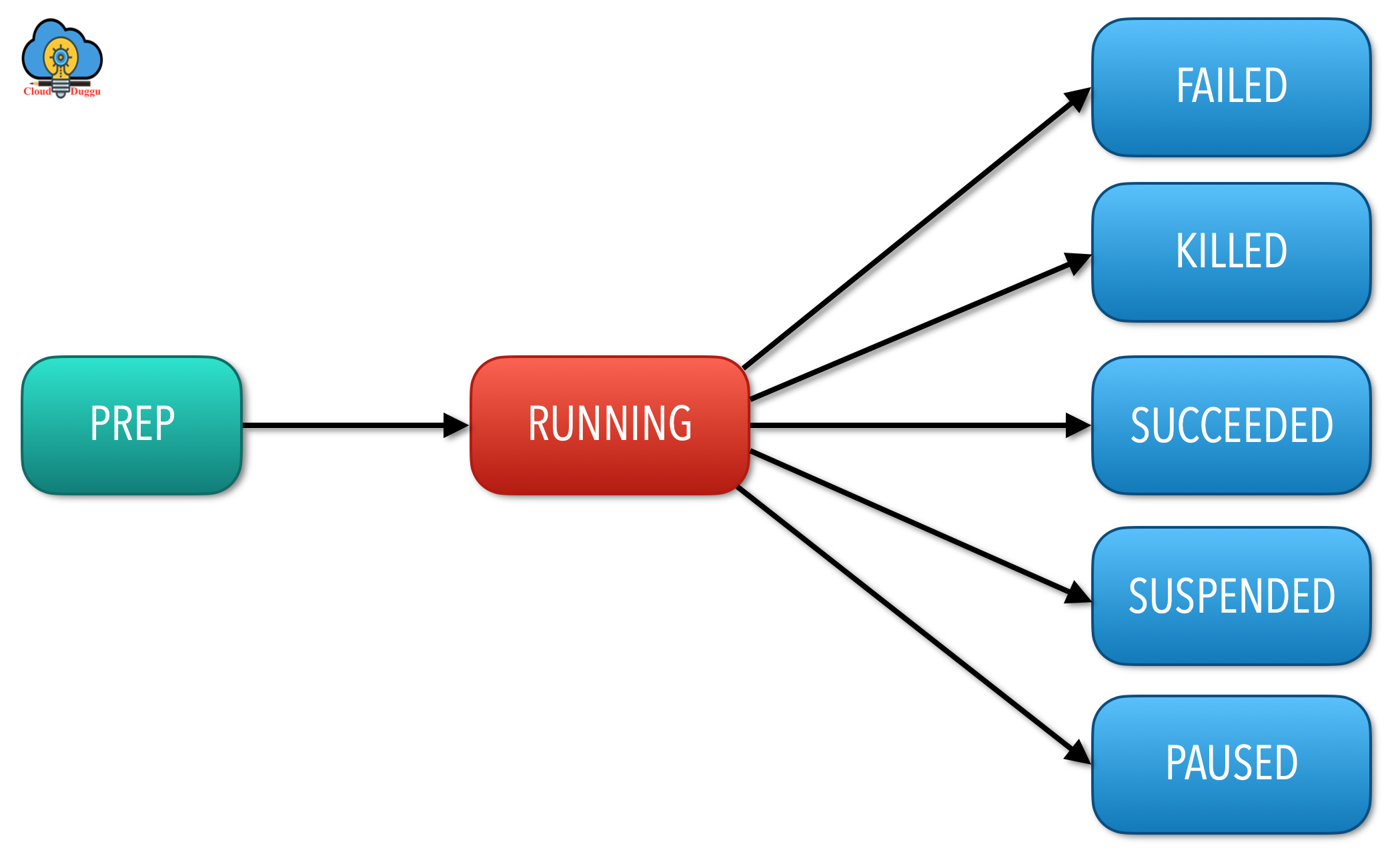
The Apache Oozie coordinator job is responsible to create a coordinator action that should run at a specific time. When a coordinator job is submitted to the Oozie service, Oozie parses the coordinator XML validates the configurations and generates job ID after that it changes the state of the job to a PREP state. The job state will be in PREP state till the time the actual job run time is reached. Once the actual run time is reached then Oozie moves the status of the job from PREP to RUNNING state. At any point in time, a user can terminate the job in that case job is moved to a SUSPENDED or PAUSED state.
The last state of a coordinator job depends on the states of all the spawned coordinator actions. Oozie marks the job to SUCCEEDED state if all coordinator actions arrive and actions are completed the same way Oozie marks job to FAILED state when all actions are failed. In case a job is failed or time out or killed and it is still showing in running state then Oozie moves the job from RUNNING to RUNNING_WITH_ERROR. Likewise, there would be other stats of jobs such as DONE_WITH_ERROR, SUSPENDED_WITH_ERROR, and PAUSED_WITH_ERROR. A user can explicitly kill a coordinator job, after that job moves to the KILLED state.
The following figure shows the life cycle of a Coordinator Job.