Trident is an additional, high-level concept build on top of Apache Storm. It provides a high-level API to perform stateful stream processing with a low level of latency. Trident uses Storm core components spout and bolt for its processing. Trident helps to achieve exactly-once processing compared to Storm core API. Trident provides functions such as join operations, aggregations, grouping, functions, and filters.
Trident topology need not required any extra configuration because it is built on top of Storm. Trident has a function such as aggregations, operations, functions, grouping, and joins.
Streams of data are processed in Trident in batches which are also called transitions and depending upon the input stream of data the batch size would be thousands or millions. This property makes Trident different from Storm. To process those small batches Trident uses beginCommit at starting and commit during the end.
Apache Storm Trident Topologies
To create Trident Topology, we can use the “TridentTopology” class. Data in Trident is received by the input stream of the spout, after that Trident performs operations such as grouping, filter, and aggregation on the stream of data.
The following syntax will create a Trident topology.
TridentTopology trintopology = new TridentTopology();
Apache Storm Trident Spouts
By using Trident spouts data can be streamed from the source. Trident spouts are much alike to Storm spouts but compared to Storm, Trident provides additional APIs for refined spouts. Trident spouts have provided a unique identifier for the stream that is used by Trident to store the detail of the spout in zookeeper.
The following is the list of Trident Spouts.
- ITridentSpout: This Trident Spout API is used to support transitional or impervious transactional.
- IOpaquePartitionedTridentSpout: This Trident Spout API is used to read data from the partitioned data source. The type it supports is transitional.
- IPartitionedTridentSpout: This Trident Spout API reads data from a partitioned data source such as Kafka servers.
- IBatchSpout: This Trident Spout API is non-transactional.
Apache Storm Trident Tuples
This Trident tuple is the named list of values and it is also a data model. It is build up by performing a sequence of actions. The basic unit of data that can be processed by Trident topology is “TridentTuple “.
Apache Storm Trident Operations
By using “Trident operations” input streams of Trident tuples are processed. Trident API provides a rich set of inbuilt operators to perform different types of streaming operations.
The following is the list of most used operators.
- Filter Operation
- Aggregation Operation
- Function Operation
- Grouping Operation
- Merging and Joining Operation
Filter Operation
The task of the Filter operation is input verification. When a Trident receives input tuples fields and returns the value true then the tuple is stored in the output stream and if the false value is returned then tuples will be removed from the stream.
Aggregation Operation
The task of the Aggregation operation is to implement Aggregation on the input stream. Aggregation can be performed on partition and batch as well.
Trident provides three types of Aggregation operations.
- Partition Aggregate Operation: It is used to perform Aggregation on every partition.
- Persistent Aggregate Operation: It is used to perform Aggregation on all Tridenttuple.
- Aggregate Operation: It is used to perform Aggregation on every batch of Tridenttuple.
Function Operation
The task of Function operation is to perform a basic operation for a single Trident tuple. Function operation takes trident tuple fields as input and produces new trident tuple fields.
Grouping Operation
Grouping Operation performs repartition of the stream by using partitionBy. After this in every partition, it performs a grouping of tuples together where group fields are equivalent.
Merging and Joining Operation
Merging and Joining operations are used to perform the merge and join operation. Merger operation is used to merge one or more streams whereas join is used to join one or more streams. The Join operation mechanism for batch level only.
Apache Storm Trident State Maintenance
Trident has a mechanism to maintain the state information that is stored in topology. This information is required when there is a failure in tuple processing in that case failed tuple would be retriggered. If there is a failure before performing an update to state then retriggering tuple can make it constant but if the tuple is failed after updating the state then retriggering will increase the count in the database and the state will be unstable.
To process messages only once, we need to check the following points.
- Small Batch processing for tuples.
- Every batch should have a unique ID so, in case of retried, the same ID is assigned.
Apache Storm Trident Distributed RPC
Trident Distributed RPC is used to take a request from the client, send it further to topology for processing, and receive the result from topology and send it back to the client. Distributed RPC is similar to a regular RPC call. Using Distributed RPC, computation is parallelized for forceful functions.
The following figure shows the distributed RPC workflow.
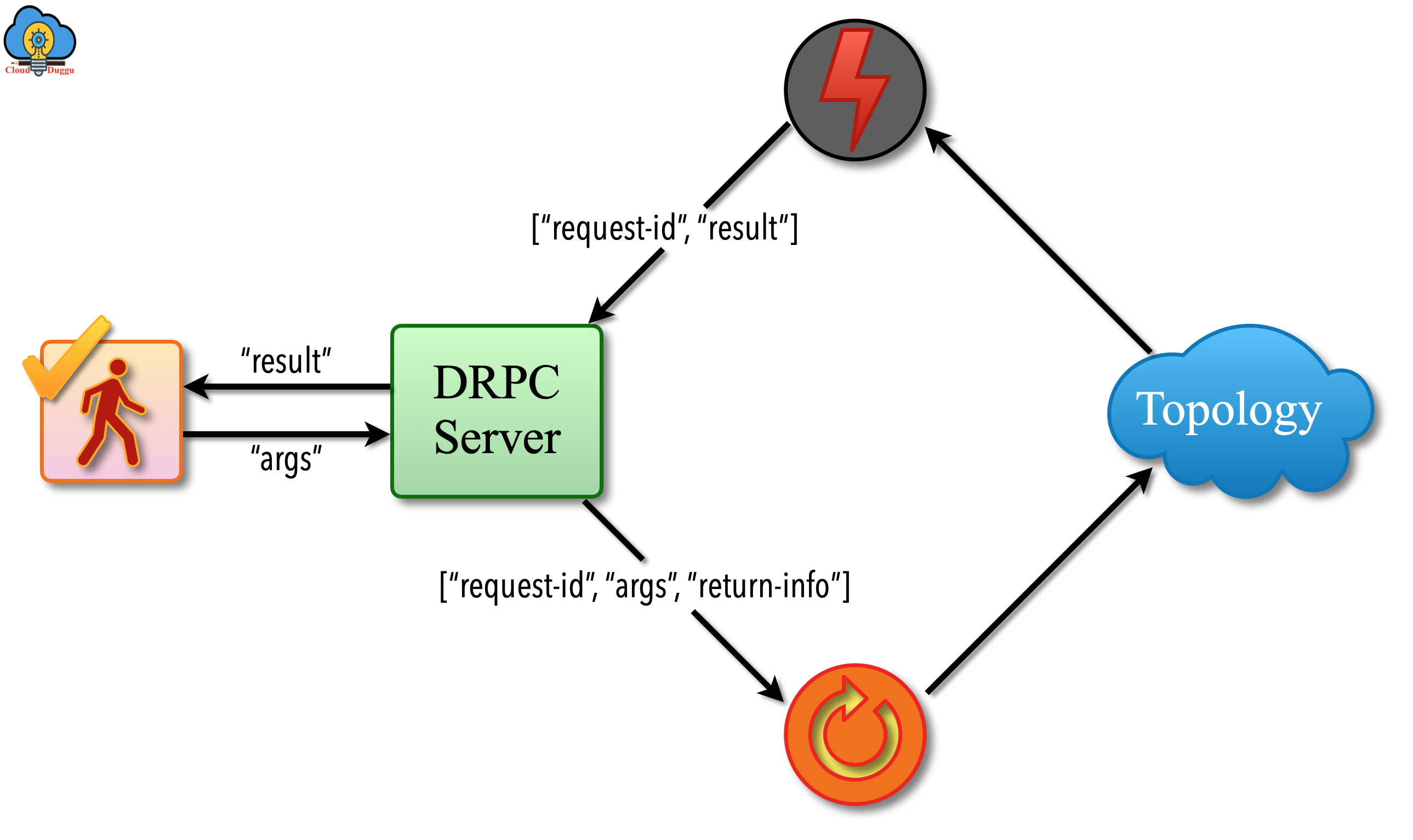
- A client will make a call to the DRPC server by sending the function and its argument. DRPC server will tag each function with a unique id.
- The topology will receive the request send by the DRPC server using DRPCSpout.
- The topology will process the request and by using Bolt (ReturnResults), it will return results.
- The DRPC server will check the unique id and match with the request of the client and send the result to the particular client.