Apache Storm Topologies are similar to the “MapReduce” job of Hadoop. Storm Topologies is the graphical representation of computation. It is the actual component of Apache Storm to perform real-time computation. In the Storm cluster, every node is linked together and processes data.
Now we will see how tuples are passed in between components of Storm Topology.
Stream Grouping
Stream Grouping is used to define the data exchange between different components of Apache Storm topology. It shows how multiples streams are used by bolts. It is set during the defining of topology.
The following picture displays the execution of the topology task.
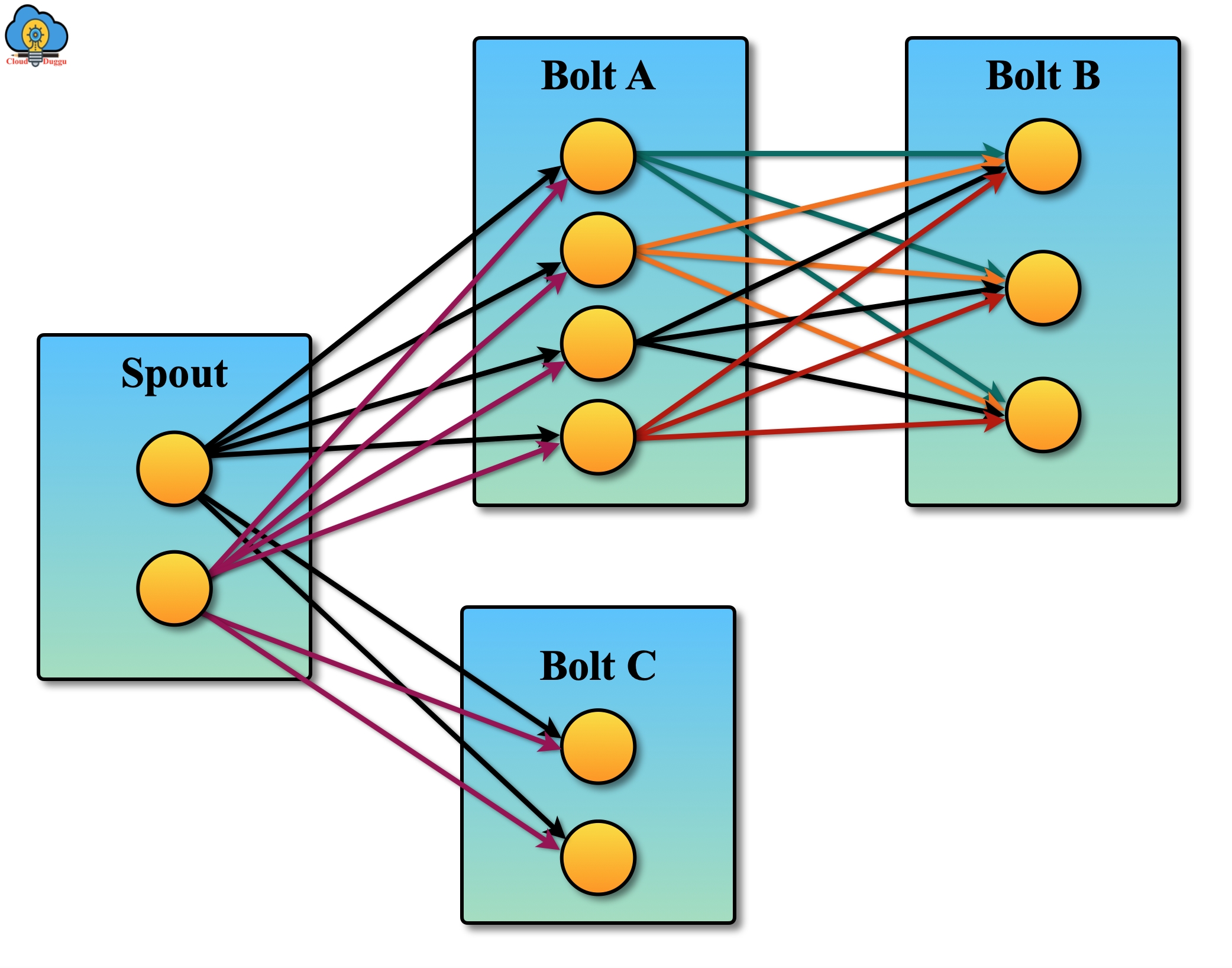
The following are different kinds of Stream Grouping.
1. Shuffle Grouping
Shuffle Grouping is a very common grouping that takes one input and sends a tuple produced by the source to an arbitrarily selected bolt. It is very helpful in performing atomic operations.
2. Fields Grouping
Fields Grouping helps to control the flow of tuples based on the fields of the tuple. It is used to send the set of value for a grouping of files will always go to a similar bolt.
3. All Grouping
All Grouping uses a single copy of every tuple to send to receiving bolts. This form of grouping is used to send signals to bolts. The example of All Grouping is when a refresh cache signal is sent to all bolts of the cluster to refresh cache memory.
4. Custom Grouping
A user can create customized grouping by implementing type.storm.grouping.CustomStreamGrouping interface. By using Custom Grouping a user can decide the bolt that will receive a tuple.
5. Direct Grouping
In this type of Grouping, the decision of receiving bolt is in the handle of the source.