What is Apache Storm Architecture?
Apache Storm is an open-source, distributed, fault-tolerant, distributed computing system. Using Apache Storm allows you to run large-scale applications on large clusters of servers. With Storm, you can run Apache Hadoop on a single machine or across multiple machines, and scale up your application without any change to your application logic. Because of the distributed nature of the system, it can scale to a nearly infinite scale in terms of the number of nodes. You can use Apache Storm for processing streaming streams of data from your Hadoop clusters in real-time or process large amounts of batch jobs on the cluster.
Apache Storm tools can give you highly reliable processing of large data, with an ability to quickly replay data if it wasn't processed correctly the first time around. Using Apache Storm also guarantees guaranteed processing of unprocessed data and the ability to easily run batch processing and schedulers across multiple machines. Besides, using Storm on Hadoop makes it easy to develop highly performant applications in the large. Using Apache Storm with Hadoop allows you to build highly optimized applications and run them on large clusters. Using Apache Storm, you can create a virtual cluster that contains a large number of machines and then easily use Apache's Apache Mesos framework to run highly optimized applications on those virtual machines.
Apache Storm can be deployed on a cluster of nodes. It has three components namely Nimbus Node, Supervisor Node, and Zookeeper Cluster.
The following picture shows the architecture of Apache Storm.
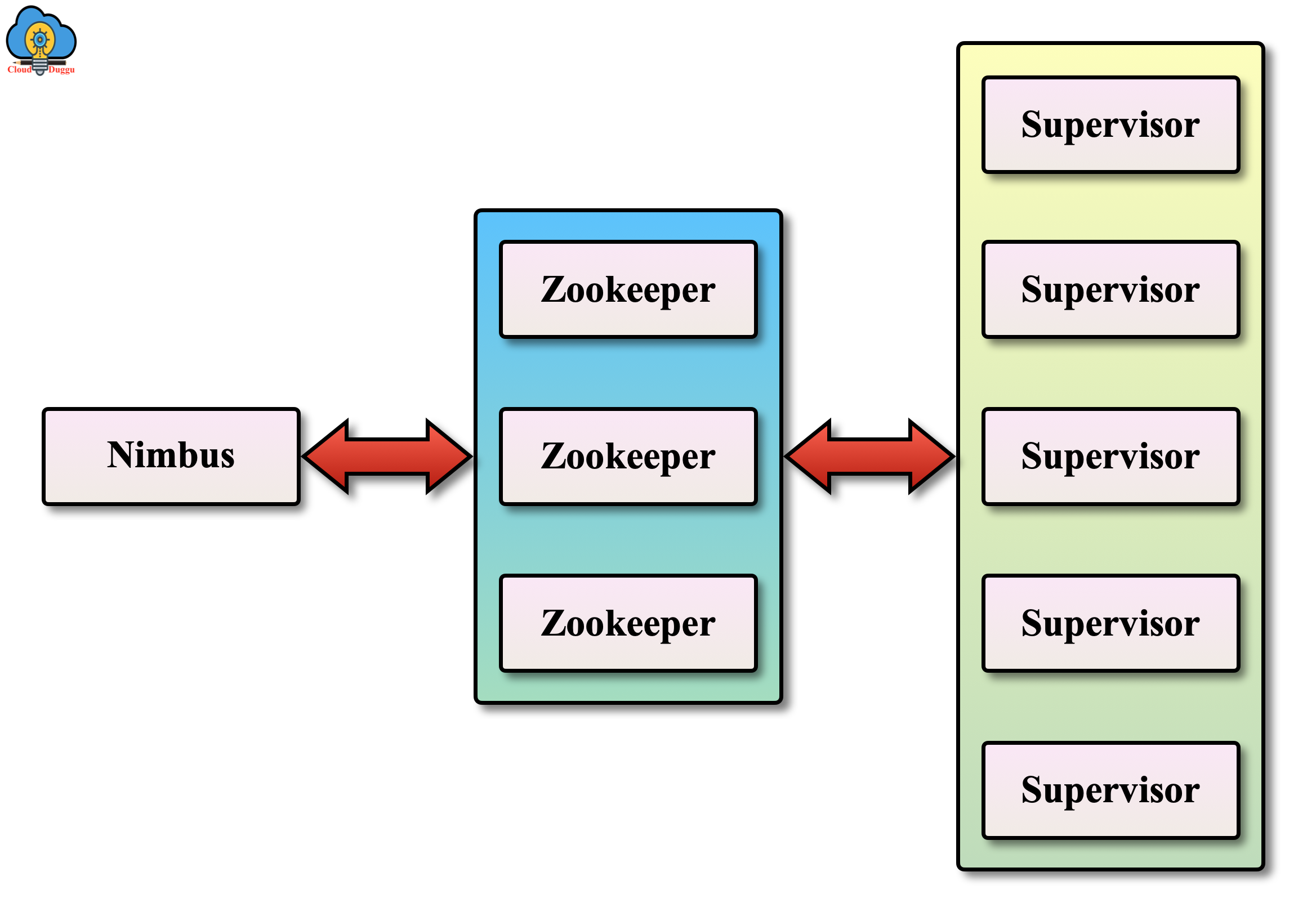
Let us see the components of Apache Storm in detail.
1. Apache Storm Nimbus Node
Storm Nimbus node acts as a master node of Hadoop. Its responsibility is to distribute the application code across multiple worker nodes. Nimbus node kept assigning the task to worker nodes and monitors those tasks. If the Nimbus node detects any task failure then it restarts those failed tasks. Nimbus uses Zookeeper to store all its data and in a cluster of nodes, there is one nimbus node. If there is a failure in the Nimbus node then it will not impact already running the task on worker nodes.
2. Zookeeper
Zookeeper is used to maintain the states associated with the cluster and different types of tasks submitted to Storm. Its main task is to maintain the communication between Nimbus and the Supervisor nodes. Zookeeper maintains all data associated with storm hence in case if Nimbus node or Supervisor nodes are terminated then it will not affect the cluster.
3. Apache Storm Supervisor Nodes
Storm Supervisor nodes act as slave nodes of Hadoop. These nodes are worker nodes of Storm. Supervisor nodes are responsible to create, start, and stop the worker process on nodes. In case of failure, it is started to avoid any issue. One Supervisor node handles multiple worker processing for that node.
Apache Storm Data Model
In the Apache Storm data model, a tuple is a basic unit of data. A tuple has a predefined list of fields. Each field can be a char, integer, long, char, float, Boolean, and so on. To define a user tuple, Storm provides API to define customize data type.
Apache Storm Topology
Storm topology is used to perform real-time computation. It represents a graph of computation. A topology can be created by a user and deploy on a Storm cluster to process data. Once a topology is deployed in the Storm cluster then each node performs some action and passes the result to another node for further action.
The following figure shows the Storm topology.
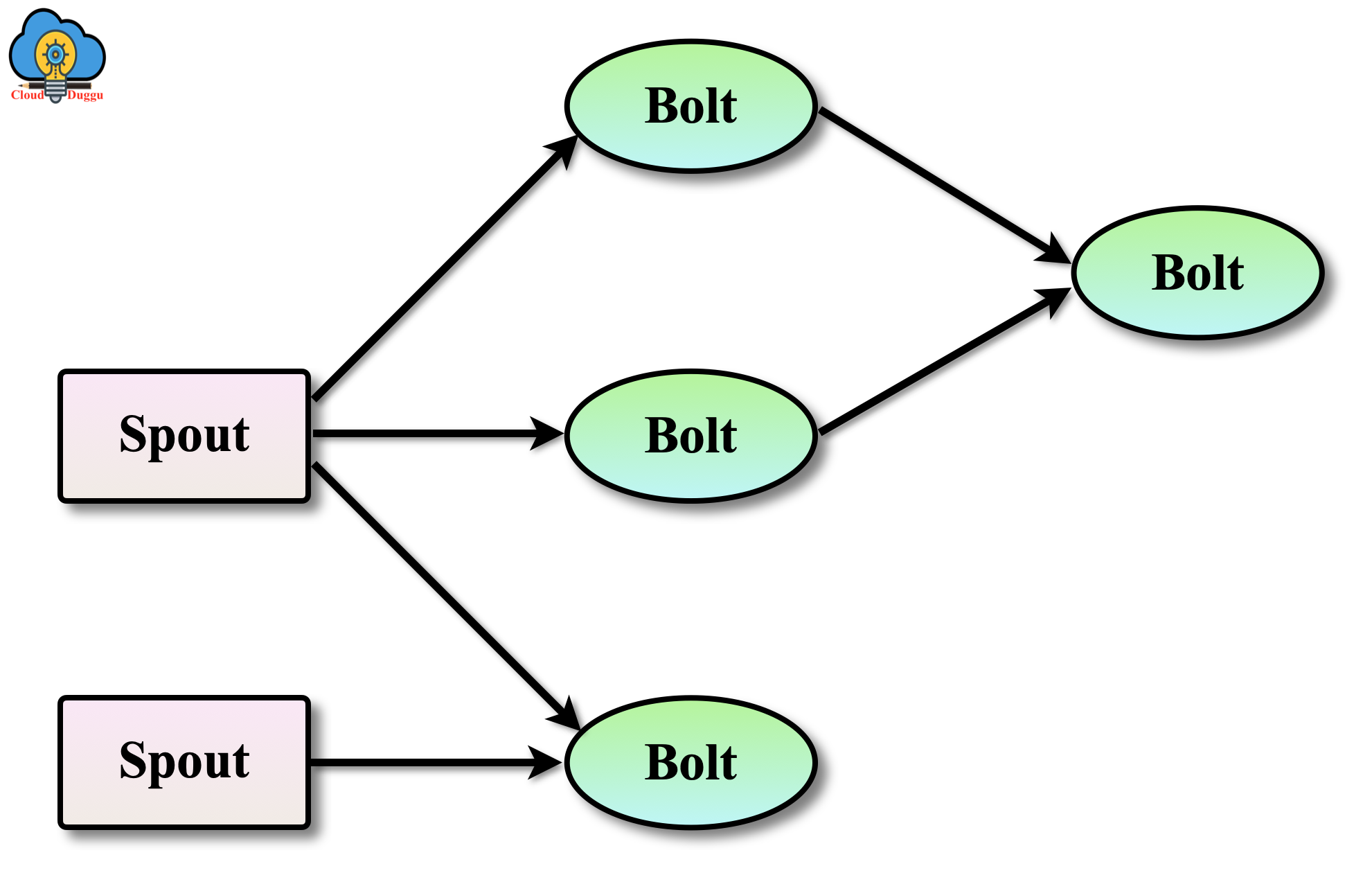
Let us see each component of Storm topology.
1. Spout
The spout is used to read or listen to data from external sources and release in Storm. It is a source of the tuple. The spout can be defined by using the “backtype.storm.spout.ISpout” interface.
The following are some important methods of Spout.
1.1 nextTuple()
This method is used to define the login to read data from the external source and pass it further. Storm calls this function to find the next tuple from the input source.
1.2 ack(Object messageId)
This method is used when the tuple is processed by topology. Once processing is completed, a cleanup activity is started to make sure that the same tuple message ID should not be processed.
1.3 fail(Object messageId)
This method is used when the tuple is not processed successfully. In that case, a message is again passed in nextTuple() for reprocessing.
1.4 open()
This method is used to define the login to connect to external sources to receive input data. Storm calls this method only once. Once a connection is established with external sources then the nextTuple method keeps getting data and release it further.
2. Bolt
Bolt is used to performing data transformation of tuples in Storm. To perform the complex transformation, multiple Bolts coordinate with each other to fulfill the requirement.
The following are some important methods of Bolt.
2.1 execute(Tuple input)
This method is used to process each tuple and generate output in the form of more tuples or stores in the database.