Apache Solr Architecture is based on the client-server model and we can run it as single-core or multi-core. The Architecture of Solr consists of four logical layers. Each logical layer perform different operations such as the storage layer manages the indexes and the metadata management, the container layer represent the J2EE layers that run the Solr instance, the Solr application layer represents the Solr engine that will run on over Solr instance, the interaction layer shows the communication of client/browser and the Solr server.
The following figure shows the logical layers of Apache Solr architecture.
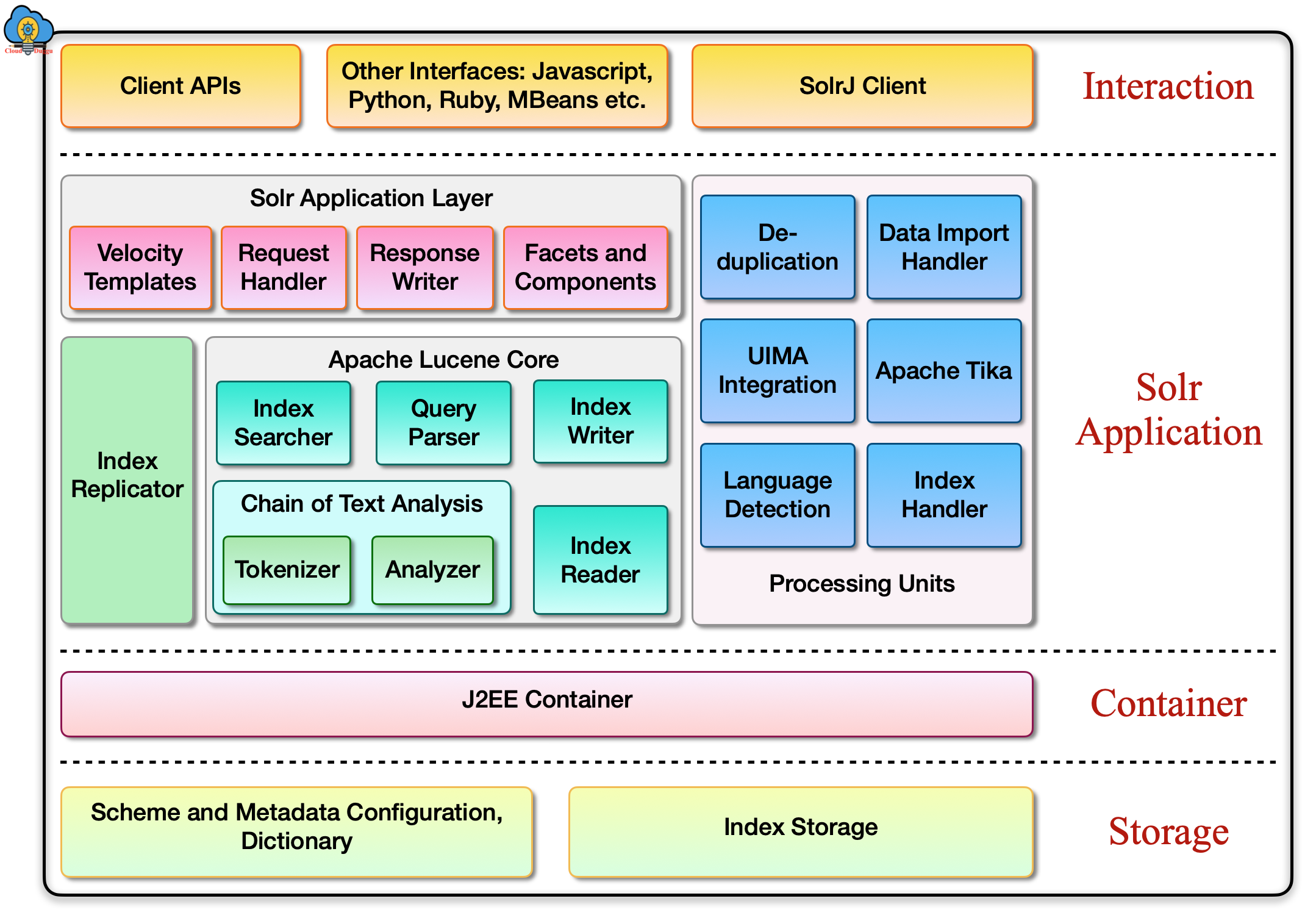
Let us see the components of Apache Solr in detail.
1. Solr Interaction Layer
This layer is the interaction layer of Apache Solr, Using this layer applications can connect with Solr and perform the different types of operations on the indexes. The application can use the client APIs, other interfaces such as Javascripts, Ruby, Python, and SolrJ client to interact with the Apache Solr server.
2. Solr Application Layer
Basically, Apache Solr supports two types of function namely the indexes and the search. In the first place, the loading of data is done in Apache Solr from the application, and depending upon the data there are handlers to handle the type of data. The data goes through different stages.
Let us see each step using the below pointers.
- Once the data loading is completed the cleanup process called update processor chain is started in which the de-duplication phase removes the duplication records and prevents them from appearing in the index.
- The Update handle performs the document level operations and produces many documents from one document after this the data is transferred.
- Solar is capable to run in a master and slave fashion in that the index replicator replicates the indexes across the nodes to maintain the high availability.
- Apache Lucene core is responsible to provides the core functions such as searching data, indexing, ranking matched, query processing, and so on.
- The index search of Apache Lucene core is responsible for return an ordered match of a search result.
- Query parser of Apache Lucene core is responsible for query parsing of a search string.
- The index writer of Apache Lucene core is responsible to create indexes. It also maintains those created indexes.
- The index reader of Apache Lucene core is responsible for granting required access to indexed which are stored in a storage medium such as a filesystem.
- The Tokenizers and filters play the role of analyzers in which a filter examine the fields and produce the token stream and Tokenizer uses these token stream and breaks into tokens.
The following figure represents the end-to-end process flow of a search request that is generated from a client.
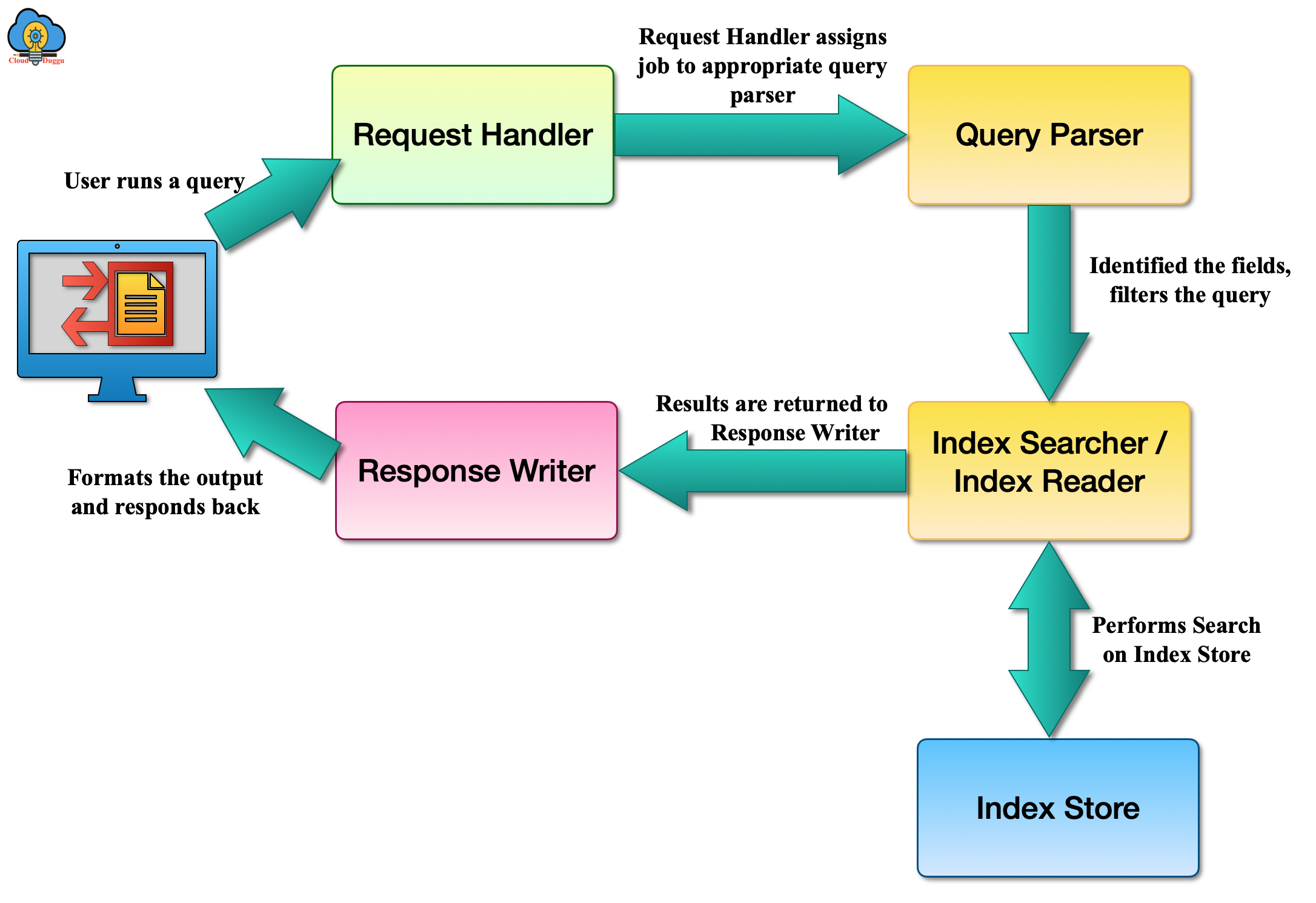
3. Solr Container Layer
Apache Solr application is based on the J2EE (Java 2 Enterprise Edition) standard that uses the Lucene libraries for index generation. Solr instance runs on the top of the J2EE container.
4. Solr Storage Layer
The storage layer of Apache Solr architecture is used to store the metadata and the index information on the filesystem or we can configure the external data store as well to store this information such as database, big data storage system. By default Solr comes with the HTTP and Jetty servlet servers. We can check these configurations in the "/conf" directory of Solr home.