What is Apache Hive?
Apache Hive is a Data warehouse solution for Big data that is developed on top of the Apache Hadoop framework. Hive provides support for reading, writing, and managing large data set that is stored on Hadoop HDFS(Hadoop File System). Hive has a SQL-like language called HiveQL that is used by developers to perform DML and DDL operations. HiveQL provides similar functionality that SQL provides in a relational database system and it can run multiple computing frameworks such as Tez, Spark, and MapReduce. Apache Hive has three main data structures which are, tables, buckets, and partitions. Hive stores its metadata on Apache Derby or other relational databases such as SQL server and so on.
Apache Hive History
The invention of Apache Hive was done by Joydeep Sen Sarma and Ashish Thusoo during their tenure at Facebook as their engineering team was having a high number of SQL skilled staff and both realized that to make the best use of Hadoop they will have to write quite complex MapReduce jobs then they come up with this plan to create a tool which can support a SQL language as well as at the background the programming ability to work on Hadoop framework. This wey Hive was born.
Facebook manages the Hive-Hadoop cluster which stores more than 3PB of data and on daily basis, it loads around 16 TB of data. Multiple companies such as IBM, Amazon, Yahoo, Netflix are using hive and developing it continually.
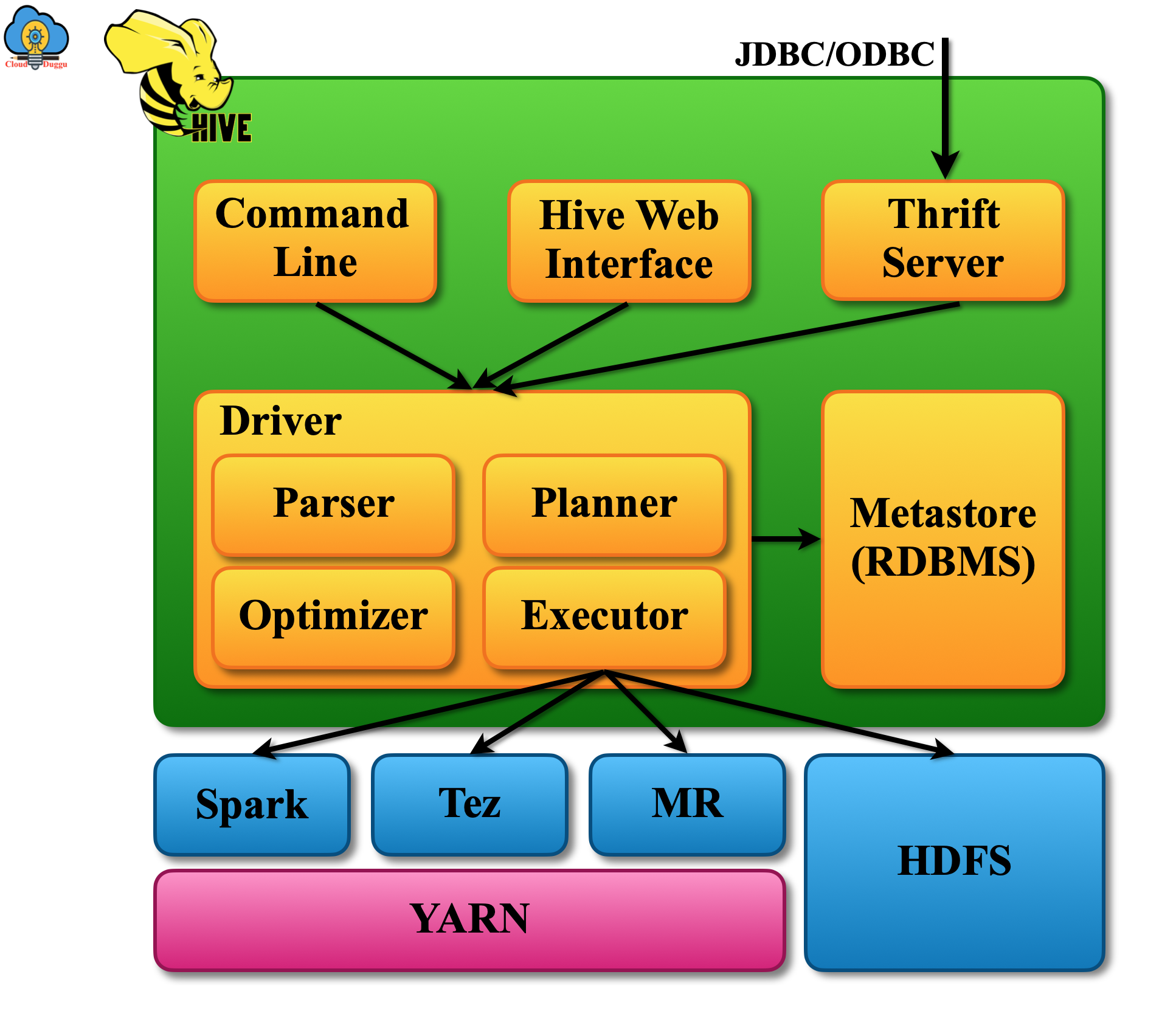
Apache Hive Architecture
The following are the major components of Apache Hive Architecture.
- Metastore: This component of Apache Hive is used to store the metadata of objects such as their location, schema details also contain the detail about the cluster partition to keep a track of dataset progress.
- Driver: The task of the Apache Hive driver is to create a session and start executing the statements that are received from the end-user also monitor the life cycle of execution. Hive Drive also stores the metadata of HiveQL while executing the HiveQL queries.
- Compiler: The task of the Apache Hive compiler is to compile the HiveQL query and convert it into an execution plan so that it can be executed by Hadoop MapReduce. Internally the query is converted into an AST(abstract syntax tree) and post that into DAG. Now MapReduce follows the DAG stages to execute the request.
- Optimizer: The Apache Hive Optimizer is used to perform the optimization so that an optimized DAG is generated. The optimization technique could be merging multiple joins into a single join to produce the best performance.
- Executor: Apache Hive Executor starts when the task of compilation and optimization is completed. The executor works with the job tracker to run a task on a Hadoop cluster. It also makes sure that the dependent job also executes if it in the pipeline.
- Thrift Server and CLI, UI: The task of the Apache Hive Thrift server is to provide an interaction of external clients with Hive using JDBC or ODBC protocol. Hive CLI is a command-line tool that provides an interface to run HiveQl queries.
Apache Hive Features
The following are some of the important features of Apache Hive.
- Hive's HQL and SQL have a similar syntax.
- Compared to MapReduce, Hive has an easy and tunned query model that requires minimal code.
- Hive can run on different computing frameworks.
- Using Hive, an Adhoc query can be fired on HDFS and HBase.
- Hive has matured JDBC and ODBC drivers which allows many applications to pull Hive data for seamless reporting.
- Using Hive SedDes, a user can read data that inconsistent.
- Hive can perform batch processing that makes it very reliable and ready for production implementation.
- The architecture of the Hive is designed in a way that it can easily perform user authentication, metadata management, and optimization of the query.
- The response time of Hive queries is better compared to others.
- Hive extends its functionality by supporting the user-managed functions, scripts, and so on.
- Have has a big community of practitioners and developers working on and using it.
- Hive provides features to access data using SQL like language(HQL) and perform data warehousing tasks such as extract/transform/load (ETL), reporting, and data analysis.
- Hive supports a variety of data formats such as text file, sequence file, RC file, Avro files, ORC files, parquet, and so on.
- Hive queries can be executed via Apache Tez, Apache Spark, or MapReduce.
Apache Hive Limitations
Apache Hive has the following list of limitations.
- OLTP Processing issues: Apache Hive is not intended for online transaction processing (OLTP).
- No Updates and Deletes: Hive does not support updates and deletes, however, it does support overwriting or apprehending data.
- Limited Subquery Support: Hive does not support subqueries.
- No Support for Materialized View: Hive does not support Materialized view.
- High Latency: The latency of Apache Hive queries is generally very high.