Using Bucketing, Apache Hive provides another technique to organize tables’ data in a more manageable way. Bucketing is a concept of breaking data down into ranges which are called buckets. Bucketing gives one more structure to the data so that it can be used for more efficient queries. The range for a bucket is determined by the hash value of one or more columns in the dataset. These columns are called `bucketing` or `clustered by` columns. When we load data in the Bucket table then it stores data in unique buckets as files. Hive uses a Hashing Algorithm to generate a number in the range of 1 to n buckets and store data in a particular bucket. Bucketing in Apache Hive is useful when we deal with large datasets that may need to be segregated into clusters for more efficient management and to be able to perform join queries with other large datasets.
Let us see Bucketing with the following example.
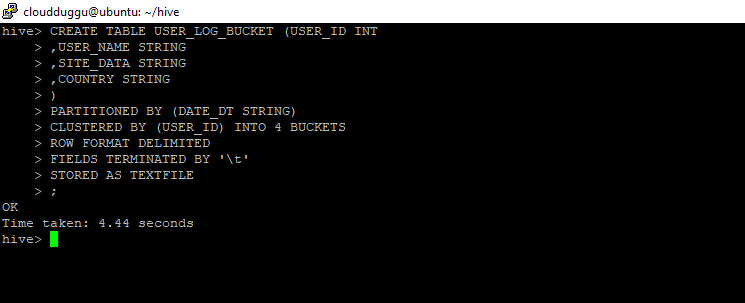
To perform this example, we will create a Bucket table “USER_LOG_BUCKET” which will have a Partition column DATE_DT and four Buckets. We have mentioned the Bucketing column in the CLUSTERED BY (USER_ID) clause in the create table statement. We will insert data in this table “USER_LOG_BUCKET” from “USER_LOG_DATA” (this table is created in the Partitioning section).
Create Table Statement:
CREATE TABLE USER_LOG_BUCKET (USER_ID INT
,USER_NAME STRING
,SITE_DATA STRING
,COUNTRY STRING
)
PARTITIONED BY (DATE_DT STRING)
CLUSTERED BY (USER_ID) INTO 4 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
;
Command Output:
Load Table Statement:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions.pernode=1000;
SET hive.enforce.bucketing=true;
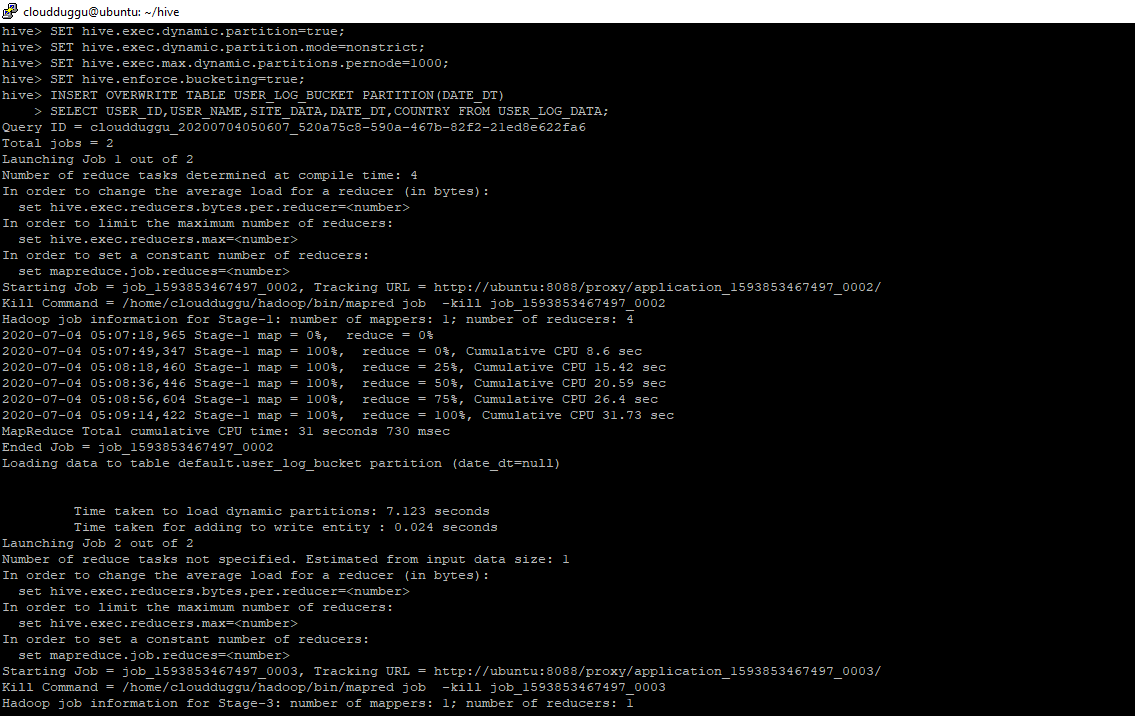
INSERT OVERWRITE TABLE USER_LOG_BUCKET PARTITION(DATE_DT)
SELECT USER_ID,USER_NAME,SITE_DATA,DATE_DT,COUNTRY FROM USER_LOG_DATA;
,USER_NAME STRING
,SITE_DATA STRING
,COUNTRY STRING
)
PARTITIONED BY (DATE_DT STRING)
CLUSTERED BY (USER_ID) INTO 4 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
;
Load Table Statement:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions.pernode=1000;
SET hive.enforce.bucketing=true;
INSERT OVERWRITE TABLE USER_LOG_BUCKET PARTITION(DATE_DT)
SELECT USER_ID,USER_NAME,SITE_DATA,DATE_DT,COUNTRY FROM USER_LOG_DATA;
SELECT USER_ID,USER_NAME,SITE_DATA,DATE_DT,COUNTRY FROM USER_LOG_DATA;
From the below Snapshot we can see 4 reducer tasks are started because we have defined 4 Buckets.
Command Output:
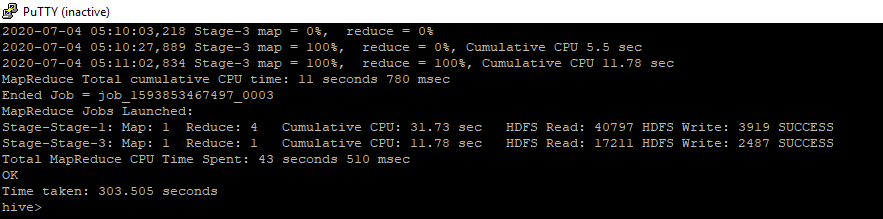
From the below snapshot we can see for the DATE_DT Partition column there are four buckets created.

Advantage of Apache Hive Bucketing
- Bucketing is a partitioning technique that helps to avoid data shuffling & sorting by applying some transformations.
- The basic idea about Bucketing is to partition users' data and store it in a sorted format based on the user's SQL and at the same time allows users to read data.
- Bucketing helps in performing a fast join operation.
- Using Bucketing, user's data are stored in each bucket in a sorted format.