What is Apache Spark SQL?
Apache Spark SQL is a Spark interface of SQL to process structured data. It provides support for SQL(structure query language) to process data present in Spark RDD and the data which is coming from external sources. Spark SQL defines the boundaries between Spark RDDs and relations tables. We can interact with Spark SQL using the SQL language and the API. Spark SQL supports both batch and streaming data.
The following actions can be performed using Apache Spark SQL.
- We can import the relation data from Parquet files into Hive tables.
- We can execute SQL queries on the imported data as well as on existing RDDs.
- We can write RDDs easily for Hive tables and Parquet files.
Libraries of Apache Spark SQL
Apache Spark SQL provides the following list of Libraries that is required for procedural and relational structure data processing.
1. Data Source API
The data source API (Application Programming Interface) is used for loading and storing structured data for processing.
- It can be accessed through the Hive context and SQL context.
- It follows lazily evaluation just like Apache Spark Transformations.
- It can process data in the range of Kilobytes to Petabytes.
- It supports multiple data formats such as Avro, CSV, Elastic Search, and Cassandra and different data sources like HDFS, HIVE Tables, MySQL, etc.
- Data Source API has built-in support for Hive, Avro, JSON, JDBC, Parquet, etc.
2. SQL Service
SQL service will allow the creating of DataFrame objects and processing of SQL queries.
3. Cost-based optimization
It supports cost-based optimization, columnar storage, and code generation which makes queries run faster.
Apache Spark SQL Features
Apache Spark SQL provides the following features.
1. Spark SQL Integration with Spark Programs
By using Spark SQL you can query structured data inside of Spark program. It supports DataFrame API that can be used by other programming languages such as Java, Scala, Python, and R.
2. JDBC and ODBC Connectivity
Spark SQL provides a connection through JDBC and ODBC.
3. Compatible with Hive
Spark SQL supports Hive’s data queries and UDFs
4. Support Multiple Data Sources
Apache SQL provides a way to access a variety of data sources such as Hive, Avro, Parquet, ORC, JSON, and JDBC.
5. Better Performance & Scalability
Apache Spark SQL uses a cost-based optimizer, columnar storage, and code generation to make queries fast. It can scale thousands of nodes and multi-hour queries using the Spark engine that provides fault tolerance. Spark SQL executes 100x then Hadoop.
Apache Spark SQL Practical Examples
We will see a few programs of Apache Spark SQL and perform some actions.
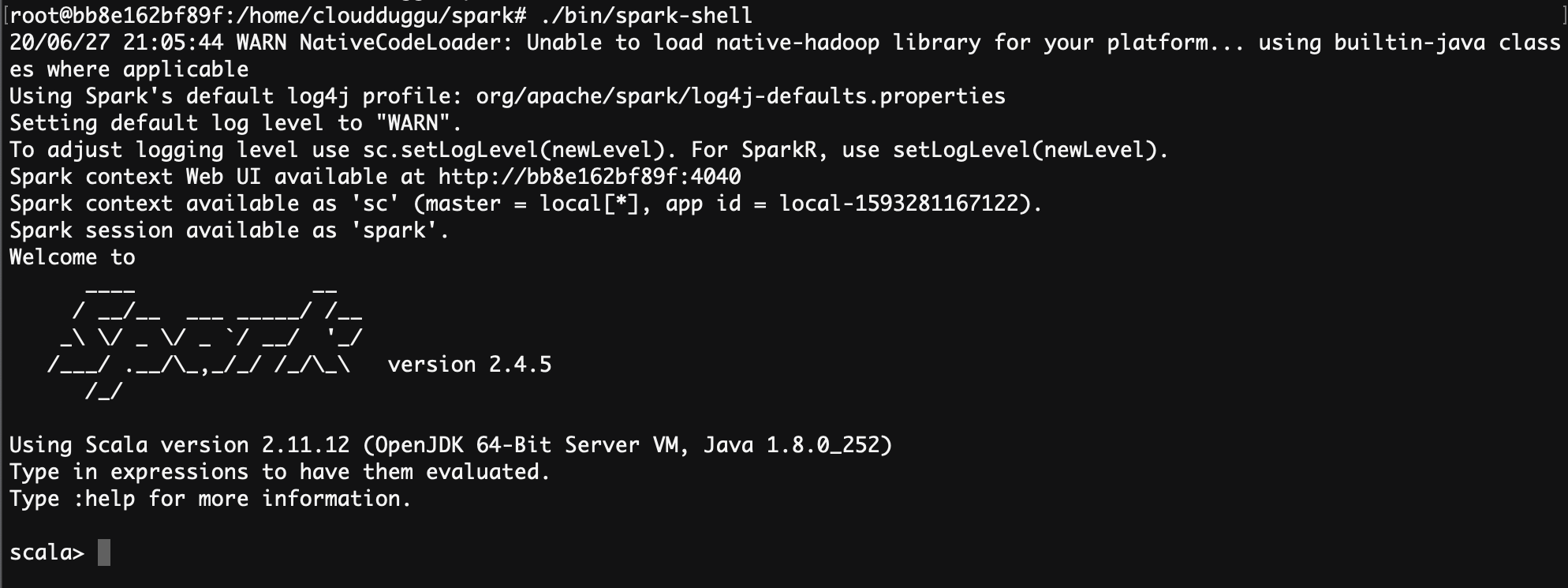
- Start the spark-shell by using the command (~/spark$bin/spark-shell) from SPARK_HOME (refer snapshot).
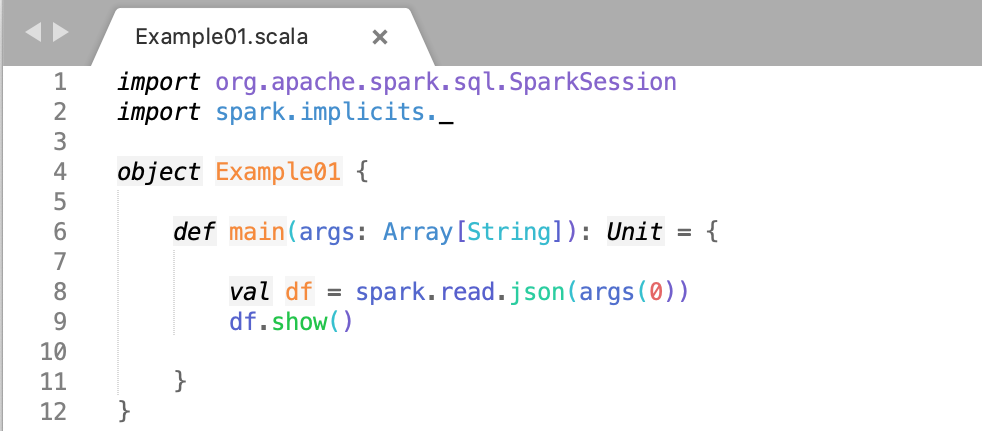
Example of DataFrame Creation Based On JSON File
Let us understand the code line by line and then we will execute it on the terminal.
- First, we will import a Spark Session into Apache Spark that is the entry point of all functionality in Spark.
- We will create a Spark Session ‘spark’ using the ‘builder()’ function.
- We will Import the Implicts class into our ‘spark’ Session.
- We now create a DataFrame ‘df’ and import data from the ’employees.json’ file.
- Display the result of using df. show command.
Click Here To Download "Example01.scala" Code File.
Click Here To Download "employees.json" File.
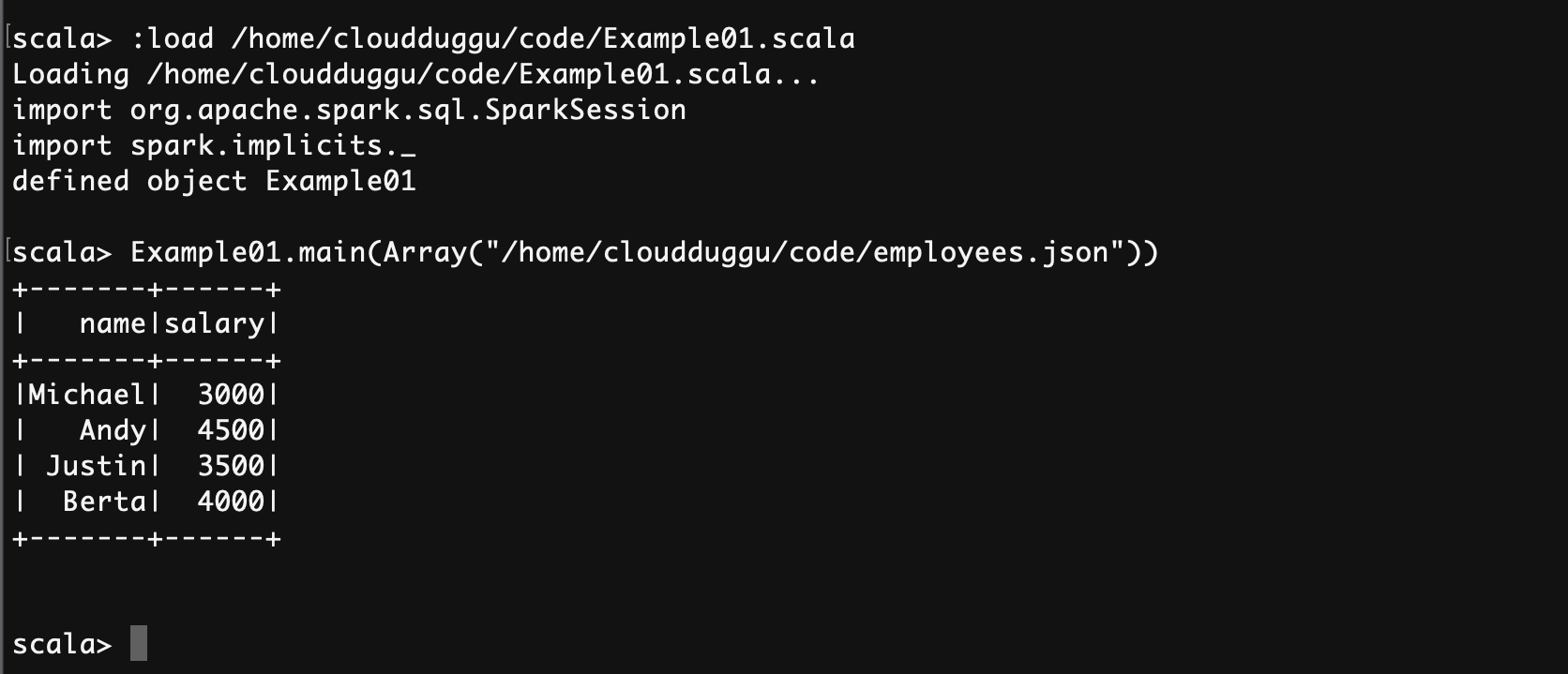
scala> :load /home/cloudduggu/code/Example01.scala
scala> Example01.main(Array("/home/cloudduggu/code/employees.json"))
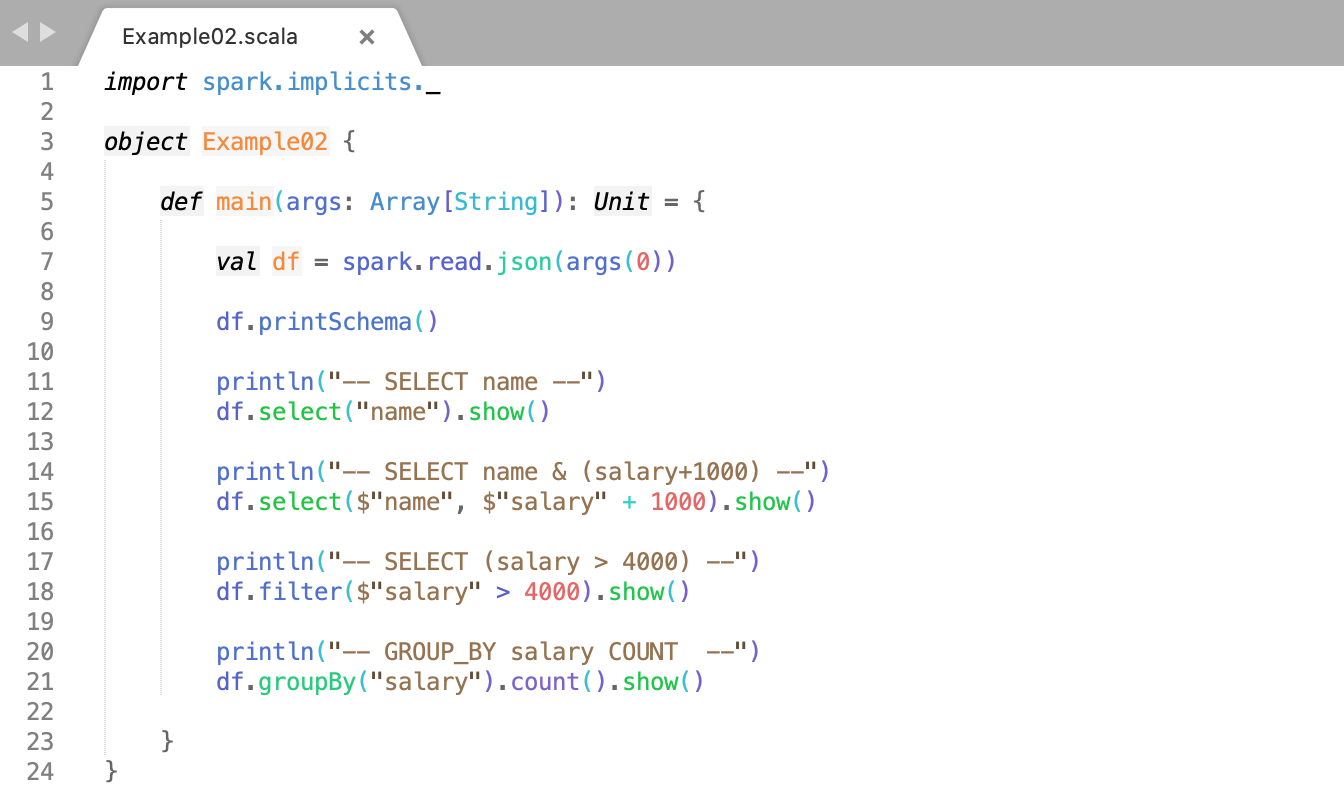
Example of Structured Data Processing Using Datasets
Let us understand the code line by line and then we will execute it on the terminal.
- First, we will Import the Implicts class into our ‘spark’ Session.
- Print the schema in a tree format.
- Select only the "name" column.
- Select everybody, but increment the salary by 1000.
- Select salary greater than 4000.
- Count people by salary.
Click Here To Download "Example02.scala" Code File.
Click Here To Download "employees.json" File.
scala> :load /home/cloudduggu/code/Example02.scala
scala> Example02.main(Array("/home/cloudduggu/code/employees.json"))
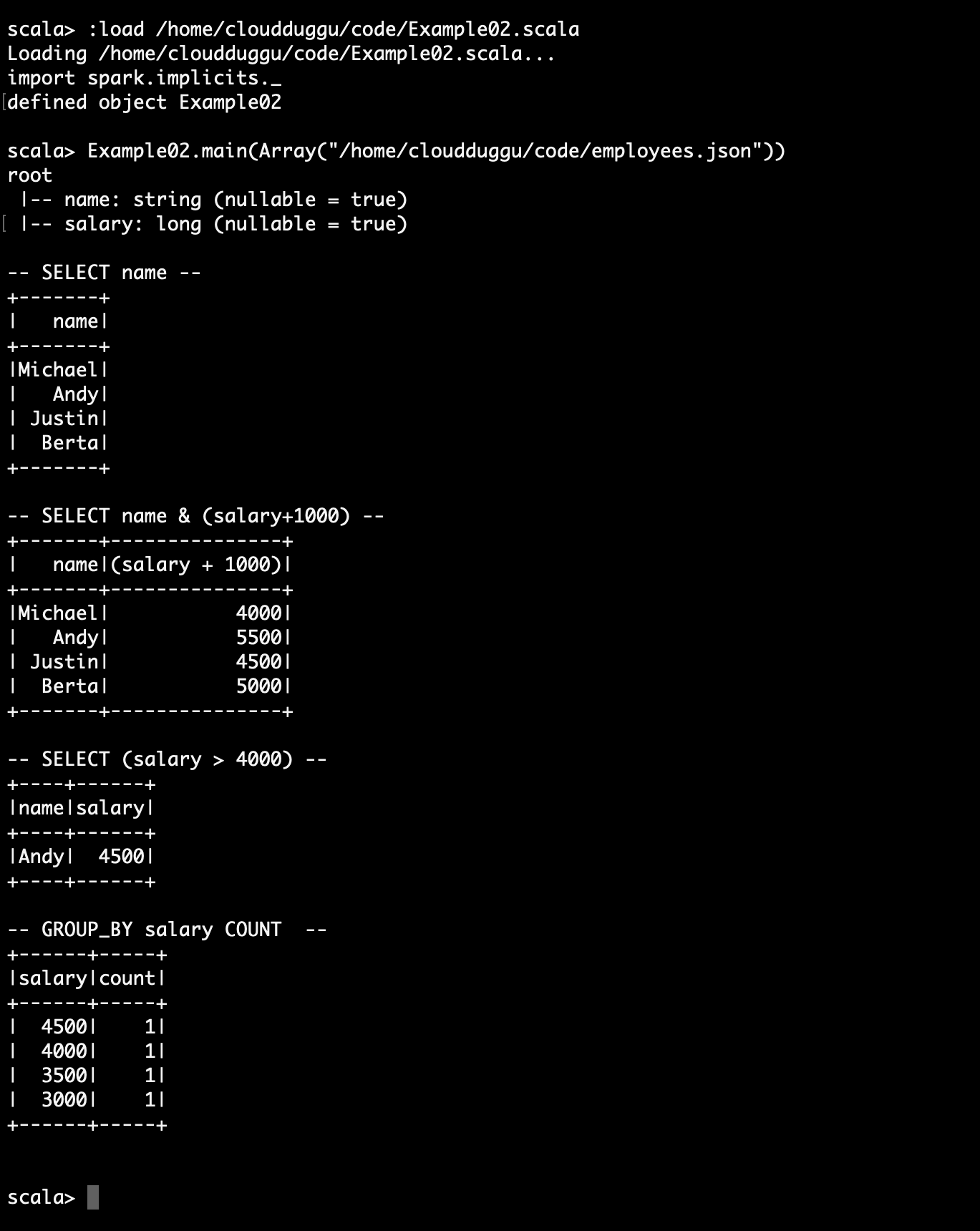
Example of SQL Query Running Programmatically
We will create a temporary view that is session-scoped and it will disappear once the session is terminated.
Let us understand the code line by line and then we will execute it on the terminal.
- Register the DataFrame as a SQL temporary view.
- Defining a DataFrame which will store all records of people table.
- Displaying value from sqlDF DataFrame.
Click Here To Download "Example03.scala" Code File.
Click Here To Download "people.json" File.
scala> :load /home/cloudduggu/code/Example03.scala
scala> Example03.main(Array("/home/cloudduggu/code/people.json"))
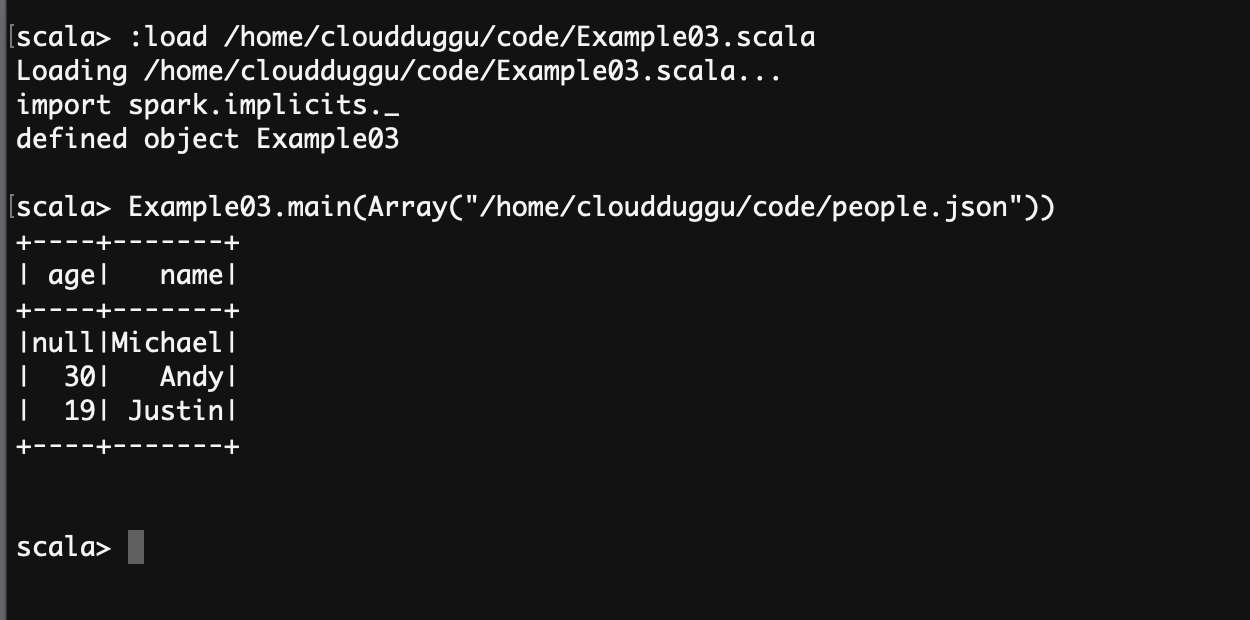
Example of Global Temporary View Creation
A Global temporary table is used in all sessions and it exists till the Spark application termination.
Let us understand the code line by line and then we will execute it on the terminal.
- Register the DataFrame as a global temporary view.
- A Global temporary view has a system maintained database called "global_temp".
- The global temporary view is cross-session.
Click Here To Download "Example04.scala" Code File.
Click Here To Download "people.json" File.
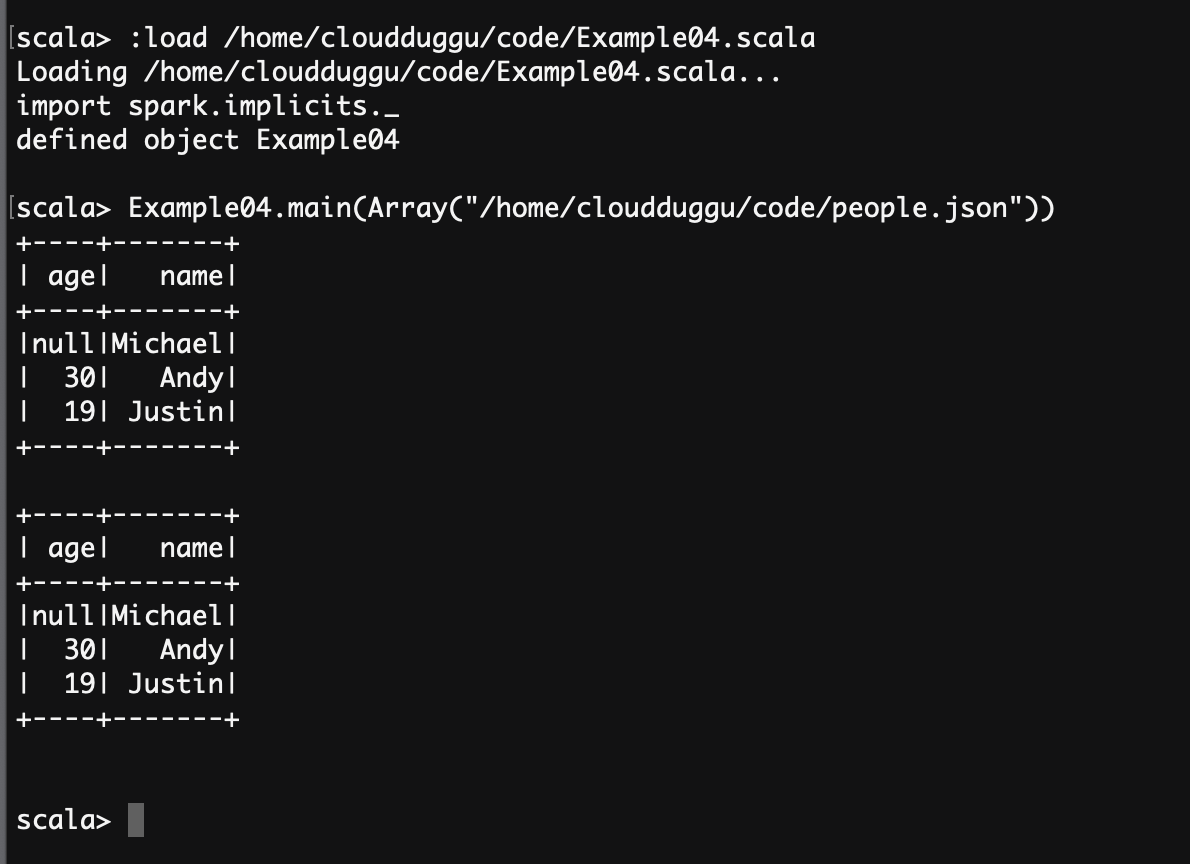
scala> :load /home/cloudduggu/code/Example04.scala
scala> Example04.main(Array("/home/cloudduggu/code/people.json"))
Example of DataSets Creation
Apache Spark datasets are the same as RDD which acts as a specialized Encoder to perform serialization of objects for further processing and transmitting on the network.
We will use the people.json file for DataSets creation. This file is located at /examples/src/main/resources/. Please check your SPARK_HOME directory.
In our case, the location of the file is /home/cloudduggu/spark/examples/src/main/resources/people.json
Let us understand the code line by line and then we will execute it on the terminal.
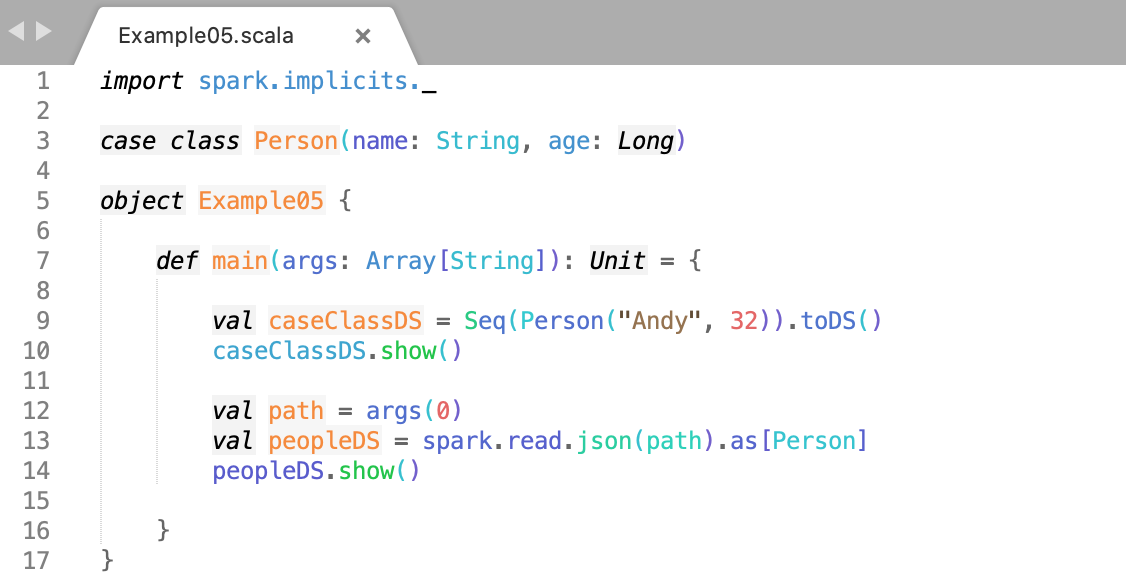
- Define a case class Person with name and age.
- Encoders are created for case classes.
- Display the caseClassDS result.
- Encoders are auto imported from the spark.implicits._ package and very common types.
- Returns: Array(2, 3, 4).
- By implementing a class a DataFrames is transformed into a Dataset.
- Mapping will be done by name.
- Display peopleDS result.
Click Here To Download "Example05.scala" Code File.
Click Here To Download "people.json" File.
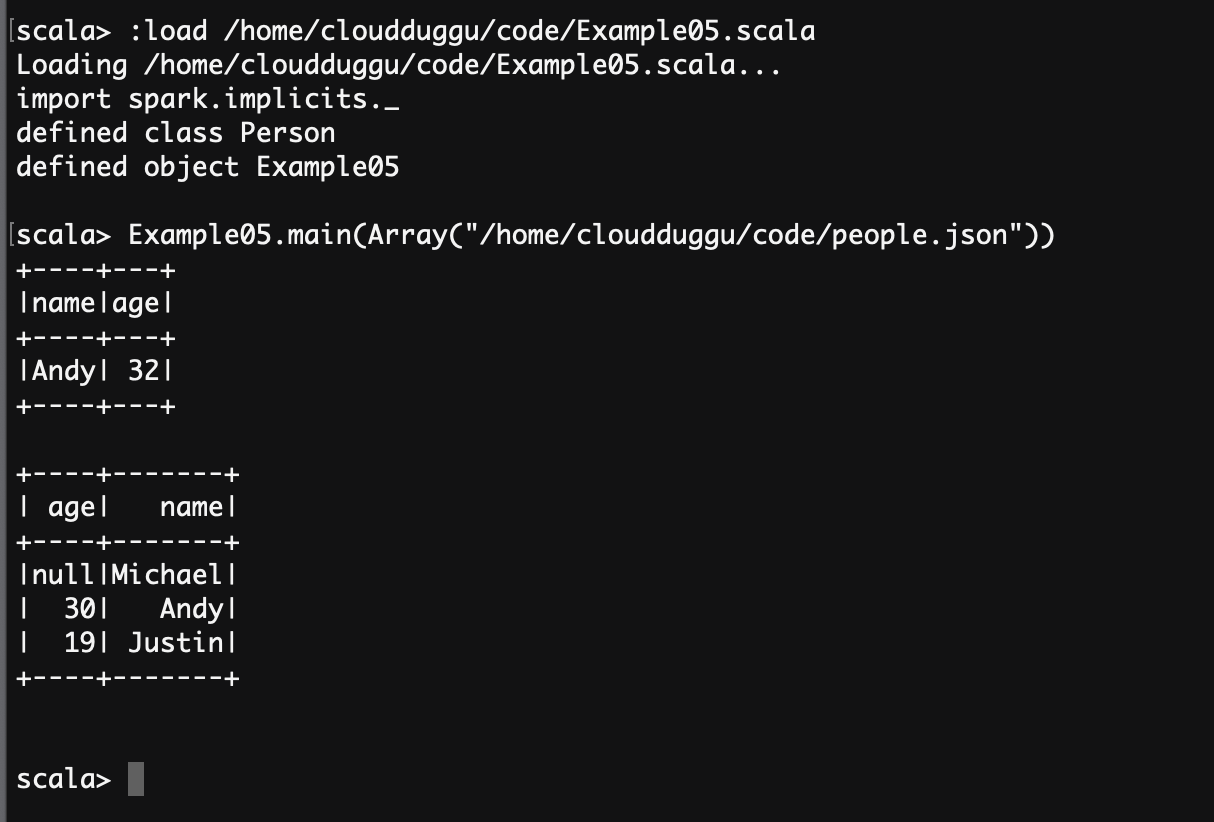
scala> :load /home/cloudduggu/code/Example05.scala
scala> Example05.main(Array("/home/cloudduggu/code/people.json"))
Example of Interoperating DataSets With RDD
There are the following two ways in which an Apache Spark SQL concerts existing RDDs into Datasets.
1. By Inferring the Schema Using Reflection
2. By Programmatically Specifying the Schema
1. By Inferring the Schema Using Reflection
In case the Datasets contains the case classes then Apache Spark SQL concerts it automatically into an RD. The case class represents the schema of a table.
2. By Programmatically Specifying the Schema
If a case class is not defined then it is created by the program.
There are the following three steps to do that.
- The first step is the creation of an RDD using the initial RDD.
- After the first step, use the StructType to create a schema that matches the structure of the row of RDDs that is created in step one.
- Use the Apache Spark createDataFrame method to apply the schema to the rows of RDD.
Let us see with example and understand code line by line and then we will execute it on the terminal.
- For implicit conversions from RDDs to DataFrames.
- Now use the text file and create an RDD of the person and reform it into the Dataframe.
- Register the DataFrame as a temporary view.
- Apache Spark provides the SQL methods to execute the SQL statements.
- The row results in columns are accessed using field index.
- The row results in columns are accessed using the field name.
- No pre-defined encoders for Dataset[Map[K,V]], define explicitly.
- row.getValuesMap[T] can fetch more than one column at a time in a Map function.
Click Here To Download "Example06.scala" Code File.
Click Here To Download "people.txt" File.
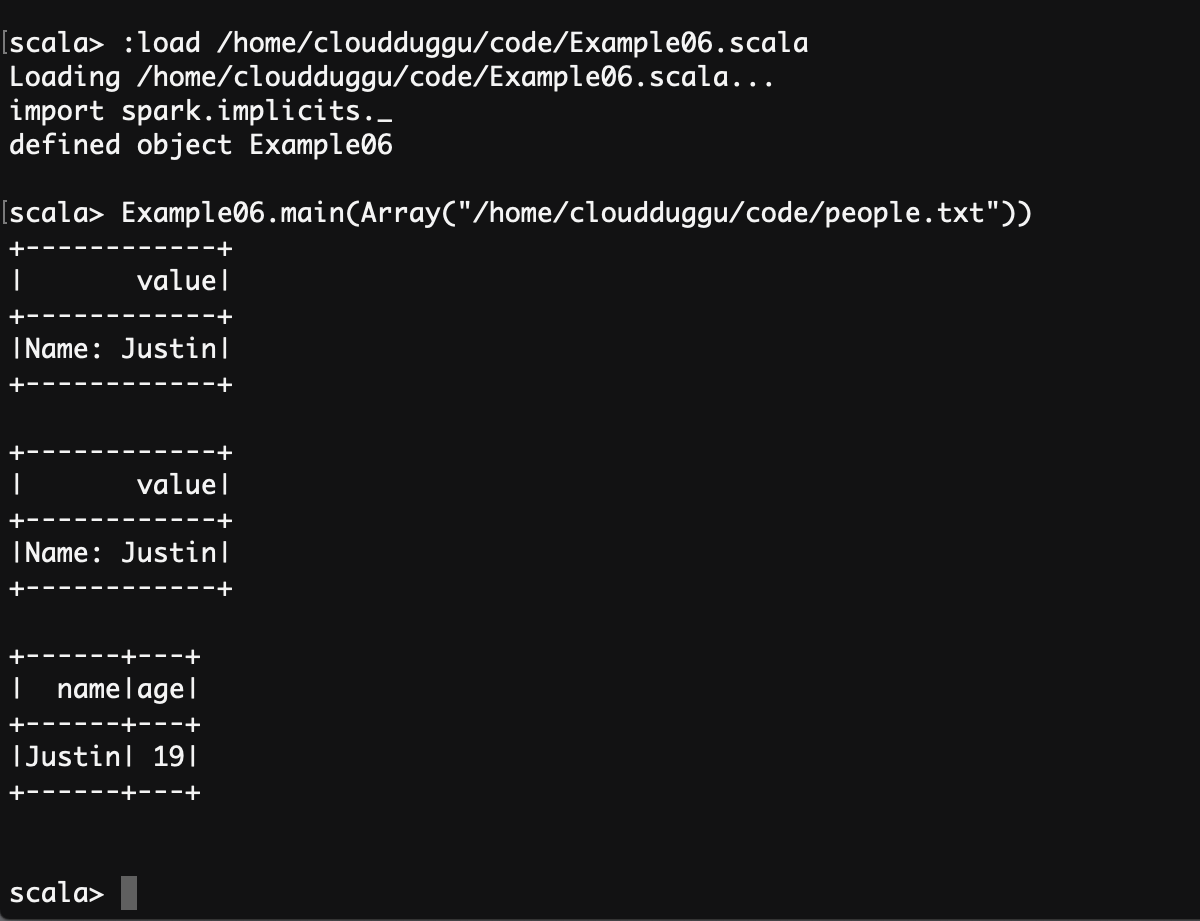
scala> :load /home/cloudduggu/code/Example06.scala
scala> Example06.main(Array("/home/cloudduggu/code/people.txt"))
Example of Aggregations
In Apache Spark SQL user extend the UserDefinedAggregateFunction abstract class to implement a custom untyped aggregate function and in DataFrames thers are built in functions which provide the common aggregations such as countDistinct(), count(), avg(), min(), max().
Untyped User-Defined Aggregate Functions
To define a custom untyped aggregate function, a user extends the abstract class "UserDefinedAggregateFunction"
We will use the employees.json file for this example which is located below the path of the SPARK_HOME directory.
examples/src/main/resources/employees.json
Let us see with example and understand code line by line and then we will execute it on the terminal.
- Import important Spark SQL package.
- Create a function with the name MyAverage by extending the UserDefinedAggregateFunction abstract class.
- Register the function (MyAverage) to access it.
- Create Datafram from employees.json file.
- Register a temp view.
- Display the result.
- Take the average salary from the employee table.
- Display the result.
Click Here To Download "Example07.scala" Code File.
Click Here To Download "employees.json" File.
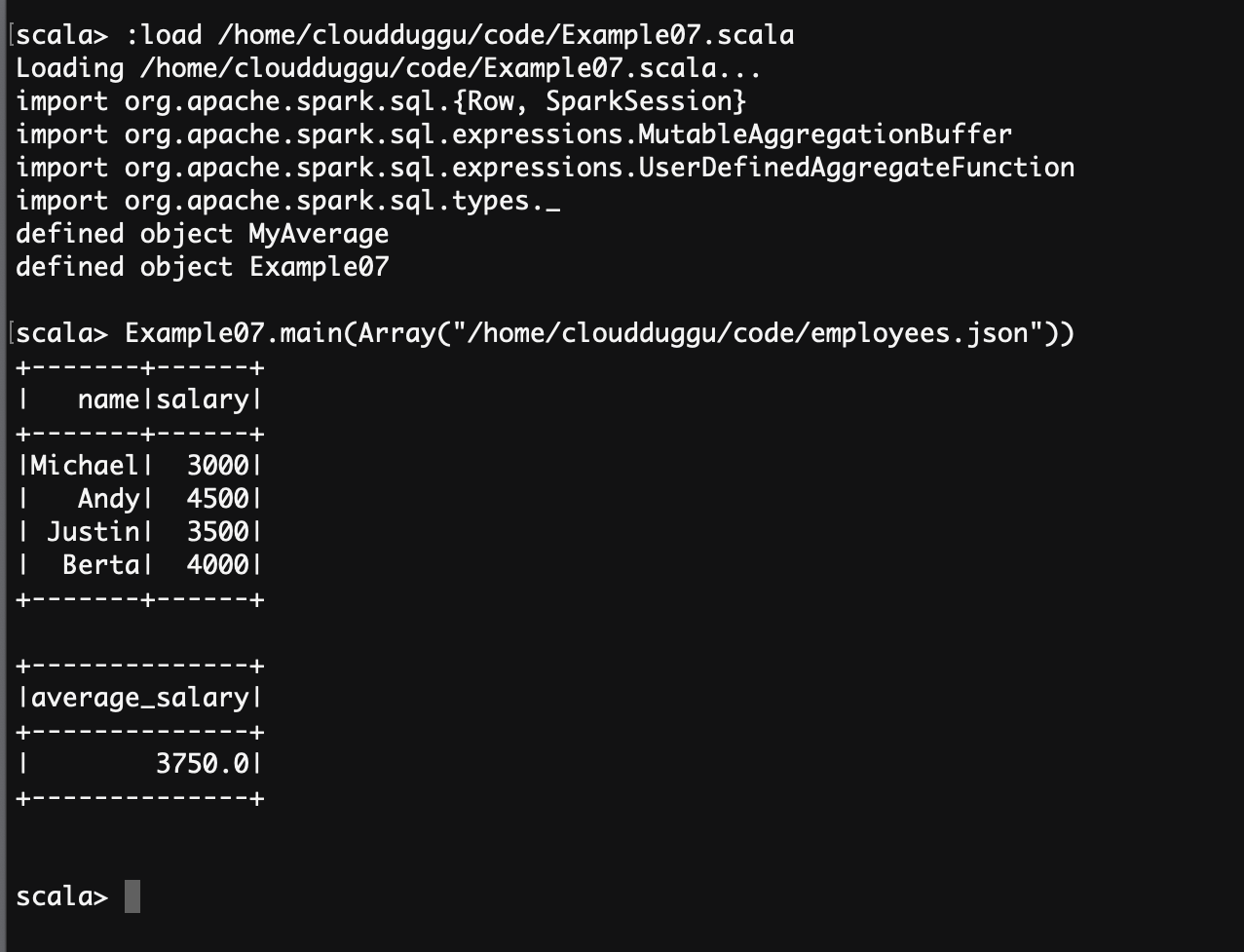
scala> :load /home/cloudduggu/code/Example07.scala
scala> Example07.main(Array("/home/cloudduggu/code/employees.json"))
Type-Safe User-Defined Aggregate Functions
The strongly typed Datasets of user-defined aggregations are turned around the Aggregator abstract class.
Let us see with example and understand code line by line and then we will execute it on the terminal.
- Import important Spark SQL package.
- Create a function with the name MyAverage by extending the Aggregator abstract class.
- Create Datafram from employees.json file.
- Display the result.
- Change the function to TypedColumn and assign a name.
- Take the average salary from the employee table.
- Display the result.
Click Here To Download "Example08.scala" Code File.
Click Here To Download "employees.json" File.
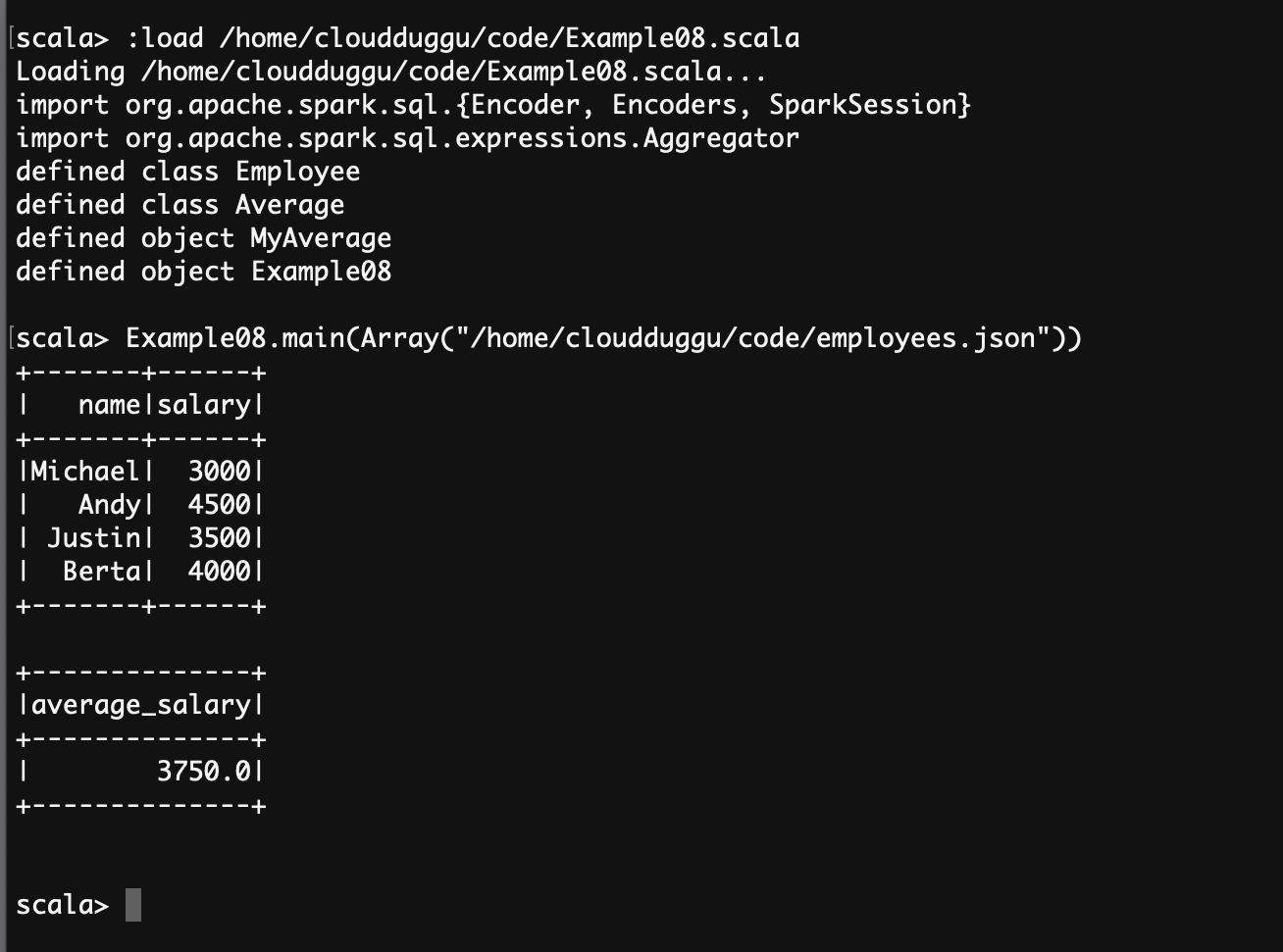
scala> :load /home/cloudduggu/code/Example08.scala
scala> Example08.main(Array("/home/cloudduggu/code/employees.json"))
Parquet Files
Apache Parquet is the type of columnar storage that is present in all Projects of Apache Hadoop. Apache Spark SQL provides the functionality to read and write the Parquet files. In the write operation on Parquet files, the columns are converted into nullable automatically.
Let us see with example and understand code line by line and then we will execute it on the terminal.
- spark.implicits._ provides the most basic type of Encoders.
- Create Datafram from the people.json file.
- Save the DataFrames as Parquet files.
- Read in the parquet file. Parquet files are self-describing so the schema is preserved. The result of loading a parquet file is also a DataFrame.
- Define a temporary view and utilize it in the SQL declarations.

Click Here To Download "Example09.scala" Code File.
Click Here To Download "people.json" File.
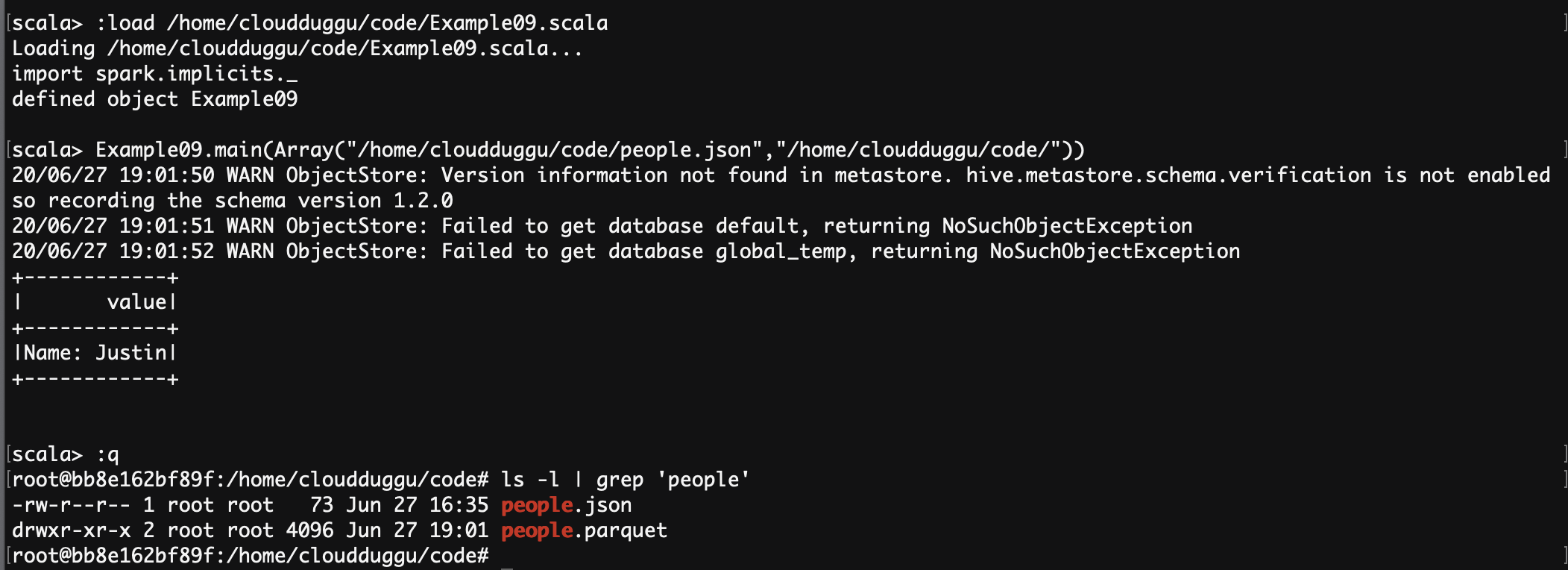
scala> :load /home/cloudduggu/code/Example09.scala
scala> Example09.main(Array("/home/cloudduggu/code/people.json","/home/cloudduggu/code/"))
Performance Tuning
Apache Spark SQL facilitates the performance tunning opportunities using caching data in memory.
Caching Data In Memory
Apache Spark SQL uses the function "spark.catalog.cacheTable("tableName")" and dataFrame.cache() to cache the data in memory in a columnar format after which Spark SQL only check the columns and tunes the compression to reduce memory utilization and Garbage collection pressure. We can use spark.catalog.uncacheTable("tableName") to delete data from memory.