What is Apache SparkR?
Apache SparkR is an R package that provides a light-weight frontend to use Apache Spark from R. R is a very popular tool that is used for statistics and data analysis. R development communities develop their rich and large collection of libraries. SparkR strings the benefits of Spark and R by allowing Spark jobs to be called from within R. SparkR provides a distributed data frame implementation that supports operations like selection, filtering, aggregation on large datasets which brings smaller aggregated data back into R for analysis. It also supports distributed machine learning using MLlib.
Apache SparkR DataFrames
DataFrame in SparkR is a distributed collection of data organized into named columns. It is theoretically equivalent to a table in a relational database or a data frame in R but with richer optimizations under the hood. DataFrames can be created from a wide range of sources such as: structured data files, tables in Hive, external databases, or existing local R data frames.
Apache SparkR Staring Up(SparkContext, SQLContext)
Apache SparkR provides SparkContext to use R programs in the Apache Spark cluster. We can create Apache Spark SparkContext using sparkR.init. If we want to work on DataFrames then the initial step is creating an SQLContext that we can create using SparkContext.
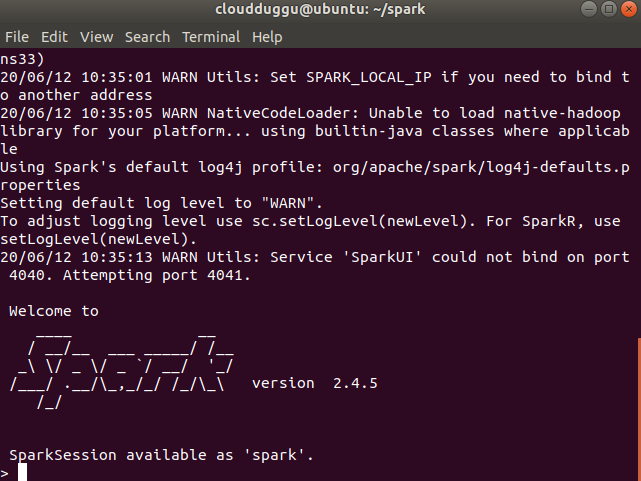
If we are using Apache SparkR shell then SQLContext and SparkContext are created automatically.
Please follow the following steps to start the Apache SparkR shell on Ubuntu 18.04.4 LTS, Spark Version (spark-2.4.5).
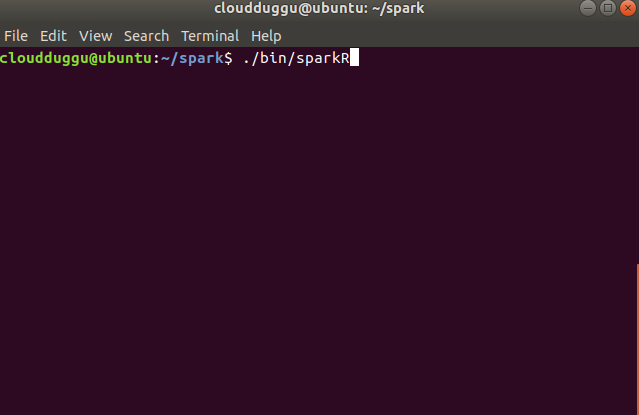
- To start SparkR go to SPARK_HOME and type ./bin/sparkR.
- If you are getting an error then install R by using the below commands.
- Once the installation is completed then go to SPARK_HOME and type ./bin/sparkR.
$sudo add-apt-repository ppa:marutter/c2d4u
$sudo apt update
$sudo apt install r-base r-base-dev
Apache SparkR Staring from RStudio
Apache SparkR supports the tool called RStudio that can be used to run R programs over the Apache Spark cluster. We can start the Apache SparkR from RStudio by setting SPARK_HOME in the environment variable (Sys. getenv). After this load the SparkR package and call sparkR.init.
if (nchar(Sys.getenv("SPARK_HOME")) < 1) { Sys.setenv(SPARK_HOME = "/home/spark") }
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
sc <- sparkR.init(master = "local[*]", sparkEnvir = list(spark.driver.memory="2g"))
Apache SparkR DataFrames Creation
DataFrames can be created in Apache SparkR using a Hive table, a local R Dataframe, or using other data sources.
1. Creating DataFrames From Local R Dataframe
To create an Apache SparkR Dataframe we can convert a Local R Dataframe using createDataFrame and send in local R in data.fra
Let us see with example and understand code line by line and then we will execute it on the terminal.
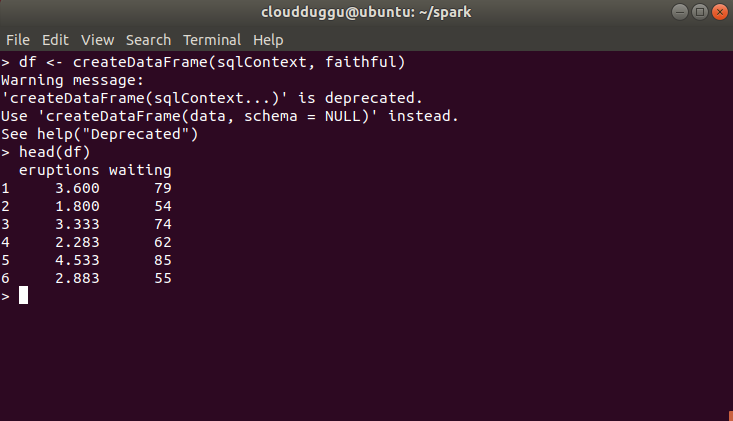
- Create a DataFrame from a faithful dataset from R.
- Display the output on the terminal.
df <- createDataFrame(sqlContext, faithful)
head(df)
2. Creating DataFrames From Data Source
In Apache SparkR, the DataFrames can be created from different types of sources such as JSON files, Parquet files, and so on. Apache SparkR uses the read. df to create a DataFrame. We can use SparkR connectors to use some general formats such as Avro, CSV, and so on.
For this example, we will use the people.json file which is located below the path. Please check your SPARK_HOME directory for the same.
/examples/src/main/resources/people.json
Let us see with example and understand code line by line and then we will execute it on the terminal.
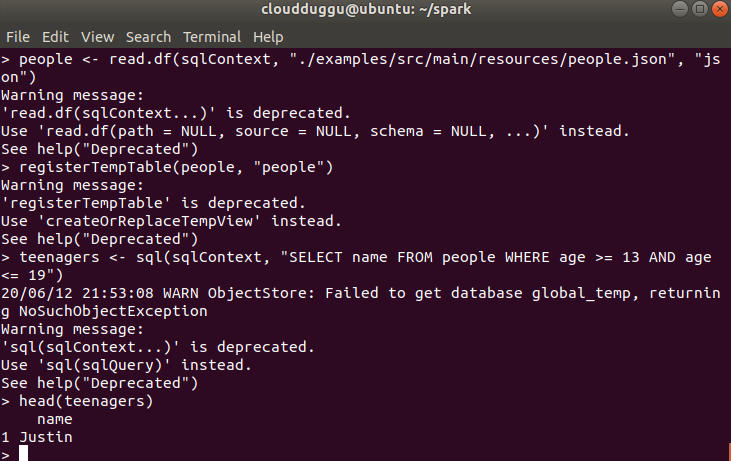
- We will use people.json to create Dataframe.
- Display content of Dataframe on the terminal.
- Display structure of Dataframe.
people <- read.df(sqlContext, "./examples/src/main/resources/people.json", "json")
head(people)
printSchema(people)
3. Creating DataFrames From Hive Tables
Apache SparkR DataFrames can be created from Hive tables. To do that we need to create a HiveContext which can access tables in the Hive metastore.
Let us see with example and understand code line by line.
- Create a HiveContext from existing SparkContext.
- Create a hive table with the name src.
- Load data from kv1.txt file into hive table src.
- Create a HiveQL query.
- Display the result on the terminal.
hiveContext <- sparkRHive.init(sc)
sql(hiveContext, "CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sql(hiveContext, "LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
results <- sql(hiveContext, "FROM src SELECT key, value")
head(results)
Apache SparkR DataFrame Operations
Apache SparkR provides various functions to do data processing. Some basic examples are mentioned below.
1. Rows, Columns Selection
Let us see with example and understand code line by line, and then we will execute it on the terminal.
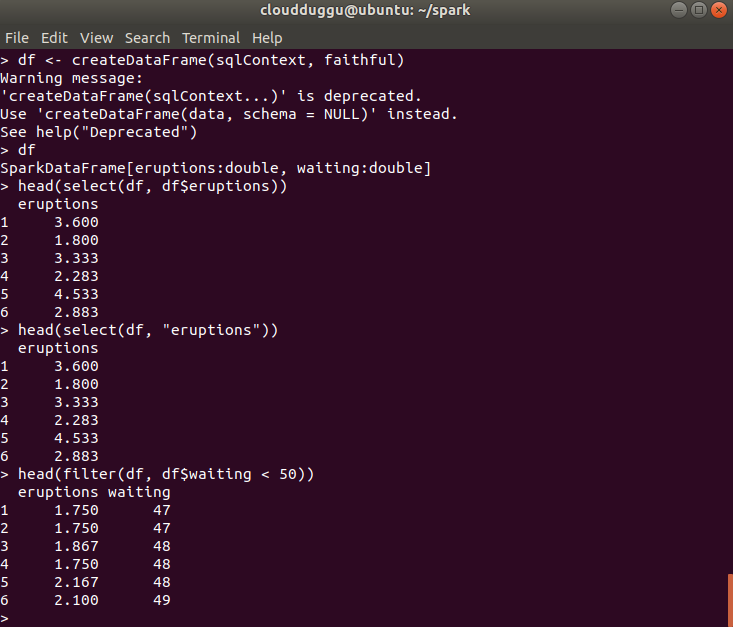
- Create the DataFrame.
- Get basic information about the DataFrame.
- Select only the "eruptions" column.
- Pass in column name as strings.
- Put filter to fetch only those records in which wait time is less than 50 minutes.
df <- createDataFrame(sqlContext, faithful)
df
head(select(df, df$eruptions))
head(select(df, "eruptions"))
head(filter(df, df$waiting < 50))
2. Grouping, Aggregation Functions
Apache SparkR Dataframes support commonly used functions to aggregate data after grouping.
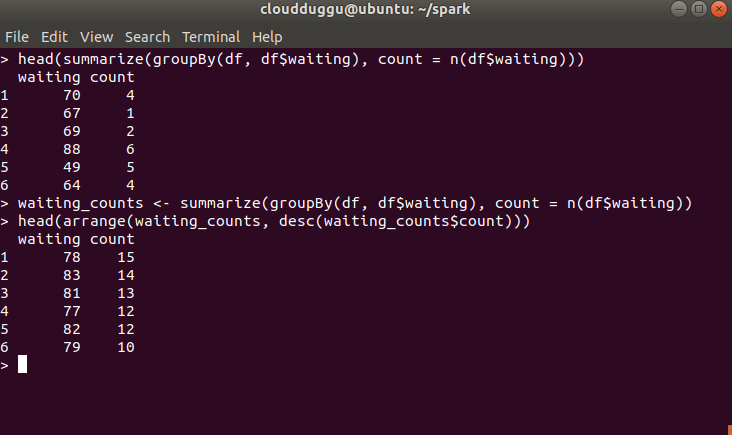
In this example, we will compute a histogram of the waiting time in the faithful dataset.
Let us see with example and understand code line by line and then we will execute it on the terminal.
- To count the waiting time we will use the 'n' operator.
- The output of aggregation can be sorted to receive the waiting times.
head(summarize(groupBy(df, df$waiting), count = n(df$waiting)))
waiting_counts <- summarize(groupBy(df, df$waiting), count = n(df$waiting))
head(arrange(waiting_counts, desc(waiting_counts$count)))
3. Arithmetic Functions
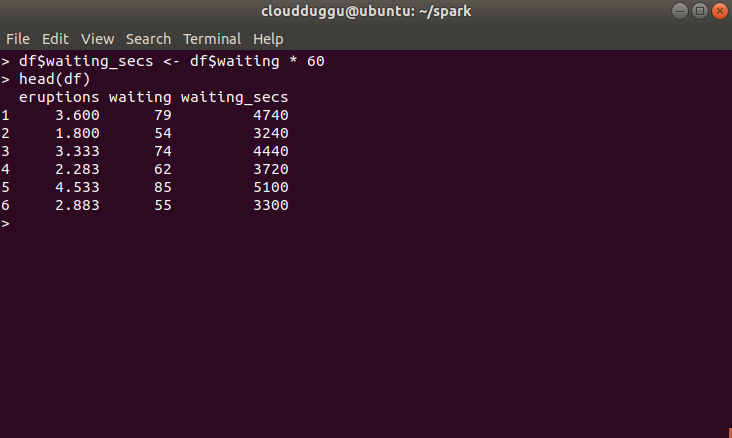
This example shows Arithmetic Functions for data processing.
- Convert waiting time from hours to seconds.
- Display the results on the terminal.
df$waiting_secs <- df$waiting * 60
head(df)
SQL Queries In Apache SparkR
In Apache SparkR a Dataframe can be created as a temporary table and SQL operations can be performed on that programmatically and a Datafreame is returned as an output.
For this example, we will use the people.json file which is located at the below path. Please check your SPARK_HOME directory for the same.
/examples/src/main/resources/people.json
Let us see with example and understand code line by line and then we will execute it on the terminal.
- Load a JSON file.
- Register this DataFrame as a table.
- Run SQL statements by using the SQL method.
- Display the results on the terminal.