What is Machine Learning (ML)?
Machine learning is a way to educate the computer to make the correct decision based on data feed. It is an application of artificial intelligence that provides systematic methods to search for the development of algorithms that can be learned from datasets. Using Machine Learning we can perform some computation on data and perform predictions. Machine Learning helps the system to works on required programming algorithms to resolve a problem.
Machine Learning Methods
The following are the three methods of Machine Learning.
- Supervised Learning
- Reinforcement Learning
- Unsupervised Learning
Using this method of Machine Leaning a system learns a function that is used to map an input pair with an output pair.
This method is used when a system works in a dynamic environment in which it has to achieve a goal (for example playing a game or driving a car) so as the program moves further it makes a sequential decision and tries to maximize it.
This method is used to keep checking the past undetected patterns of a dataset with a little human guidance.
What is Apache Spark MLlib?
Apache Spark MLlib is the Machine learning (ML) library of Apache Spark architecture and one of the major components of Spark. The goal of Spark MLlib is to make machine learning easy and scalable to use. It provides common learning algorithms and utilities such as classification, regression, clustering, collaborative filtering, and dimensionality reduction to perform different kinds of operations. Using Apache Spark (MLlib) a data scientist focuses on the data problem and avoids other problems such as infrastructure or configuration.
Apache Spark MLlib is divided into the following two packages.
- spark.mllib package
- spark.ml package
It contains the original API built on top of RDDs
It provides a higher-level API built on top of DataFrames for constructing ML pipelines.
Apache Spark MLlib Features
Apache Spark MLlib provides the following features.
1. Ease to Use
Apache Spark MLlib can be used in Java, Scala, Python, and R and can be plugged with Hadoop workflow.
2. Performance
Apache Spark MLlib uses the interactive processing of Spark to provide high performance. Compared to the one-pass approximations of MapReduce, MLlib uses its great quality algorithms to utilize the Apache Spark iteration feature.
3. Distributed Framework
Apache Spark MLlib uses the distributed, memory-based architecture of Apache Spark to provide almost 9 times better performance compared to Apache Mahout that is the disk-based architecture.
Apache Spark MLlib Tools
Apache Spark MLlib provides the following tools.
- ML Algorithms:- These are common learning algorithms such as classification, regression, clustering, and collaborative filtering.
- Featurization:- This tool contains transformation, feature extraction, reduction dimensionality, and selection.
- Pipelines:- It facilitates the necessary tools for tuning, constructing, and evaluating the Machine learning Pipelines.
- Persistence:- It helps in saving and loading algorithms, models, and Pipelines.
- Utilities:- It provides utilities for linear algebra, statistics, data handling, etc.
Apache Spark MLlib Algorithms and Utilities
Apache Spark MLlib provides the following list of Algorithms.
Let us see each in detail.
1. Basic Statistics
Basic Statistics covers the following list of machine learning techniques.
- Summary Statistics: It uses the function colStats of Statistics and provides the RDD[vector] column summary stats.
- Correlations: It performs the correlation of two sets of data. The currently supported correlation methods are Spearmen and Pearson’s.
- Stratified Sampling: This method works on sampleByKey and sampleByKeyExact.
- Hypothesis Testing: This tool is used to check if the result is statical and meaningful and if the result is generated by luck or not.
- Random Data Generation: This method is helpful in case of prototyping, randomized algorithms, and performance measurement
- Kernel Density Estimation: This helps to visualize the innovative probability distributions without asking opinions about the appropriate distribution.
2. Regression Analysis
The Regression analysis is used for the statistical process to measure the connection between dependent and independent variables. It is used for two purposes the first one is to make predictions and forecasting, and the second one is to check the relationship of dependent and independent variables.
3. Classification(Binary & Multiclass)
The Binary classification uses the classification rule to group the elements into two parts. The Multiclass classification represents the problem to classify the cases into one for many classes.
4. Clustering
The Cluster analysis is the representation of grouping the same types of objects on a cluster. It is used for statistical data analysis and data mining such as image analysis, pattern recognition, bioinformatics, computer graphics, and so on.
Apache Spark MLlib supports the following packages.
- K-means
- Gaussian mixture
- Power iteration clustering (PIC)
- Latent Dirichlet allocation (LDA)
- Bisecting k-means
- Streaming k-means
5. Dimensionality Reduction
The Dimensionality reduction is used to decrease the random input variables because the high amount of input creates the performance problem in Machine learning algorithms. The Dimensionality reduction methods are linear algebra, feature selection, autoencoders, projection methods, and so on.
6. Feature Extraction
Feature extraction uses the dataset and creates new features. Its main task is to decrease the number of features from a dataset. Once the new reduced feature dataset is created then it is reviewed with the original set of features for more information.
7. Optimization
The optimization algorithm is a method that keeps executing in a loop by checking multiple solutions till the time it gets the best one.
Program for Movie Rating System
The following program will perform the prediction based on the Moview rating.
The Movie Ratings are as below.
- 5: Must see
- 4: Will enjoy
- 3: It’s okay
- 2: Fairly bad
- 1: Awful
The movie will not be suggested if the prediction rating is below 3. Rating mapping with confidence scores is as below.
- 5 -> 2.5
- 4 -> 1.5
- 3 -> 0.5
- 2 -> -0.5
- 1 -> -1.5.
The Movie Dataset and the scala program are located on the following path. Please check your SPARK_HOME directory.
/home/cloudduggu/spark/data/mllib/sample_movielens_data.txt
examples/src/main/scala/org/apache/spark/examples/mllib/RankingMetricsExample.scala
Run RankingMetricsExample.scala program from SPARK_HOME directory.
./bin/run-example org.apache.spark.examples.mllib.RankingMetricsExample
Let us understand the code line by line and then we will execute it on the terminal.
- Import spark.mllib RankingMetrics & Rating packages.
- Read in the rating data.
- Define the rating to 0 or 1. Now 1 indicates that the movie is suggested.
- Summarize all ratings.
- Build the model.
- Create a function that can compute the ratings(0 to 1).
- Take the top 10 predictions for each user.
- Let's imagine that if a user is rating 3 then it is a suitable record.
- Compare with the top ten most relevant documents.
- Instantiate metrics object.
- Precision at K.
- Mean average precision.
- Normalized discounted cumulative gain.
- Get predictions for each data point.
- Get the RMSE using regression metrics.
- Display R-squared on the terminal.
import org.apache.spark.mllib.evaluation.{RankingMetrics, RegressionMetrics}
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.sql.SparkSession
object RankingMetricsExample {
def main(args: Array[String]) {
val spark = SparkSession.builder
.appName("RankingMetricsExample")
.getOrCreate()
import spark.implicits._
val ratings = spark.read.textFile("data/mllib/sample_movielens_data.txt").rdd.map { line =>
val fields = line.split("::")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble - 2.5)
}.cache()
val binarizedRatings = ratings.map(r => Rating(r.user, r.product,
if (r.rating > 0) 1.0 else 0.0)
).cache()
val numRatings = ratings.count()
val numUsers = ratings.map(_.user).distinct().count()
val numMovies = ratings.map(_.product).distinct().count()
println(s"Got $numRatings ratings from $numUsers users on $numMovies movies.")
val numIterations = 10
val rank = 10
val lambda = 0.01
val model = ALS.train(ratings, rank, numIterations, lambda)
def scaledRating(r: Rating): Rating = {
val scaledRating = math.max(math.min(r.rating, 1.0), 0.0)
Rating(r.user, r.product, scaledRating)
}
val userRecommended = model.recommendProductsForUsers(10).map { case (user, recs) =>
(user, recs.map(scaledRating))
}
val userMovies = binarizedRatings.groupBy(_.user)
val relevantDocuments = userMovies.join(userRecommended).map { case (user, (actual,
predictions)) =>
(predictions.map(_.product), actual.filter(_.rating > 0.0).map(_.product).toArray)
}
val metrics = new RankingMetrics(relevantDocuments)
Array(1, 3, 5).foreach { k => println(s"Precision at $k = ${metrics.precisionAt(k)}") }
println(s"Mean average precision = ${metrics.meanAveragePrecision}")
Array(1, 3, 5).foreach { k => println(s"NDCG at $k = ${metrics.ndcgAt(k)}") }
val allPredictions = model.predict(ratings.map(r => (r.user, r.product))).map(r => ((r.user,
r.product), r.rating))
val allRatings = ratings.map(r => ((r.user, r.product), r.rating))
val predictionsAndLabels = allPredictions.join(allRatings).map { case ((user, product),
(predicted, actual)) =>
(predicted, actual)
}
val regressionMetrics = new RegressionMetrics(predictionsAndLabels)
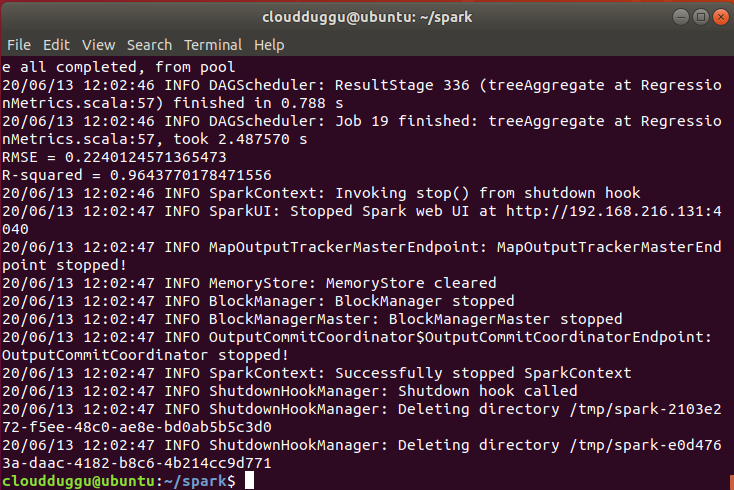
println(s"RMSE = ${regressionMetrics.rootMeanSquaredError}")
println(s"R-squared = ${regressionMetrics.r2}")
}
}