What is Apache Spark RDD?
Apache Spark RDD stands for “Resilient Distributed Dataset”, which is the fundamental structure and building blocks of any Spark application. RDD is immutable and follows transformations and actions. Each dataset in RDD is logically partitioned and spread across multiple nodes and due to this, it can be computed on the distributed node of the cluster. It can automatically rebuild in case of node failure.
The following are the representation of each word of RDD.
- Resilient:-It represents a fault-tolerance feature which means in case of node failure it can rebuild data.
- Distributed:-It represents the distribution of data across multiple nodes.
- Dataset:-It represents the type of data like CSV file, text, and JSON file which can be loaded for processing.
What is Partition in RDD?
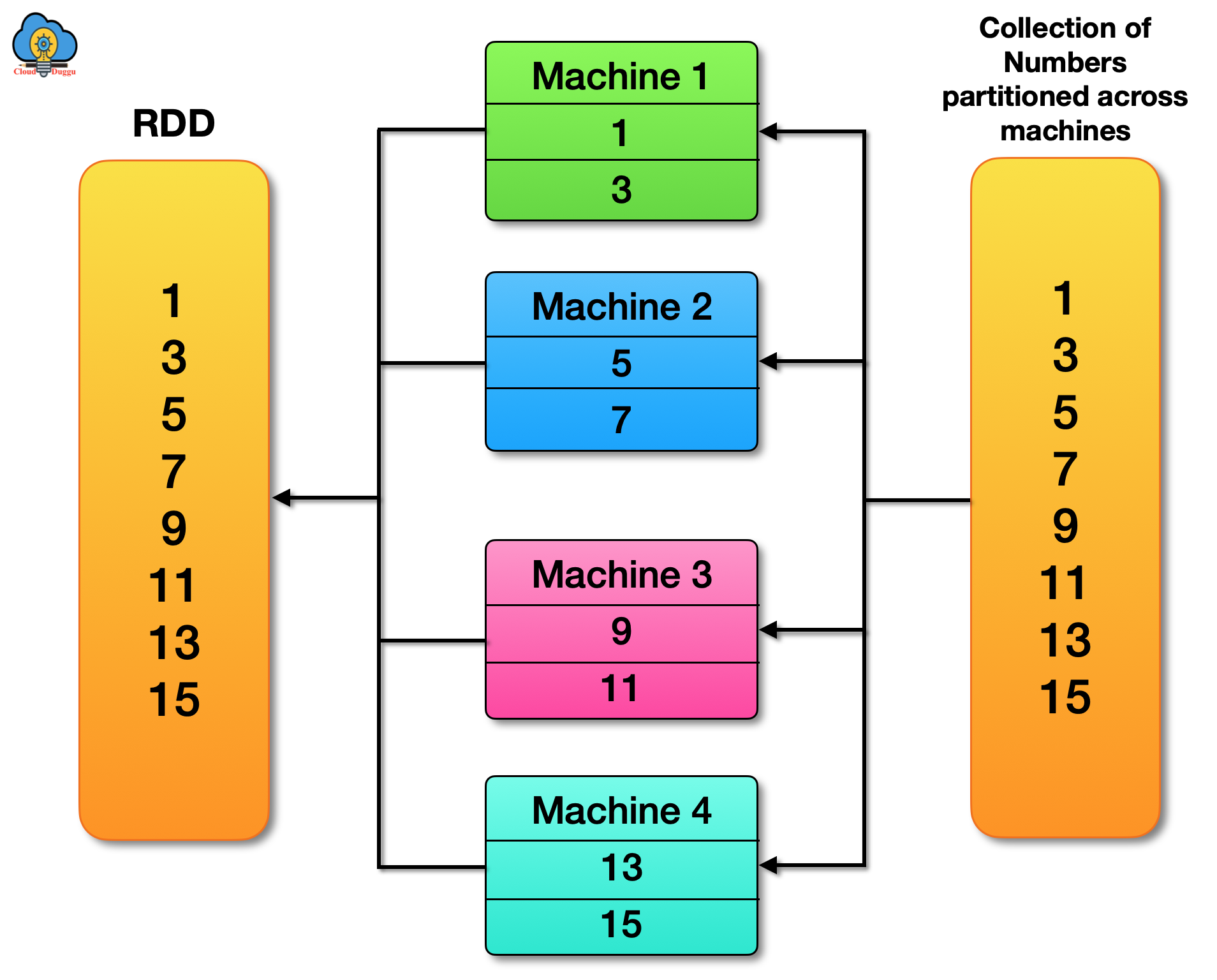
The Partitions are the parts of RDD that allow Spark to execute in parallel on a cluster of nodes. It is distributed across the node of the cluster and logical division of data. It is derived from MapReduce and immutable. All input, intermediate, and output data is presented as partitions in which one task process one partitions at a time. RDD is a group of partitions.
How to create RDD?
RDD is an abstraction of Apache Spark and a collection of components which are partition on the cluster of nodes. A user can persist RDD in memory for better parallel operation across the cluster.
There are the following three ways in which an RDD is created.
- An existing collection can be parallelized in the driver program to create RDD.
- By taking the reference of a dataset in an external storage system such as a shared filesystem, HDFS, HBase.
- Creating RDD by referring to already exist RDD.
Let us understand it in detail.
Parallelizing Collection
Parallelizing Collections are created by calling SparkContext’s parallelize () method on an existing collection in your driver program. This method will create RDD in the Spark shell and perform actions on that.
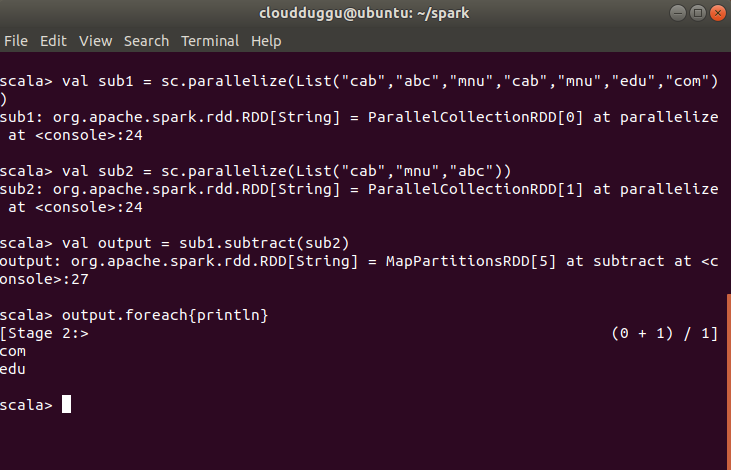
The below example will show subtracted value from rdd sub1 and rdd sub2 using subtract () transformation.
The important point to notice about parallel collections is the number of partitions to cut the dataset into. Spark will run one task for each partition of the cluster and typically we need two to four partitions for each CPU in the cluster. Although Spark set the number of partitions automatically based on cluster and it can be set manually by passing it as a second parameter to parallelize.
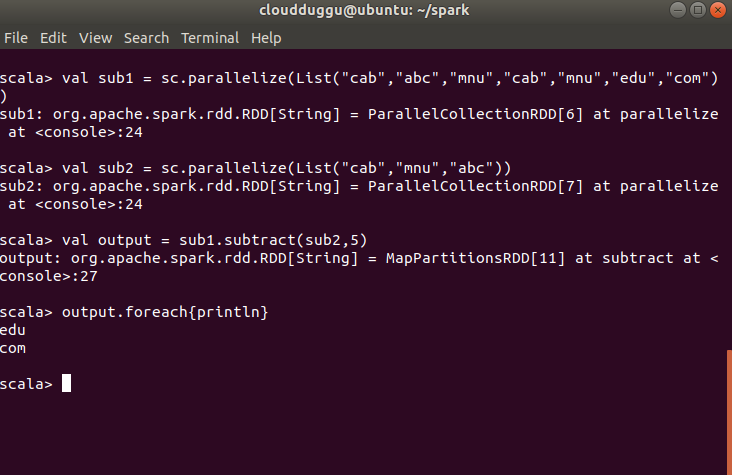
Another example in which subtract () transformation is used and partition is given manually.
Referencing External Dataset
In this mode of RDD creation, the RDD can be created by loading a data set from an external dataset present in the local file system, Cassandra, HDFS, HBase, or S3.
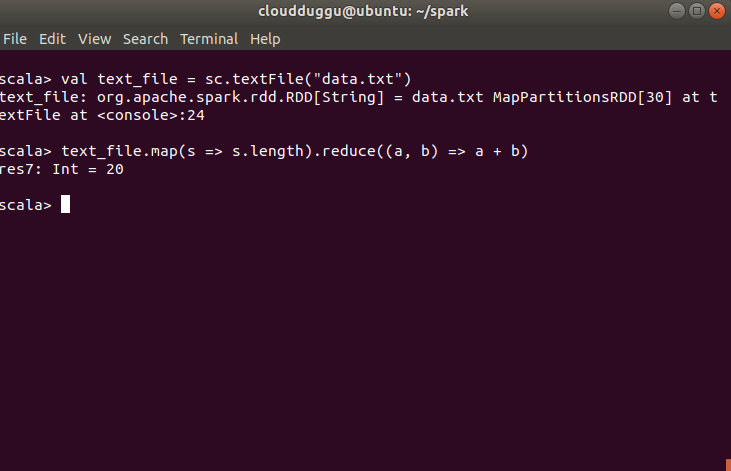
We have created data.text file which is present under “/home/cloudduggu/hadoop/” and it has 1,2,3,4,5,6,7,8,9,10 records. We will load the file and create a dataset with the name text_file and will act.
Creating RDD By Referring Already Exist RDD
In this mode of RDD creation, an RDD can be created by performing a transformation on an existing RDD in which a new RDD will be created without affecting the existing RDD as RDD are immutable.
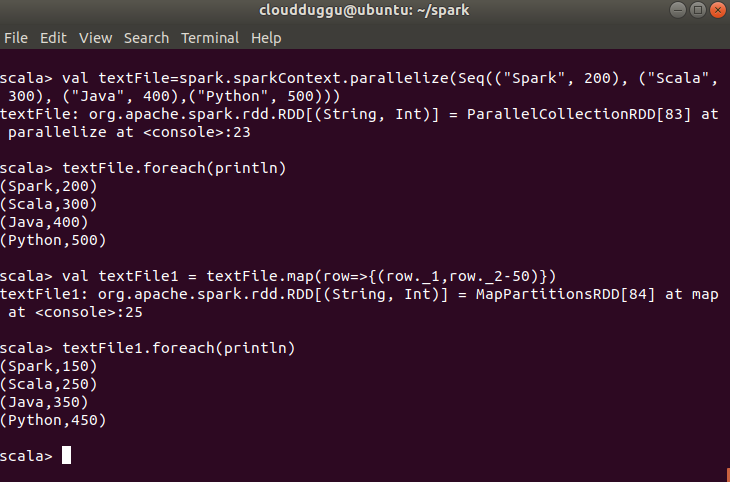
In the below example we have created textFile RDD and printed value, after that we created a new RDD with name textFile1 by applying map() method.
RDD Operations
Apache Spark supports the following two types of operations.
- Transformations
- Actions
Let us understand each in detail.
Transformations
Transformations are a set of operations that define how RDD should be transformed. It creates new RDD from existing RDD by applying functions like Map, Flat map, filter, etc. All transformations in Spark are lazy in nature which means they do not compute their results instead they just remember the transformations applied on the dataset and add execution of transformation in DAG (Directed Acyclic Graph). The transformations are only computed when an action is called, that is why Transformations are called lazy in nature.
Let us understand it using the below example.
- The first line represents the base RDD (test) which is created based on an external file, it is just a pointer to the data.txt file.
- The second line represents the result of the map() function. Again it will not execute due to laziness.
- In the third line action will be called by using the reduce() function and in this step Spark will break the computation into tasks to run on separate machines and each machine runs both its part of the map and a local reduction and after that result will be returned to the driver program.
Actions
Actions will return a value to the driver program after running a computation on the dataset as we know Transformations are lazy in nature until we perform Actions on the dataset. It uses a lineage graph to load data onto the RDD in a particular order. It is a process to send data from executors to the driver. Collect (), count (), first (),saveAsTextFile(path) are some of the actions in Spark.
The below figure shows the Spark runtime when a user’s driver program launches multiple workers, which read data blocks from a distributed file system and can persist computed RDD partitions in memory and return the result to the driver program.