Apache Spark Interfaces (RDD, DataFrame, Dataset)
Apache Spark provides the following three key interfaces.
We will learn and understand each interface in this tutorial.
Let us see each interface in detail.
1. RDD
Apache Spark RDD is the basic structure and structure blocks of any Spark application. It provides an interface for structure data that can be processed over a cluster of nodes. Spark RDD is the lowest level of API and it can be created in many ways. RDD is the primary data structure of the Apache Spark system which provides APIs in multiple languages.
There are the following three ways to create a Spark RDD.
- By applying Parallelism to already present collection.
- By referring to the external dataset that is stored in external storage.
- By referring to already created RDD.
Please refer RDD introduction for more details.
2. DataFrame
DataFrame is the collection of distributed and built datasets that are organized in columns. By theoretically data frame can be compared with relational database tables. DataFrame supports a variety of functions to perform different types of operations and resolve basic analysis issues. DataFrame can be created from sources like Hive tables. existing RDDs or external databases.
DataFrame is designed to perform multiple functions.
- It provides support for multiple languages such as R, Python, Scala, and Java.
- DataFrame can support various data sources such as JSON, CSV, SQL, XML, RDBMS, and so on.
- It can be structure and semi-structured data. DataFrame stores data in table format.
- Using DataFrame user can perform various operations such as filter, select, and so on.
How to create DataFrame?
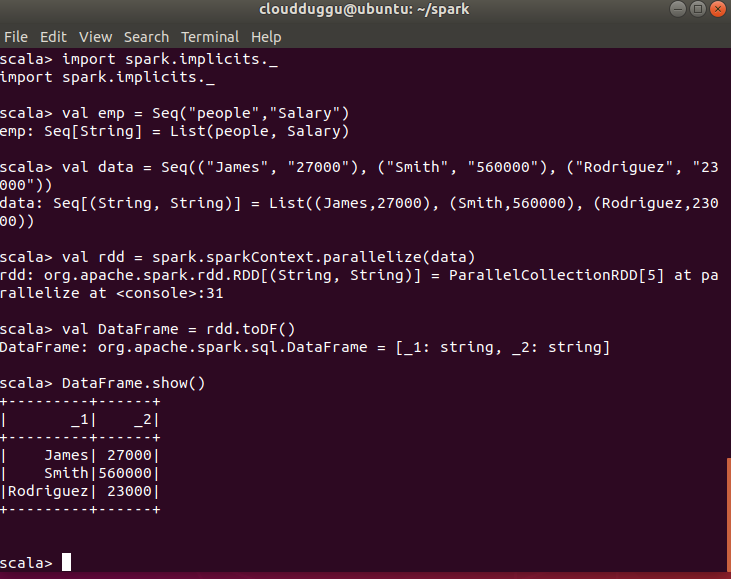
The following steps will create an RDD.
- Initially Spark implicit will be imported.
- An easy way to create DataFrame is from existing RDD.
- We will create an RDD from a sequence of collections by calling the parallelize() function from SparkContext.
- We will use toDF() to create DataFrame in Spark by default, it creates column names as “_1” and “_2” as we have 2 columns.
- And at last, we will print the value of DataFrame.
3. Dataset
Apache Spark Dataset is the SparkSQL data structure. It is outlined with a relation schema and it's API provides a very safe and object-oriented programming interface. It provides compile-time type safety—which means that production applications can be checked for errors before they are run and they allow direct operations over user-defined classes. Dataset provides operation such as groupBy(), join(), sum() to perform different types of operations.
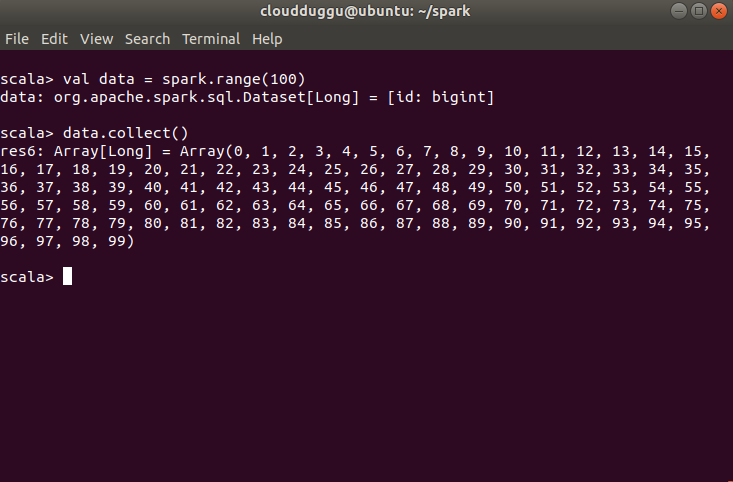
How to create Dataset?
We will create a Dataset of 100 integers.