The objective of this tutorial is to describe step by step process to install Spark 2.4.5 (Version spark-2.4.5-bin-hadoop2.7) on Ubuntu 18.04.4 LTS (Bionic Beaver), once the installation is completed you can play with Spark.
Platform
- Operating System (OS). You can use Ubuntu 18.04.4 LTS version or later version, also you can use other flavors of Linux systems like Redhat, CentOS, etc.
- Spark. We have used Spark 2.4.5 (Version spark-2.4.5-bin-hadoop2.7).
Download Software
- VMWare Player for Windows
- Ubuntu
- Spark
- Eclipse for windows
https://my.vmware.com/web/vmware/free#desktop_end_user_computing/vmware_player/7_0
http://releases.ubuntu.com/18.04.4/ubuntu-18.04.4-desktop-amd64
https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
https://www.eclipse.org/downloads/
For VMware and Ubuntu installation please refer to “Hadoop Installation on Single Node” in the Hadoop section.
Click Here To Download - spark-2.4.5-bin-hadoop2.7.tar (264.2 MB)Steps to Install Spark 2.4.5 on Ubuntu 18.04.4 LTS
Step 1. Please download Spark 2.4.5 from the below link.
On Windows: https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
On Linux: $wget https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
Step 2. Install Java 8 using the below command.
$sudo apt-get install openjdk-8-jdk
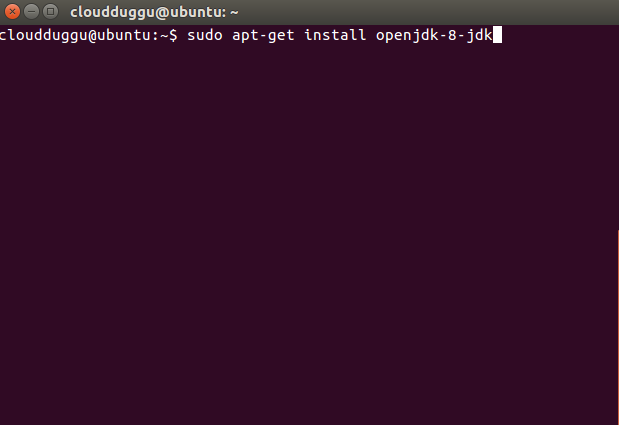
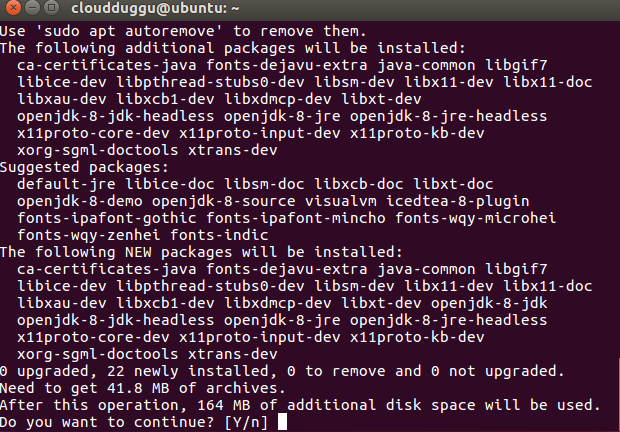
Press Y to continue the installation.
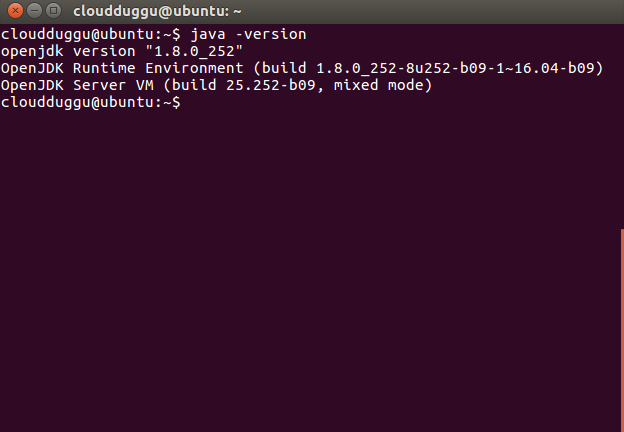
Once the java installation is completed please verify it by running the below command.
$java –version
Step 3. Now install Apache Spark. Download it from cmd using the below command.
$wget https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
In our case, it is present at the below location.
/home/cloudduggu/spark-2.4.5-bin-hadoop2.7.tgz
Step 4. Now extract the tar file by using the below command and rename the folder to spark to make it meaningful.
$tar xzf spark-2.4.5-bin-hadoop2.7.tgz
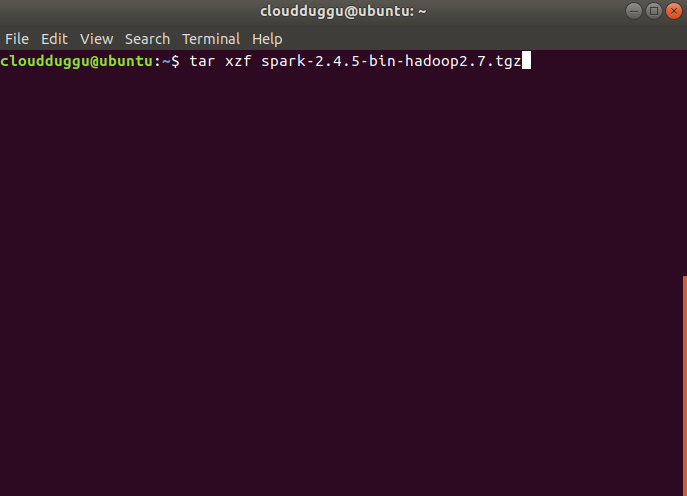
$mv spark-2.4.5-bin-hadoop2.7 spark
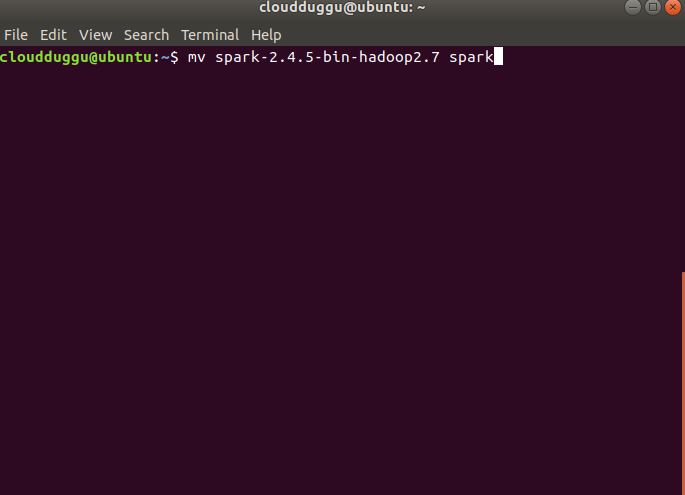
Step 5. Now edit .bashrc file using nano editor and export JAVA home and Spark home. In our case below is the location please verify yours.
export SPARK_HOME=/home/cloudduggu/spark/
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-i386/
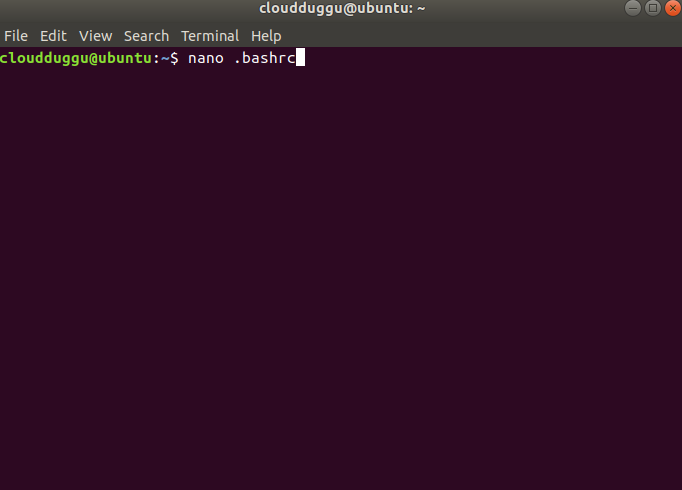
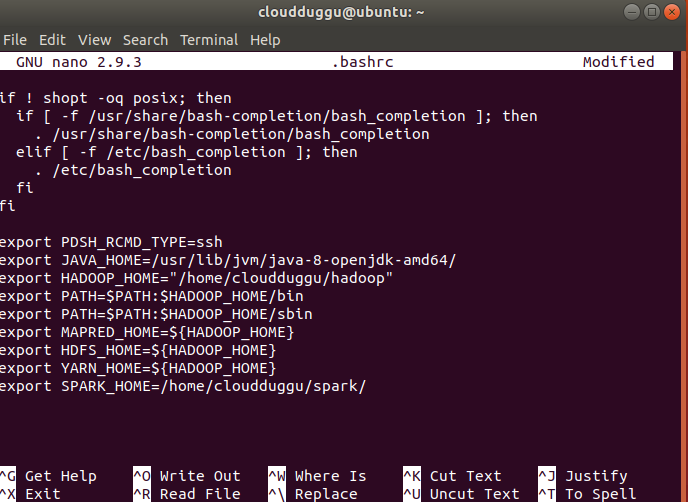
Now save the changes by pressing CTRL + O and exit from nano editor by pressing CTRL + X.
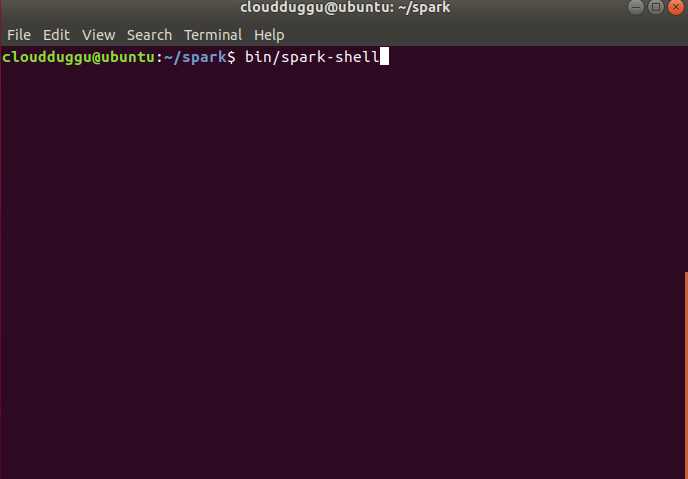
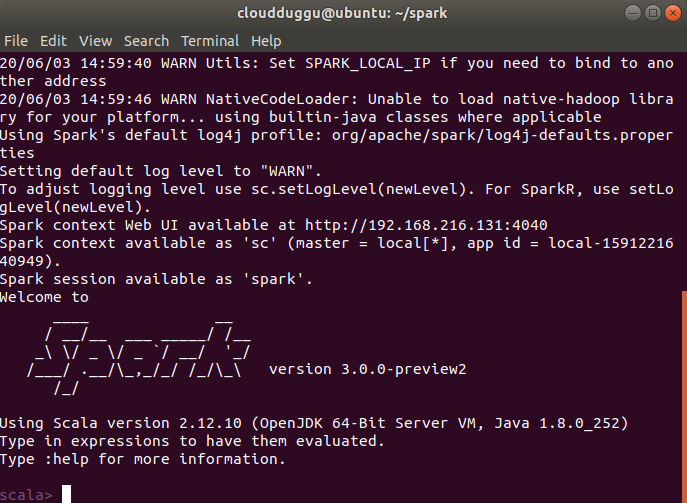
Step 6. So now Spark installation is completed. Let us start the Spark shell by using the below command. Run it from spark home.
$ /home/cloudduggu/spark/bin/spark-shell