What is Apache Spark Ecosystem?
Apache Spark is a lightning-fast centralized analytics engine. It allows usages of more than 80 high-level operators to create applications. Apache Spark can be deployed on a stand-alone system or a cluster of nodes.
Apache Spark provides a robust set of components to perform different types of operations such as GraphX, Spark Streaming, Spark Core, SparkR, Spark SQL, and MLlib.
Now let us see each component of Apache Spark in the following section.
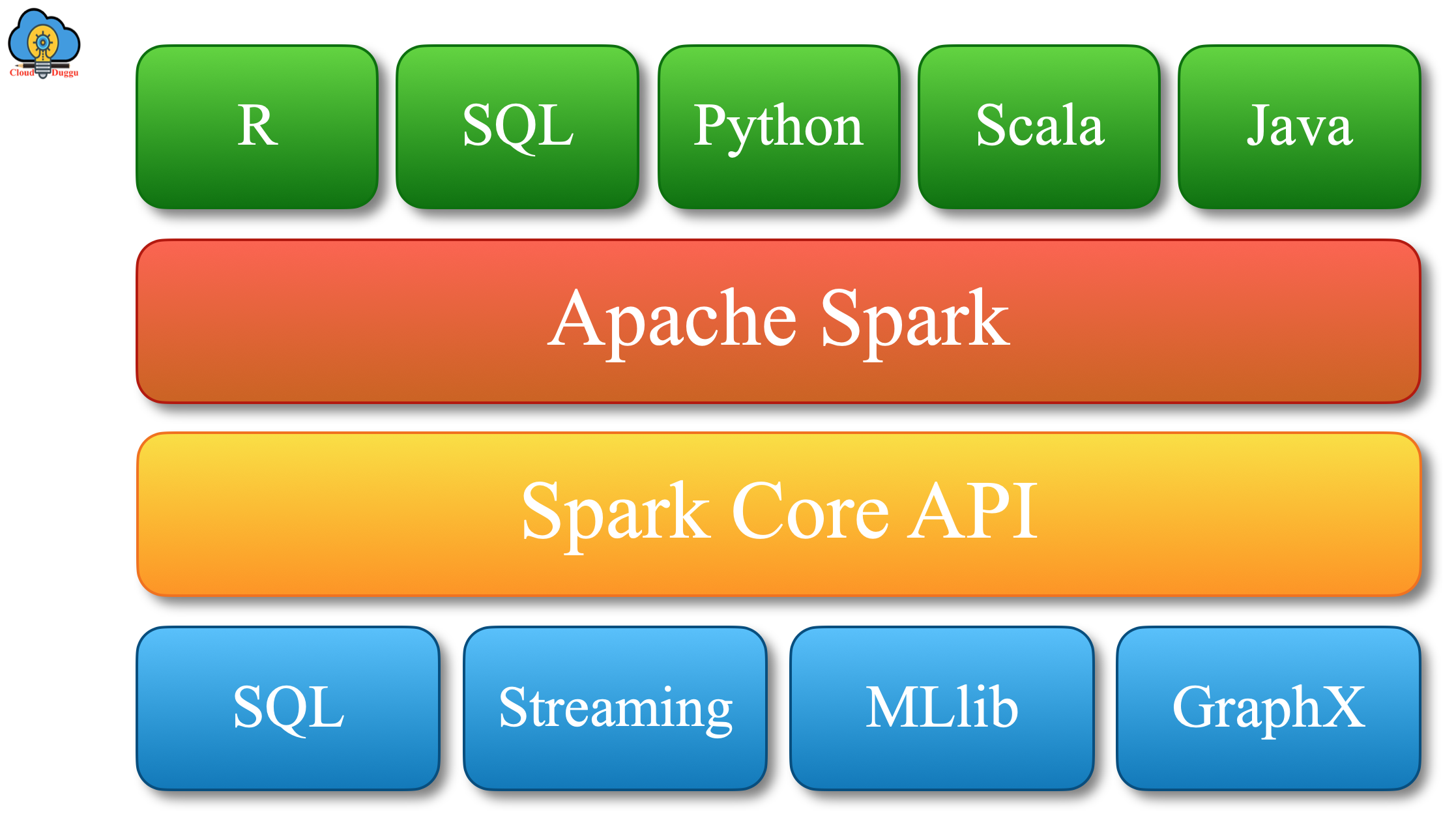
1. Spark Core
Apache Spark Core is an execution model that is responsible for job scheduling, memory management, interaction with a storage system, and so on. It supports multiple application and its core functionality are access using Java, Python, or Scala APIs.
2. Spark SQL
Apache Spark SQL is a component of Spark that is used to process structured and semistructured dataset. Spark SQL supports DSL(Domain Specific Language) language to perform different kinds of operations.
Spark SQL has the following features.
A. Integrated with Spark Programs
Spark SQL allows querying structured data inside Spark programs, using either SQL or a familiar DataFrame API. It is usable in Java, Scala, Python, and R.
In the following example, the lambda function will be applied to the result of SQL.
B. Uniform Data Access
SQL and Dataframes provide a simple way of accessing the data sources that include JSON, JDBC, Parquet, Hive, Avro, and so on.
The following example shows the query and joining of different data sources.
C. Connect through JDBC or ODBC
We can make a connection with Apache Spark SQL using JDBC or ODBC drivers.
You can use any BI tool to query data.

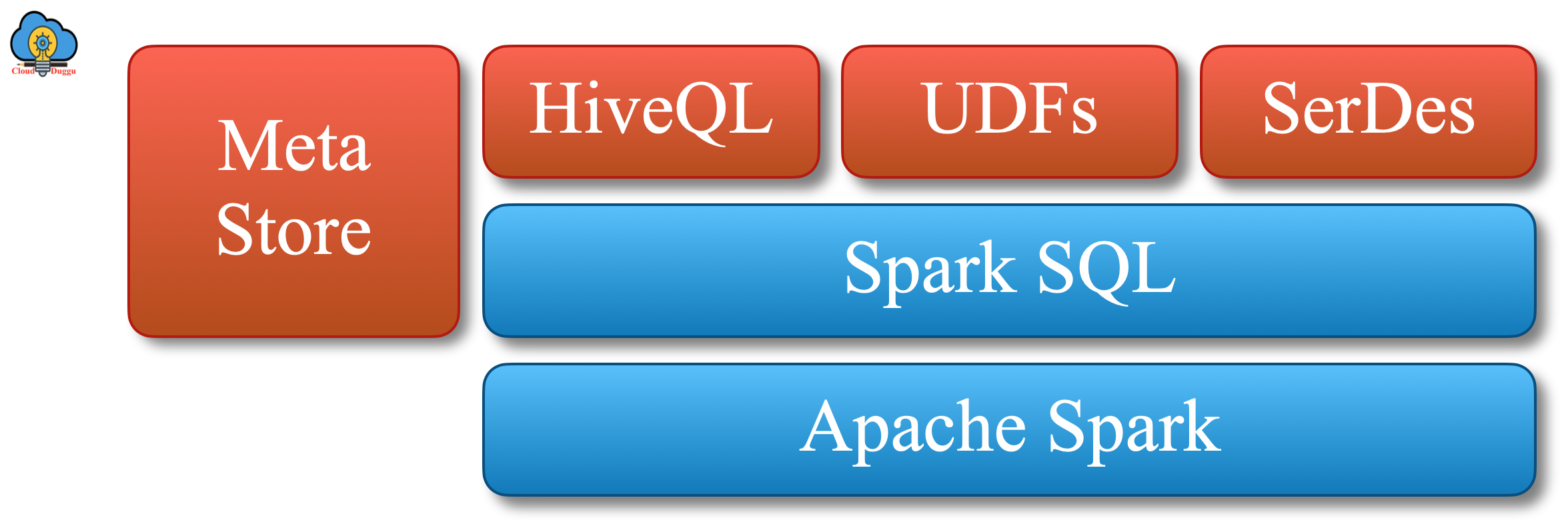
D. Hive Integration
Spark SQL provides supports for Hive language(HiveQL). Using HiveQL we can access the Hive table and perform different operations.
Spark SQL can also use Hive's SerDes, Meta stores, UDFs.
3. Spark Streaming
Apache Spark Streaming is the core component of Spark that is used to perform streaming processing for live data. Spark streaming process input data in mini-batches and apply RDD transformations on mini-batches. The source of input data would be Kinesis, Flume, Kafka, and so on.
Once the processing is completed the data is shifted to the HDFS filesystem or dashboard or databases.

The workflow of Spark Streaming
Apache Spark Streaming takes real-time data from an input stream and breaks it into multiple batches after this Spark engine process this data and generates the final result in batches.

Spark Streaming has the following features.
A. Ease to Use
Apache Spark Streaming supports high-level language APIs to perform the streaming operation. The supported languages are Scala, Java, and python.
The following is an example of a tweet count works on a sliding window.
B. Fault Tolerance
Apache Spark Streaming helps to recover from fault tolerance/node crash without writing down any extra code.
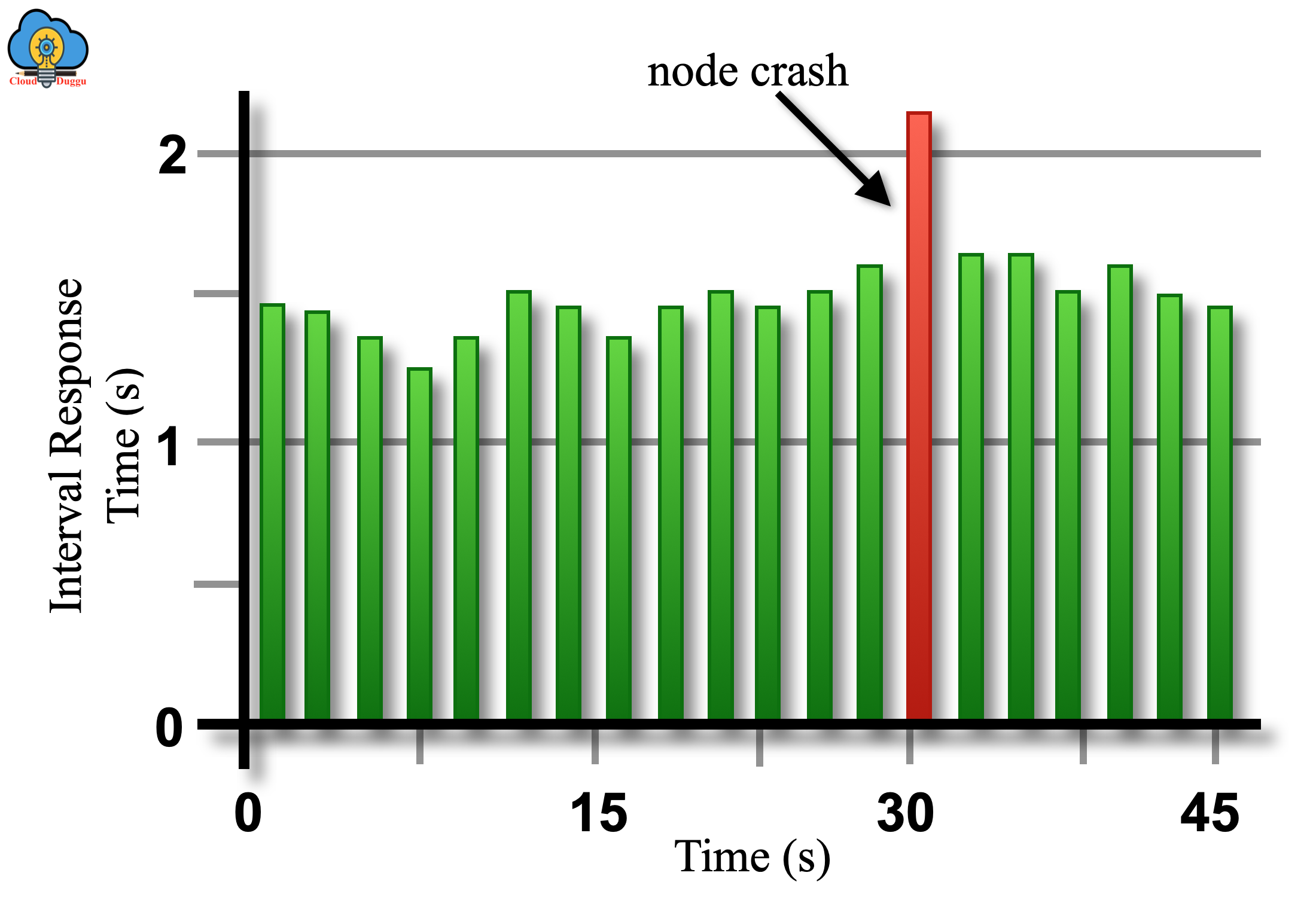
C. Integration with Spark
Apache Spark Streaming provides the features to reuse the code for join streams, batch processing, and ad-hoc queries.
The following example fetches the words which are having a higher frequency.
4. MLlib Machine Learning Library
Apache Spark MLlib is a distributed machine-learning framework of Spark. It is designed to make practical machine learning scalable and easy. There are some common machine learning and statistical algorithms implemented with Spark MLlib such as Summary Statistics, Stratified Sampling, Correlations, Hypothesis Testing, Random Data Generation, and Kernel Density Estimation.
Apache Spark MLlib provides the following features.
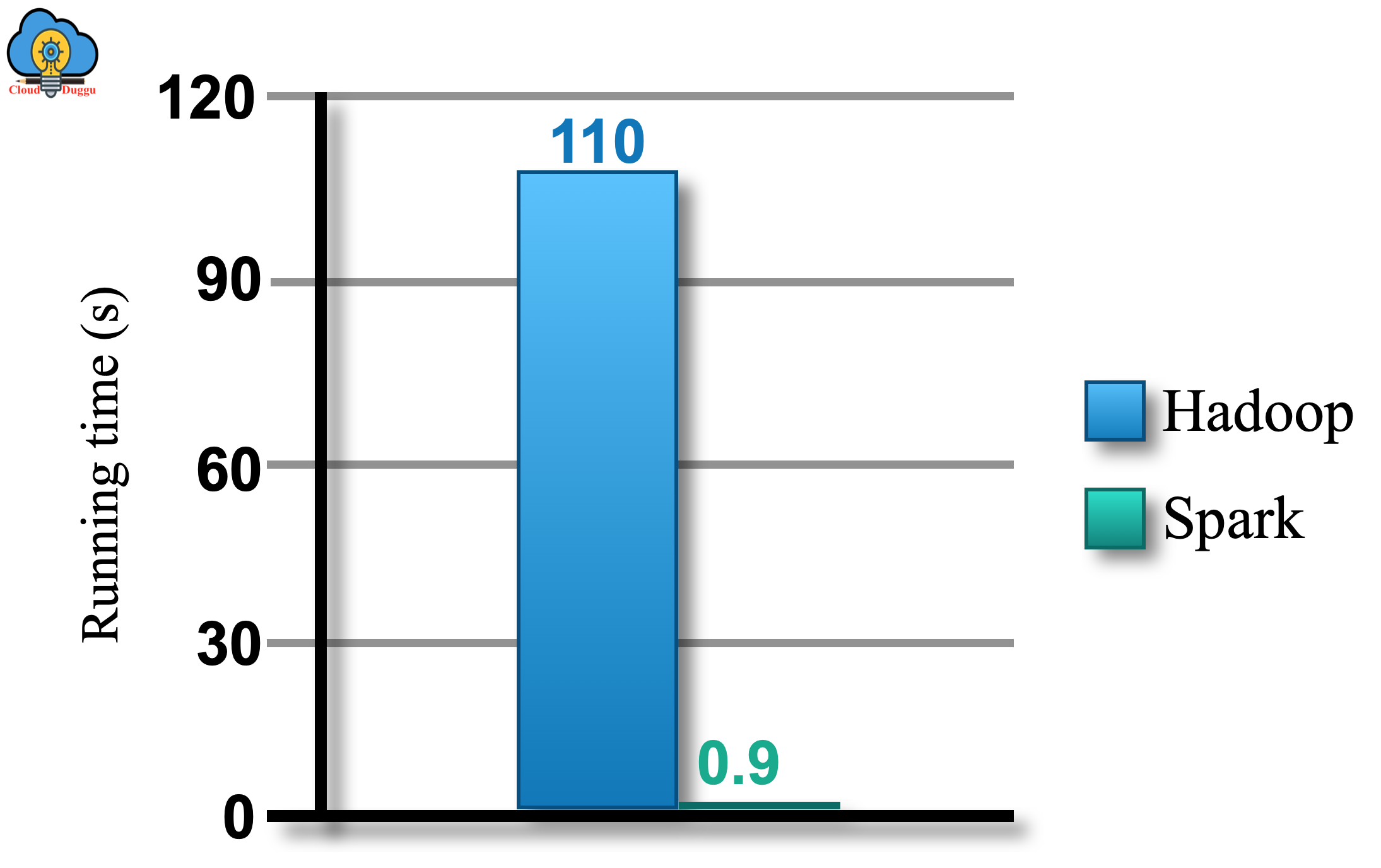
A. High Performance
Apache Spark MLlib comprises of the rich quality of algorithms that take benefits of redundancy and provides 100 times better results compare to MapReduce.
The following is the Logistic regression in Hadoop and Spark.
B. Flexible to Use
Apache MLlib can be interoperated with NumPy in Python and R libraries and supports Hadoop data sources.
The following is an example of MLlib in Python code.
C. Run-on any Platform
Apache Spark MLlib can easily run on standalone as well as on the cluster of nodes such as Mesos, EC2, Hadoop YARN, and so on. Spark MLlib can also access data from HBase, Cassandra, Hive, and many other data sources.
5. GraphX
Apache Spark GraphX is a component of Spark architecture that is used for graph processing. GraphX can extend the Spark RDD that is immutable.
The following are some of the features of Apache Spark GraphX.
A. Flexible
Apache Spark GraphX effortlessly works with both graphs and collections by combining investigative analysis, iterative graph computation in one system. We can see the identical data collection as well as graphical format.
Following is an example of GraphX using Scala programming.
B. High Speed
GraphX strives for performance with the fastest graph systems and at the same time, it maintains Spark's flexibility, fault tolerance, and ease of use.
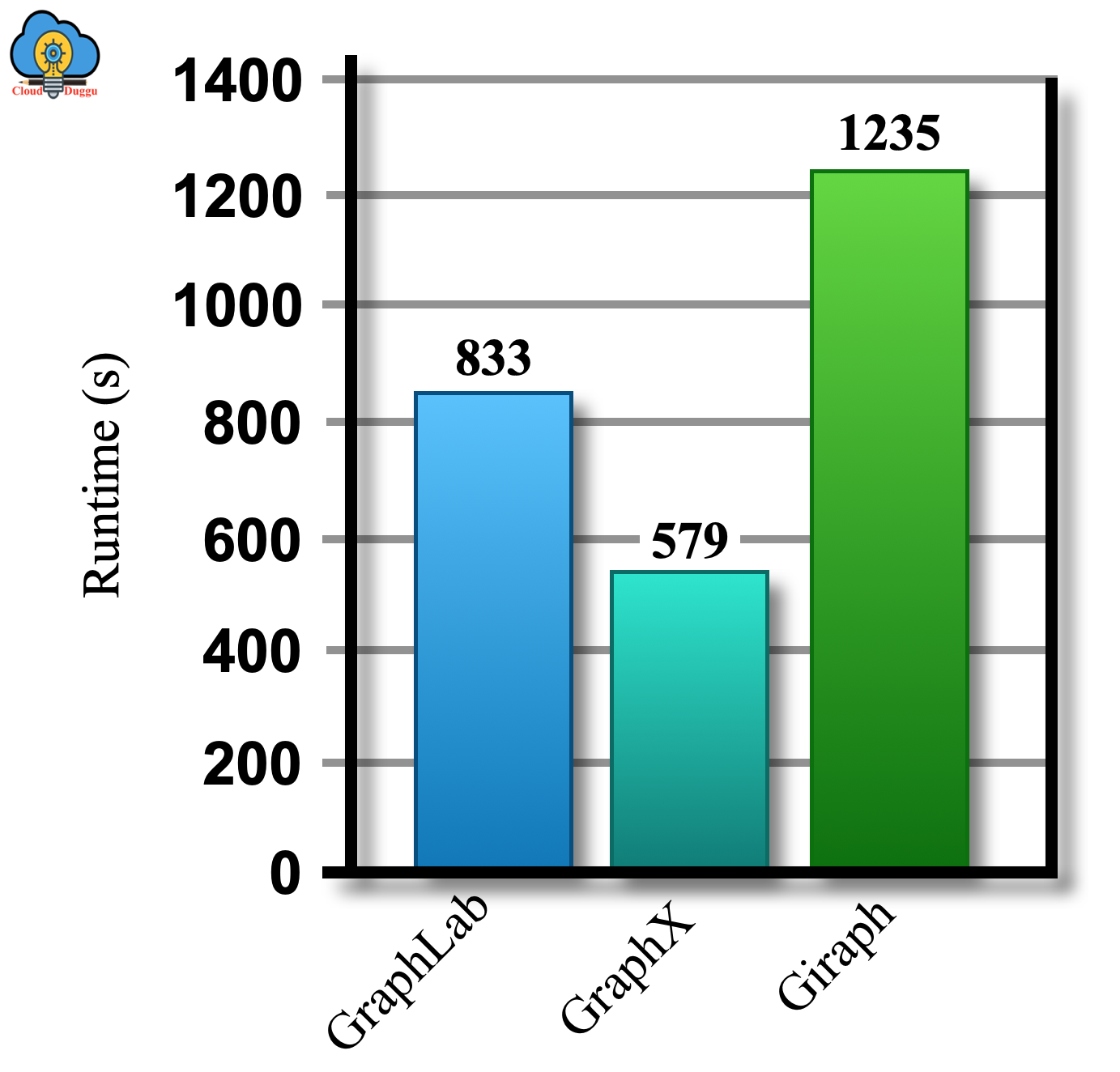
C. GraphX Algorithms
Apache Spark GraphX provides a rich set of graph algorithms to perform different kinds of operations.
The following are some of the Apache Spark GraphX algorithms.
- PageRank
- Connected components
- Label propagation
- SVD++
- Strongly connected components
- Triangle count
6. SparkR (R on Spark)
Apache SparkR is a Spark component to use R programming language with Spark. It supports different types of operations on data frames such as filtering, aggregation, selection, and so on.