What is Apache Spark Architecture?
Apache Spark is a centralized processing system that is used for extensive data processing. Spark provides such performance for batch as well as streaming data. It uses a DAG scheduler, a physical execution engine, and a query optimizer to achieve this. Spark allows high-level operators to create applications. Spark can be used from Python, Scala, R, and SQL.
Apache Spark provides a rich set of libraries which includes GraphX for graph processing, MLlib for machine learning, SQL for structure data processing and streaming. These libraries can be consolidated in an application. Spark can run on a standalone cluster mode such as Hadoop YARN, Kubernetes, EC2, Mesos, and so on. Spark can process data that is stored on Alluxio, HDFS, HBase, Hive, Cassandra, and many other sources.
Apache Spark has a layered architecture in which all components of Spark are lightly attached.
Apache Spark is based on two main concepts.
- Resilient Distributed Dataset (RDD)
- Directed Acyclic Graph (DAG)
Let us understand each concept.
RDD - Resilient Distributed Dataset
RDD stands for Resilient Distributed Dataset which is the main abstraction of Spark. RDD is a collection of elements that are partitioned across the nodes of the cluster and operated in parallel. RDD is automatically rebuilt upon failures and it can be persisted in memory. The basic operations performed on RDD are map, filters, and persist.
RDD Operations
There are two types of operations supported by RDD.
1. Transformations
2. Actions
Let us understand both operations.
1. Transformations
- It is a set of operations that define how RDD would be transformed.
- A new data set is created from an existing dataset.
- Example of Transformations are :- map(),filter(),flatMap() etc.
2. Actions
- Actions are the computation performed on the dataset. After computation, the output is returned to the driver program.
- Example of Actions are:- reduce(), collect(),count(),first() etc.
Apache Spark Execution And Architecture Workflow
Let us understand the Apache Spark Architecture execution using the below steps.
- When a user submits a Spark job then it runs as a driver program on the Master Node of Spark cluster.
- A driver program contains a Spark context that tells Spark about cluster access detail. SparkContext can be created by building a SparkConf object which has detail about the user’s application.
- Below lines of codes can be used to create a Spark context.
- Now spark context connect with the cluster manager for managing jobs.
- Spark context and driver program work together and take care of the jobs in the cluster.
- Now job divides into multiple tasks and gets distributed on slave nodes.
- Slave nodes are responsible for the execution of tasks on partitioned RDD and the result will be sent to Spark context.
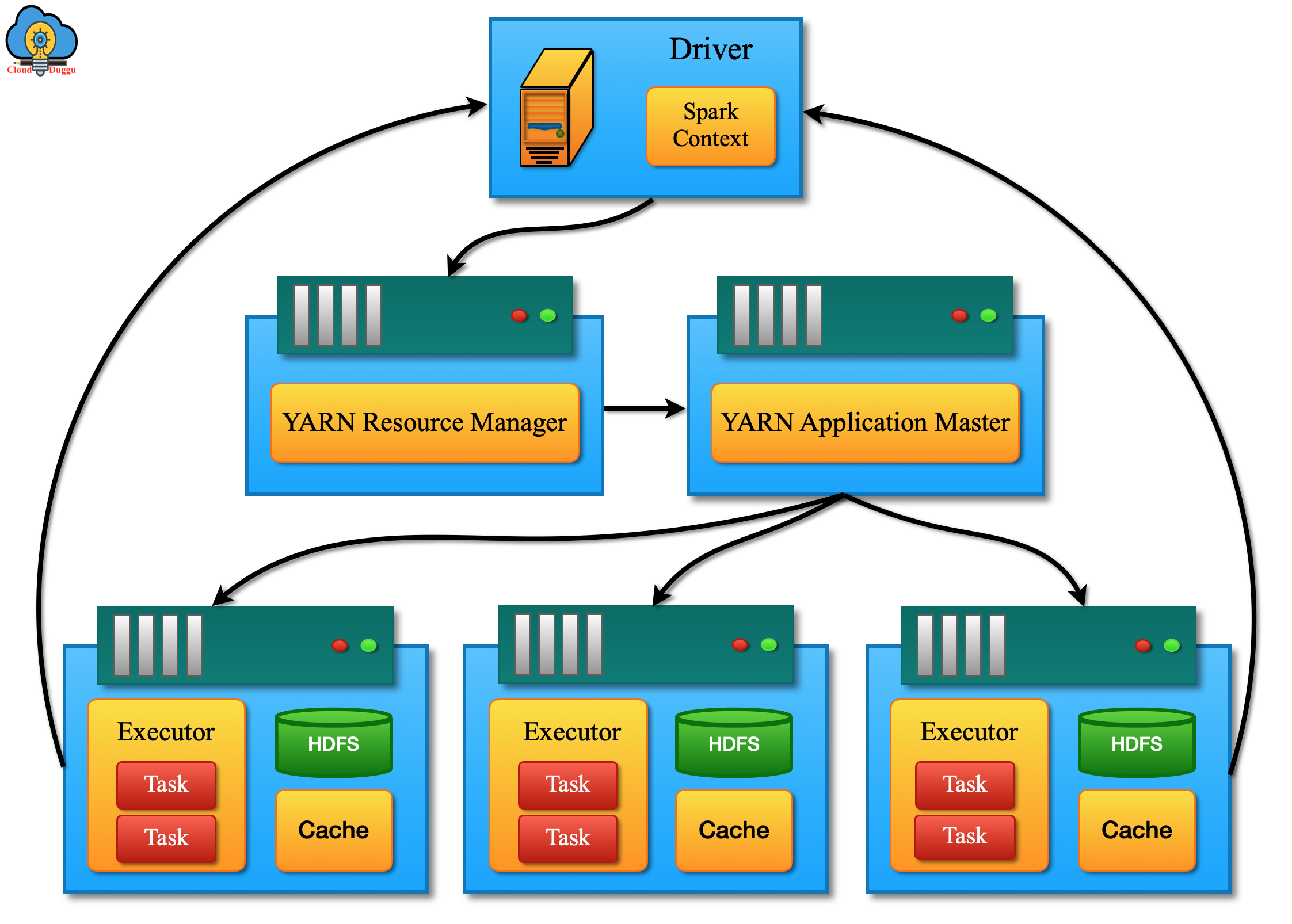
Let us understand the Apache Spark Architecture workflow.
- An application client submits a Spark code; post that driver will convert that code into a logical directed acyclic graph called DAG.
- Now logical directed acyclic graph will be converted into a physical execution plan and after converting it into a physical execution plan it creates physical execution units that are rushed and sent to cluster for execution.
- Now driver program asks for resources from the Cluster manager and the Cluster manager originates executors in worker nodes.
- Driver program will keep monitoring all execution tasks and after compilation of tasks, the result will be sent to Spark context.